
When I was a young man,
I had liberty but I didn’t see it,
I had time but I didn’t know it,
And I had PyTorch Lightning but I didn't use it.
- Newbie PyTorch User
Another Blog another great video game quote butchered by these hands. Anyways, when I was getting started with PyTorch one of the things that made me jealous was the fact that Tensorflow has so much support for monitoring the model performance. I mean I have to write a training loop with redundant steps while Tensorflow beginners were just passing and chilling.
So I did what most PyTorch newbies did, learned and wrote the training loop code until it became muscle memory and that is something you shouldn't do. Few tips for that is just understanding why each step works and once you do that every line of code starts to make sense, trust me once I did that I never forgot it again.
Back to the topic, one thing that I love about PyTorch is the extent to which I can customize it and how easy it is to debug. But still, it would be better if somehow I was able to keep those features and reduce the redundancy.

Well there you have it, the solution is PyTorch Lightning I mean anyone with such a cool name is already destined for greatness but if that reason doesn't convince you then I hope that by the end of this article you will be.
P.S. it's actually better if you have some basic idea about Lightning. If you wanna learn its basics try this article I wrote a while back on Training Neural Networks using PyTorch Lighting.
Datasets, DataLoaders and DataModule
There are two things that give me immense satisfaction in life, first is watching a newbie Vim user trying to exit Vim, and the second is watching a newbie PyTorch user trying to create Dataloader for custom data. So let's take a look at how you can create DataLoaders in PyTorch using an awesome utility called Dataset.
The Dataset Class
One of the things that is essential if you are learning PyTorch is how to create DataLoaders there are many ways to go for it I mean for Image you have ImageFolder utility in torchvision and for Text Data we have BucketIterator which I won't lie are quite handy but still what if the data you load isn't in the desired format? In that case, you can use the Dataset class, and not just that the thing that I love about Dataset class is that they are customizable to an extent you can't imagine.
In Dataset class you have 3 main functions that you must define, let's take a look at them:-
init(self, *): The constructor function. there are infinite possibilities of things you can do here. Think of it as the staging area of our data. Usually, you pass either a path, a dataframe, or an array as the argument to this class's instance. Here you usually define class attributes like feature matrix and target vector. If you are working with an image you can assign transform variable, if you are working with the text you can assign a tokenizer variable etc.
len(self): The length function. this is where you'll return the length of the dataset, you basically return the length of the feature matrix or the dataset in whatever format you have.
getitem(self, idx): The fetching function. This is the function where you define how your data will be returned. You can apply various preprocessing to be applied on the data of at idx index here and then return its tensor along with other variables like mask or target by packing them in a list, tuple, dict, etc. I used to pack them in a list but when I saw Abhishek Thakur's video on this I started using dicts and I never looked back since that day.
The guy is a PyTorch madlad go watch his videos if you haven't already brilliant and to-the-point hands-on videos on many interesting topics. Let's keep all that aside for now and take an example, shall we? I'll be using make_classification to create the dataset to keep things simple.
import torch
from sklearn.datasets import make_classification
from torch.utils.data import Dataset
class TabularData(Dataset):
def __init__(self, X, Y, train = True):
self.X = X
self.Y = Y
def __len__(self):
return len(self.X)
def __getitem__(self, idx):
features = self.X[idx]
if self.Y is not None:
target = self.Y[idx]
return {
'X' : torch.tensor(features, dtype = torch.float32),
'Y' : torch.tensor(target, dtype = torch.long)
}
else:
return {
'X' : torch.tensor(features, dtype = torch.float32)
}
X, Y = make_classification()
train_data = TabularData(X, Y)
train_data[0]
Output:-
{'X': tensor([ 1.1018, -0.0042, 2.1382, -0.7926, -0.6016, 1.5499, -0.4010, 0.3327,
0.1973, -1.3655, 0.4870, 0.7568, -0.7460, -0.8977, 0.1395, 0.0814,
-1.4849, -0.2000, 1.2643, 0.4178]), 'Y': tensor(1)}
Subarashi! That seems to be working correctly you can try and experiment with what happens if you change the output of the classes a bit and check the results. But for this tutorial, we'll be working on Fashion MNIST data and thankfully in torchvision there already is a dataset for that so let's load that.
from torchvision import datasets, transforms
transform = transforms.Compose([
transforms.ToTensor()
])
train = datasets.FashionMNIST('',train = True, download = True, transform=transform)
test = datasets.FashionMNIST('',train = False, download = True, transform=transform)
Now that we have the data it's time to move onto DataLoaders.
DataLoaders
DataLoaders are responsible to take input a dataset and then pack the data in them into batches and create an iterator to iterate over these batches. They really make the whole batching process easier while keeps the customizability to the fullest. I mean you can define how to batch your data by writing your own collate_fn, what more do you want?
We saw how we can create a dataset class, to create its DataLoader you just pass that Dataset instance to the DataLoader and you are done. Let's see how to do it for the MNIST dataset that we created above and check it's output.
import matplotlib.pyplot as plt
from torch.utils.data import DataLoader
trainloader = DataLoader(train, batch_size= 32, shuffle=True)
testloader = DataLoader(test, batch_size= 32, shuffle=True)
#Plotting a Batch of DataLoader
images, labels = iter(trainloader).next()
plt.figure(figsize = (12,16))
for e,(img, lbl) in enumerate(zip(images, labels)):
plt.subplot(8,4,e+1)
plt.imshow(img[0])
plt.title(f'Class: {lbl.item()}')
plt.subplots_adjust(hspace=0.6)
Output:-

Damn, that looks beautiful and correct, well there you go seems like our DataLoaders work as expected. But is it just me or does this seem too messy? I mean it's great we batched the data but the variables seem to be everywhere, it doesn't seem much organized. Well, that's basically where DataModules come in handy 😎.
DataModules
DataModule is a reusable and shareable class that encapsulates the DataLoaders along with the steps required to process data. Creating DataLoaders can get messy that’s why it’s better to club the dataset in the form of DataModule. DataModule has few methods that must define the format of DataModule is as follows:-
import pytorch-lightning as pl
class DataModuleClass(pl.LightningDataModule):
def __init__(self):
# Define class attributs here
def prepare_data(self):
# Define steps that should be done
# on only one GPU, like getting data.
def setup(self, stage=None):
# Define steps that should be done on
# every GPU, like splitting data, applying
# transform etc.
def train_dataloader(self):
# Stage DataLoader for Training Data
def val_dataloader(self):
# Stage DataLoader for Validation Data
def test_dataloader(self):
# Stage DataLoader for Testing Data
That seems great so let's go ahead and create DataModule for our Fashion MNIST Data.
import pytorch_lightning as pl
class DataModuleFashionMNIST(pl.LightningDataModule):
