
Overview of My Submission
Many of us have come across the tidy task of voice recording analysis, where you had to listen to the whole audio to identify the most essential parts.

Manual processing can be very time-inefficient. Just listening from end to end would often not be enough. You would have to double or even triple that time since you would have to pause and replay some parts of the audio.
During the mid-March to mid-April, I came up with VoiceCue, an app that generates cue timecodes that lets you find all the important parts of your voice recordings like sentiments, entities, and tags with just a click.
In this article, we will review it.
This project was built specifically as an entry for the DEV and Deepgram hackathon. It was an awesome experience since the participation motivated me and I came up with a product that could hopefully benefit others as well.
Submission Category
The root idea of the application comes from the world famous DJs in the music industry. Before the gigs they set cues for the audio tracks that they will play, marking the breakdown, drop, outro and so on. This way they can find specific parts quickly if they need to.
Thanks to Deepgram API I was able to implement my own cue system and pair it with the analysis of voice recordings. The cues are being generated for positive and negative sentiments, frequently used words, numerous entities, and actions as well as custom search queries.
I've never seen an AI-based cue tool for voice recordings, so I thought the perfect category for this would be Wacky Wildcards.
Link to Code: github.com/madzadev/voice-cue 🧑💻
Deployed app: cue.madza.dev 🎉
How does it work?
An audio cue is basically a shortcut that lets you jump to a predefined position in the audio.

The app workflow is as simple as uploading your voice recording, selecting which type of analysis to perform, and clicking on the generated cues in the list to instantly navigate to its exact position in the voice recording.
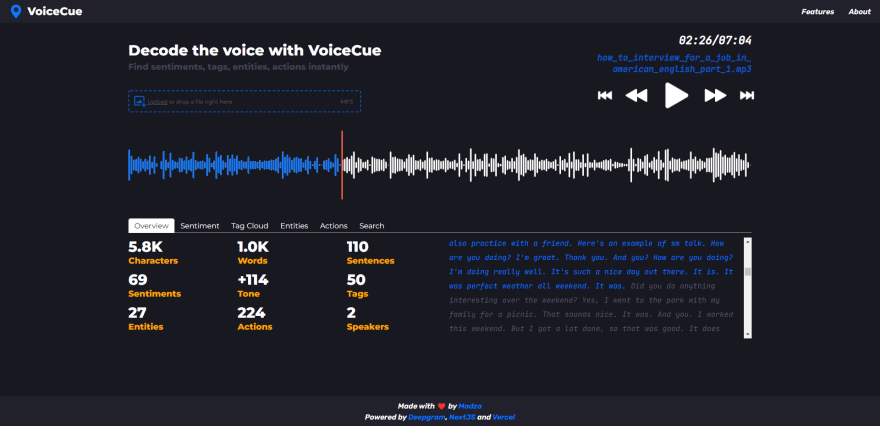
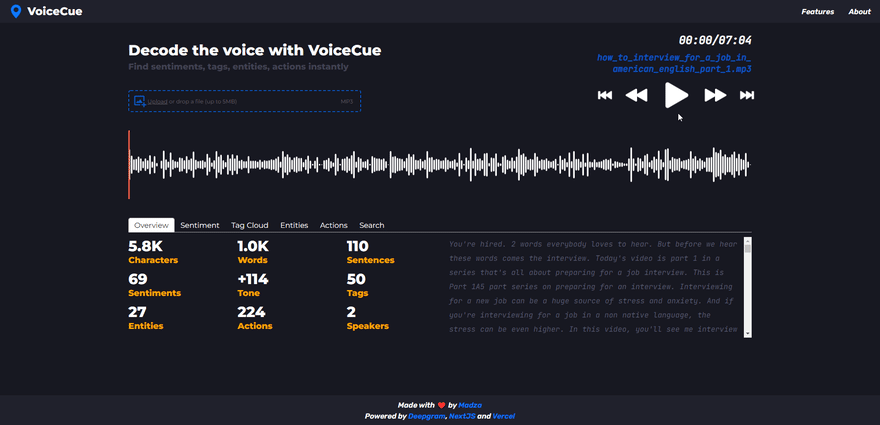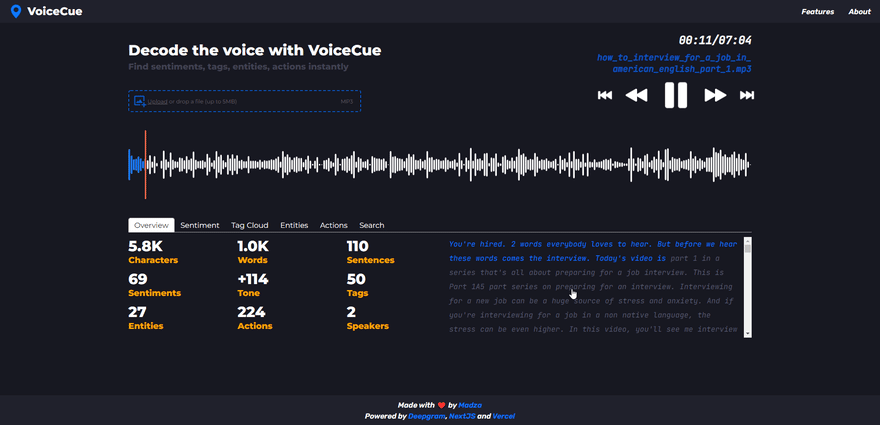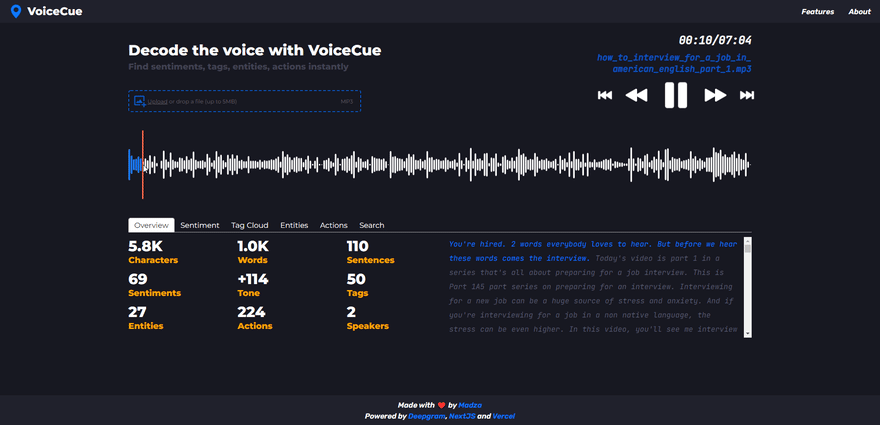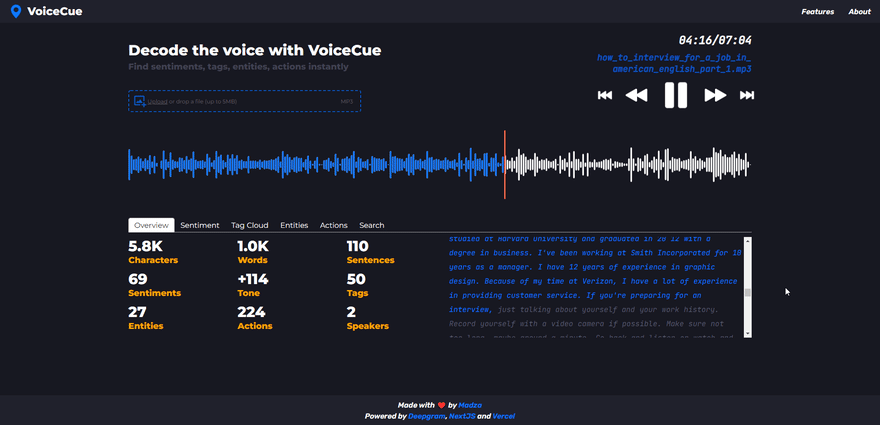
Overview and stats
Overview statistics gives an overall summary of the recording.
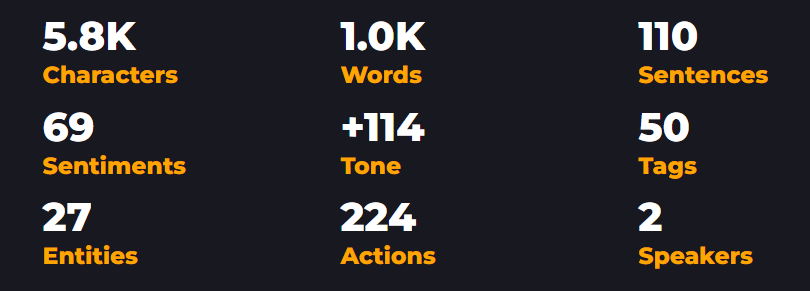
The analysis include: total characters, sentences and words, total identified sentiment cues and their cumulative tone score, as well as total identified tags, named entities, actions and speakers count in the voice recording.
Interactive transcript
The generated transcript is interactive, highlighting the words as they are heard in the voice recording. This feature makes it easier to track the current position in the overall context as well as increases accessibility for people with hearing problems.
Furthermore, user can click on any word on the transcript and the audio progress will be automatically set to the position of the word in the voice recording.
The audio waveform lets user visually perceive the dynamics of the voice and identify silences. For playback, the user can switch between audio controls and manually adjusting the progress marker on the waveform.
Sentiment analysis
Sentiment analysis checks against the words with positive and negative meanings.
After selecting the sentiment, the list of sentiment words is returned. The header shows the selected sentiment and how many words of that sentiment appeared in the voice recording.
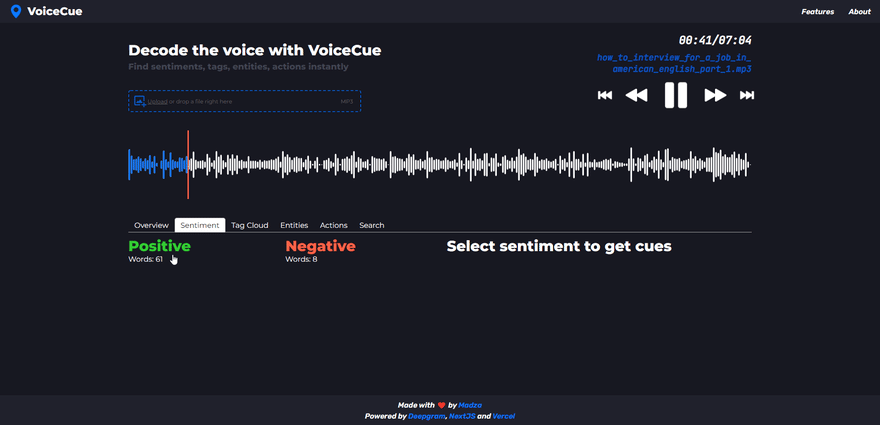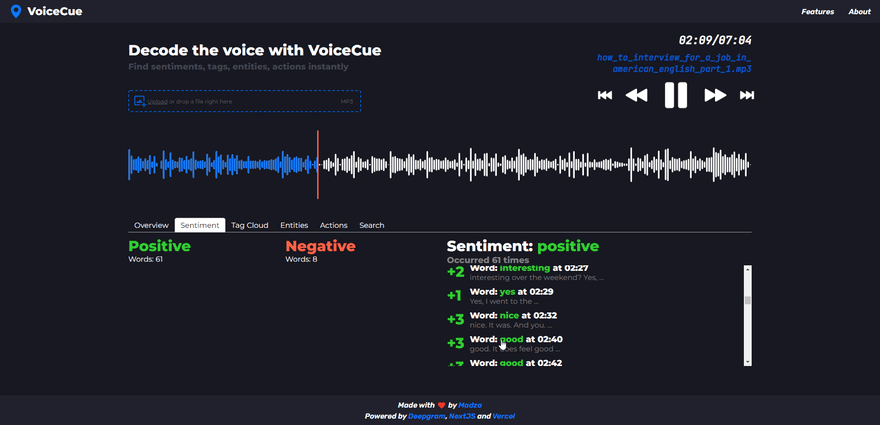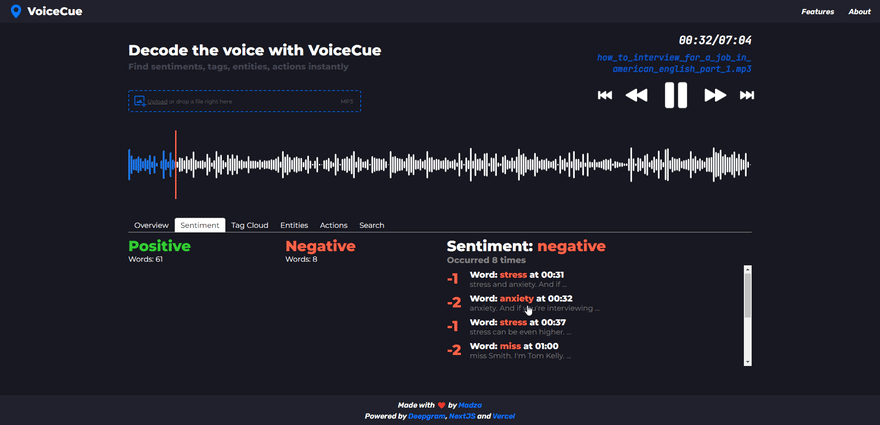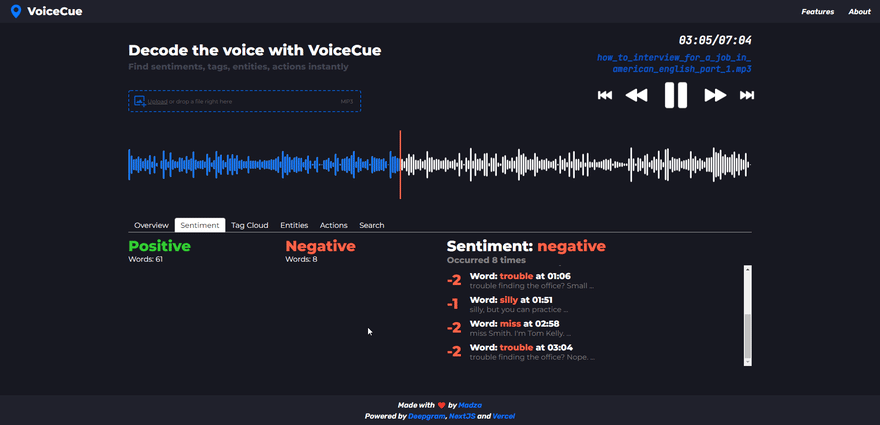
Each individual tag in the list displays the word, timecode, and its sentiment rank on the scale from -4 for the negative to +4 for the positive words.
There are various practical use cases for both. For example, the user might check the positive sentiment to compile a list of referrals for personal website. Or he/she might check the negative sentiment to get some feedback on what to improve on it.
Tag cloud
The tag cloud returns the most used words in the voice recording.
The higher the number of occurrences in the recording, the bigger the font size for the tag is used in the cloud. Also, a different color scheme is used for each tag so it is easier to distinguish.
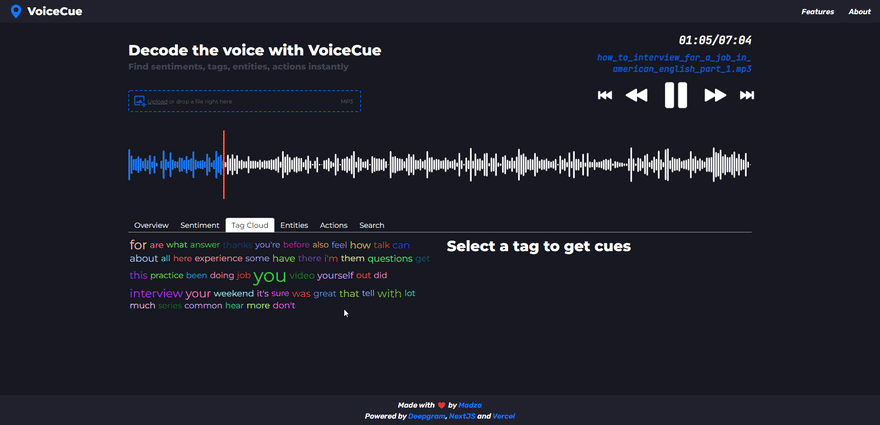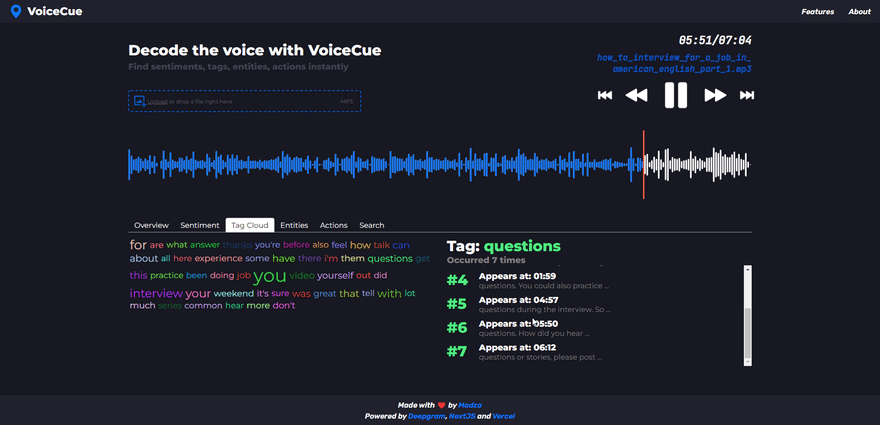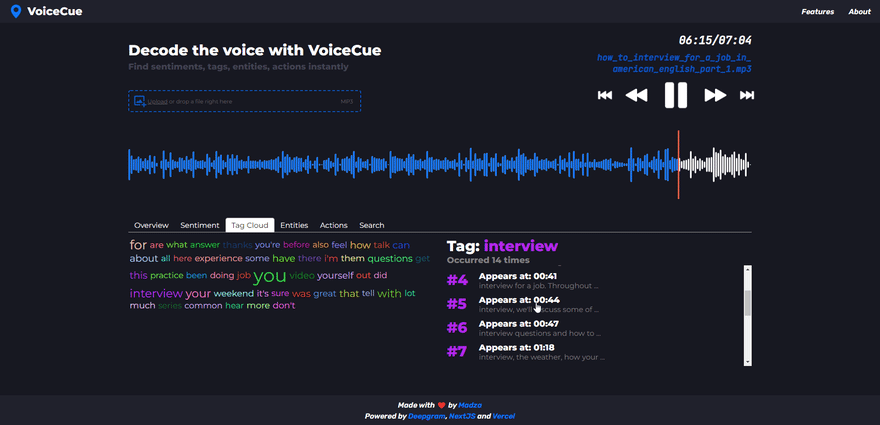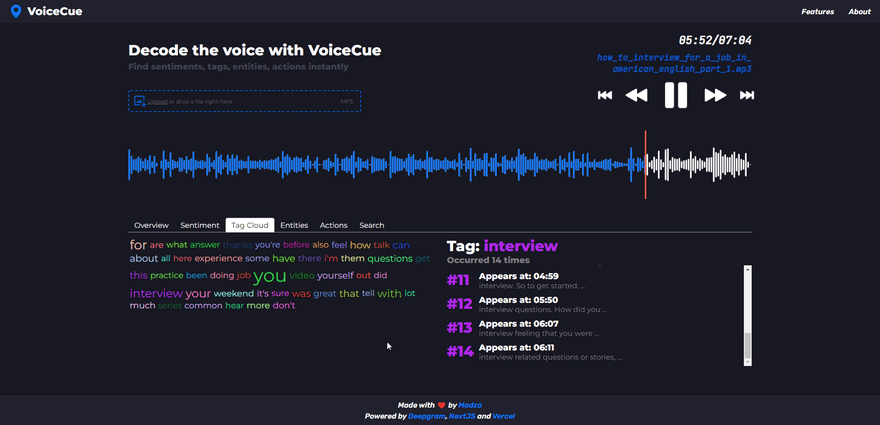
After a tag is selected the list header shows how many times the tag occurred throughout the recording. For individual cues, the sequence of appearance is shown along with the time code.
By looking at the word cloud it is easy to understand what were the main topics of the conversation. This could be very useful if someone wants to see what products or services are mentioned the most, for example.
Named entities
Named entity analysis lets you find cues based on word categorization.
Currently supported named entities are Person, Place, Organization, Money, Unit, and Date.
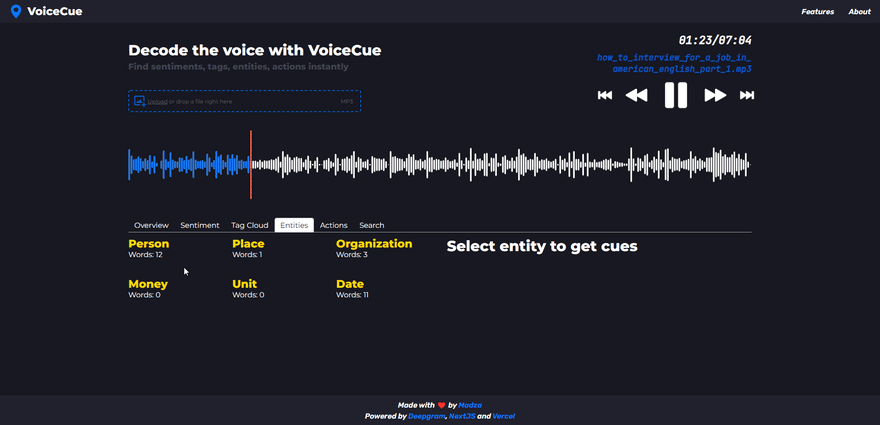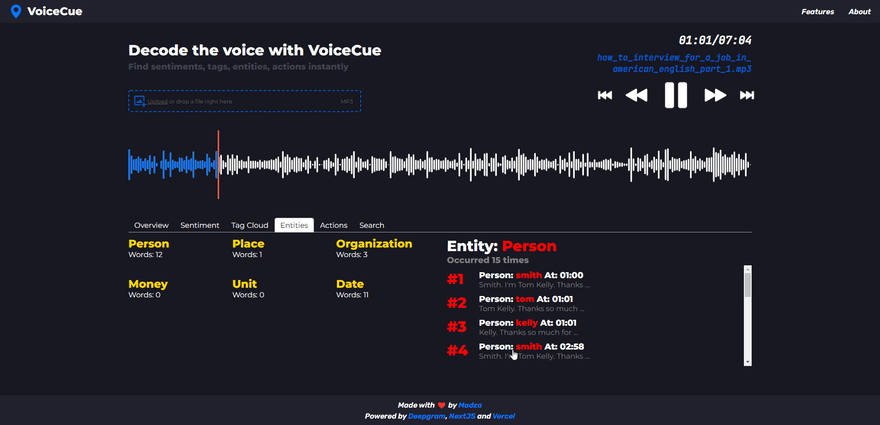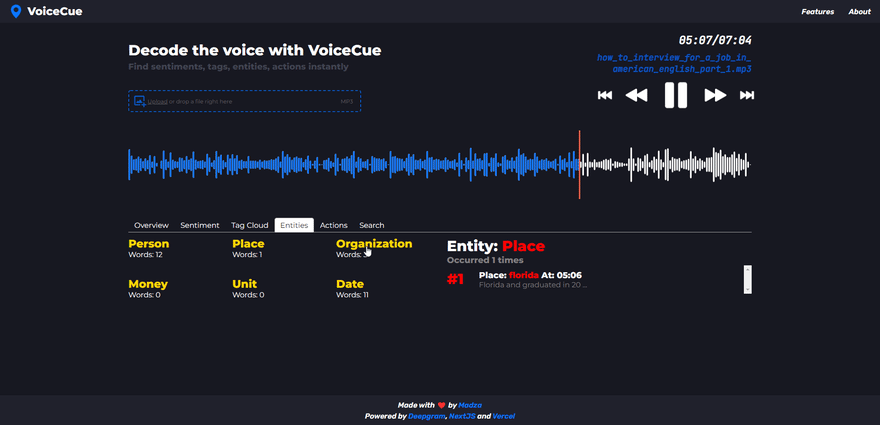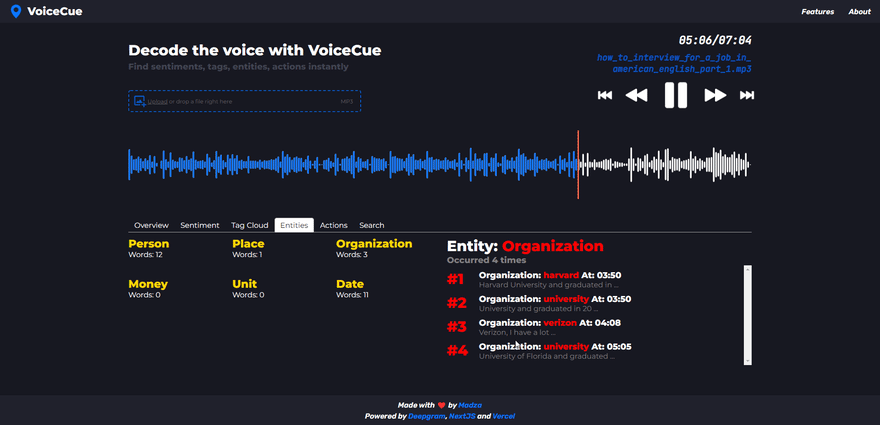
When a named entity is selected, the number of total occurrences on the recording is displayed in the header. Each individual generated cue represents the specific word of the entity, its sequence of appearance as well as the timecode.
Named entities can be very useful. For example, a company would check for a Person entity to quickly generate timecodes for the mentions of board members in the recording. Or search for Money entity to quickly jump to where the company budget is mentioned.
Actions
Actions analysis returns the verbs, by categorizing them into past, present, and future. Currently supported categories are PastTense, Infinitive, Copula, Modal, and Gerund.
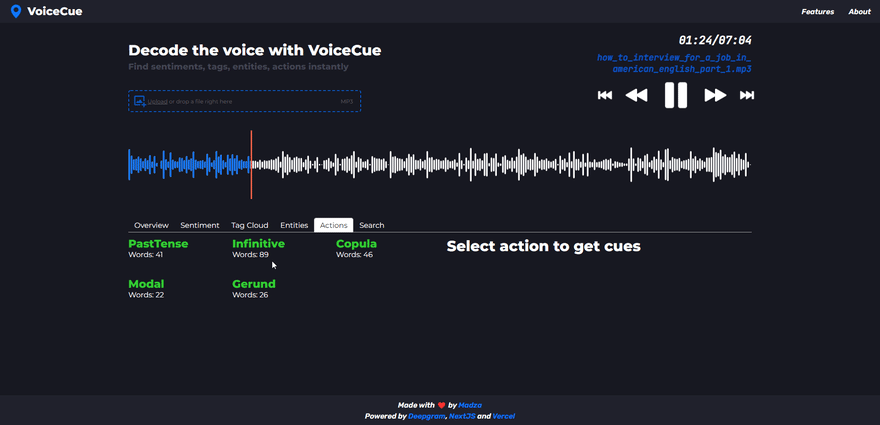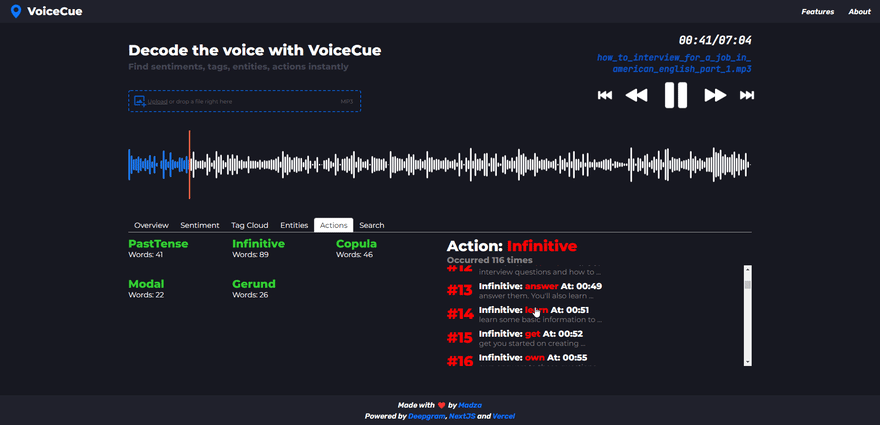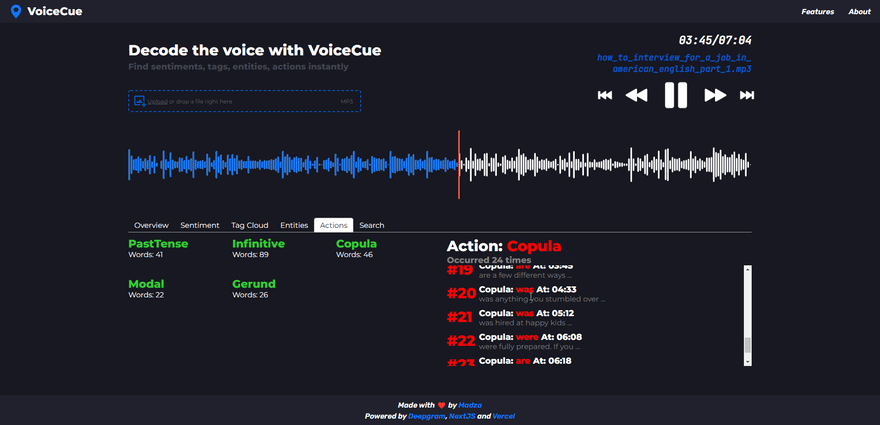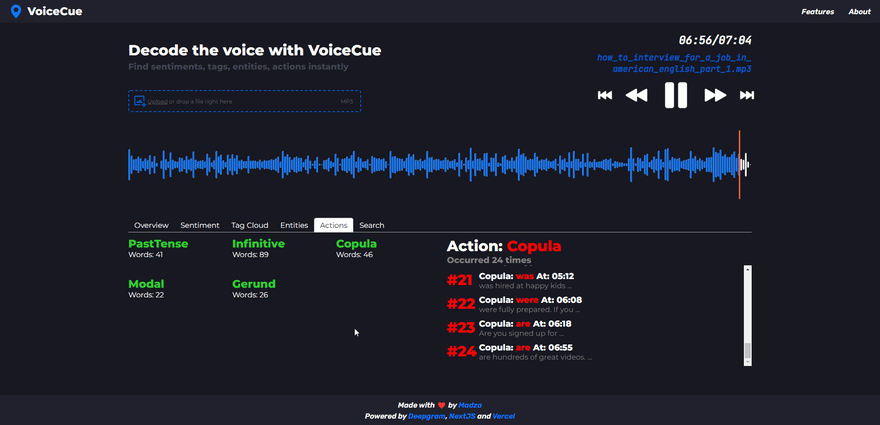
Similar to named entities, once the action is selected, it is displayed on the list header with the number of total occurrences on the recording. Each individual generated cue represents the specific word of the action, its sequence of appearance as well as the time code.
Thanks to the categorization by the tense, action cues can be practically used if someone wants to find information about topics such as accomplished milestones, current processes, or planned tasks for the future.
Custom search
If you were not able to find the cue you were looking for via any of the previous analysis methods, there is a custom search that let you search for custom words as well.
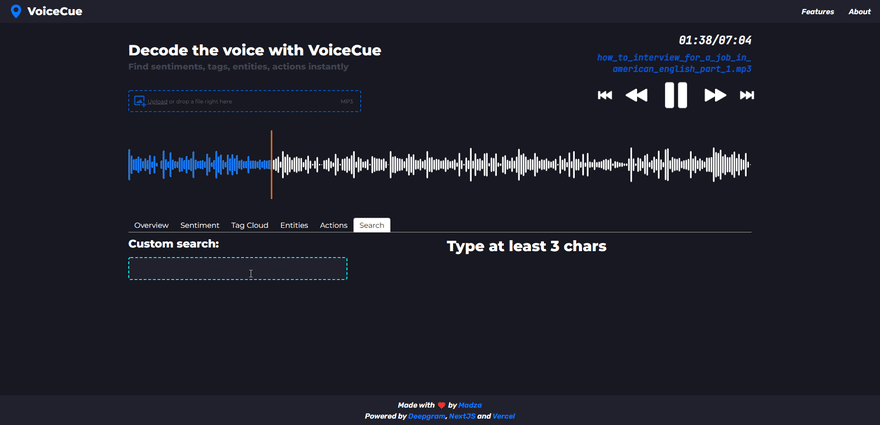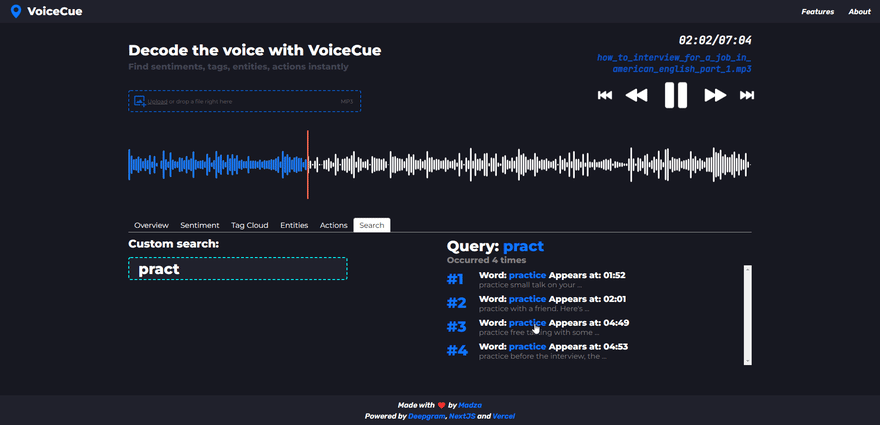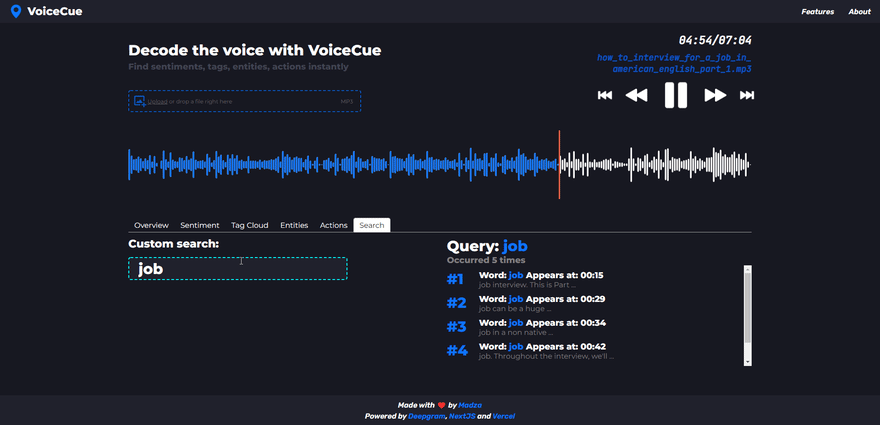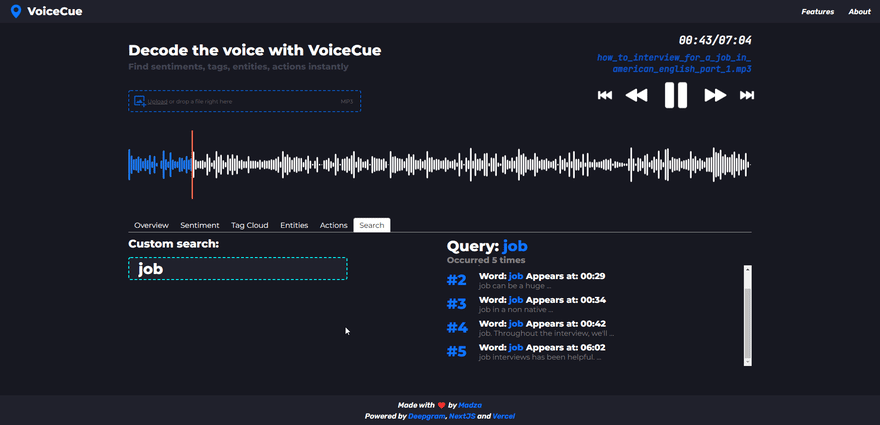
The user is required to enter at least 3 characters to generate the list of cues. If the search query returns multiple cues, all are displayed below each other, with the word that includes the query, its sequence number, and timecode.
Responsiveness
In our daily lives, we usually use phones to interview someone or record a meeting or event. Therefore making the app fully responsive to different screen widths was among the main priorities.
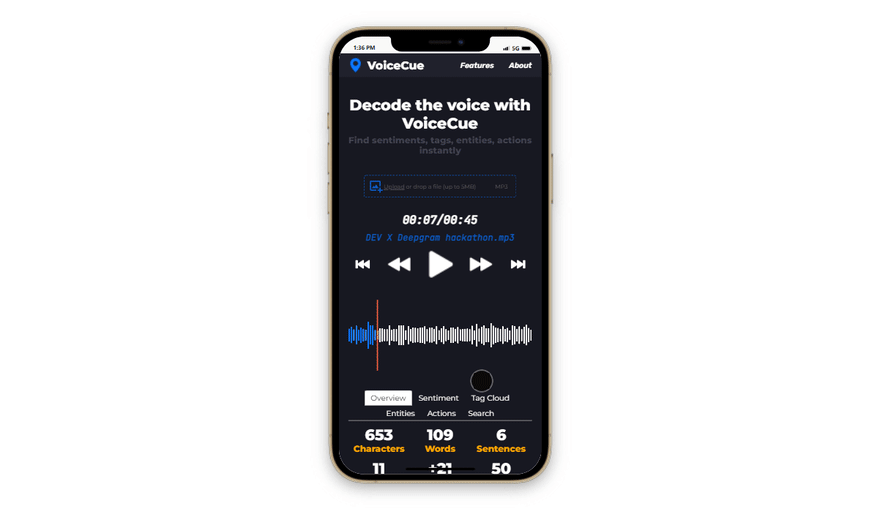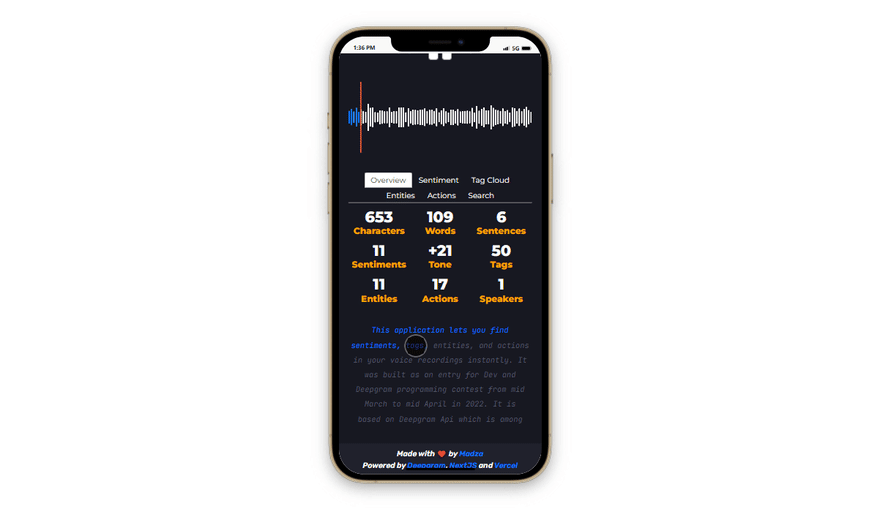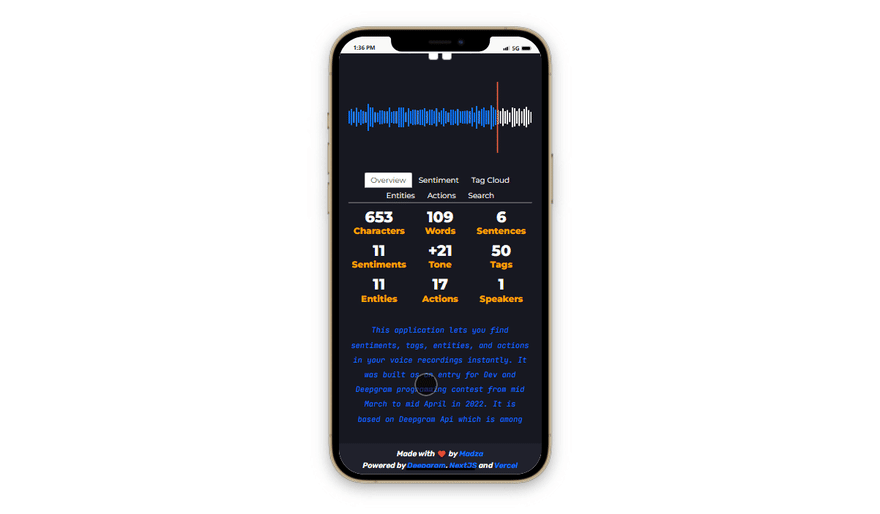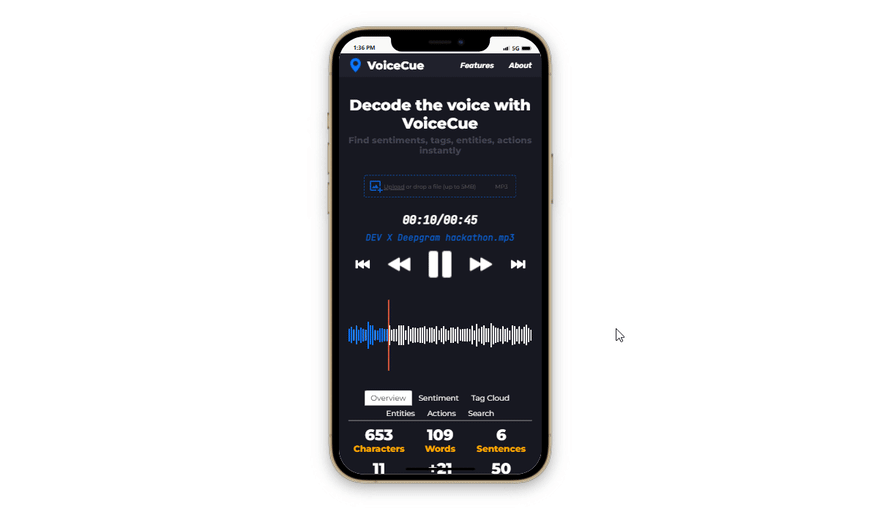
Since all the features are supported on smaller screens as well, the application is ready to be used in every situation, anytime you have a device with you.
Features list:
Voice recognition - based on the Deepgram API
General stats - an overview of voice recording
Sentiment analysis - positive and negative word detection
Word cloud generation - most used word classification
Entity name recognition - categories such as person, place, etc
Activity tracking - find actions in past, present, or future
Interactive transcript - see progress or click to control it
Speaker detection - total number of speakers in recording
Cue word usage - short text samples for better context
Custom search - extended ability to query for cues
Waveform preview - see the dynamics of voice, identify silences
Audio controls - play, pause, fast forward, and backward
Drag and drop support - drop audio in the file select area
Upload MP3 files - the most commonly used audio format
Progress loaders - improved UX for loading transcripts
Fully responsive - works fine on mobile and tablets
Colorful UI - for easier interaction and word highlighting
Tech stack
NextJS - React application framework
Deepgram - for AI-based speech recognition
compromise, sentiment - for text processing
react-tagcloud - to generate word cloud
react-tabs - for navigation panels
react-drag-drop-files - for drag and drop support
wavesurfer.js - to generate the audio waveform
GitHub - to host the code
Vercel - to deploy the project
ESLint, prettier - for linting and code formatting
Namecheap - for custom subdomain
Conclusion
I want to thank Forem for providing a great platform to learn, share findings, and engage with awesome people. Visiting DEV daily has become a habit of mine for years and I have already published 300+ posts.
It was my pleasure to discover Deepgram, a co-host for this hackathon providing their API to build awesome stuff with. From now on I will have a valuable tool in my pocket that I will already know how to use when I will have to deal with speech recognition projects.
The voice is an instrument of communication, lots of valuable information is being transferred with it every second. The powerful API of Deepgram is a wide step toward working smart, not hard, which will become an even more crucial skill to beat the competition in the future.
Building projects have always been my passion and it gives me pleasure to help and inspire people. If you have any questions, feel free to reach out!
Connect me on Twitter, LinkedIn and GitHub!
Visit my Portfolio for more projects like this.

Top comments (8)
This blows my mind, Madza! 👏🏼
I love the feature of finding word in the speech! 🤩
Thanks a lot Ayu! ❤️👍
Practical usability was an important for me for the end project, so happy to see you found a useful feature 💯✨
This is amazing! and that is one great list of features!
You are awesome, SVGator 🤩 Thanks for continuous support 👍
Hahah, yeah I guess I got a bit carried away 😄😄 Audio projects have always been special to me, been a music producer myself for nearly a decade and their API was just so damn great 💯✨
😲😳!!! Congratulations 🎉! Really good! It's for sure a help for audio analysis 👏
This means so much, thanks a lot! 🙏❤️
This is really cool.
Thank you so much, cheered up my evening 👍✨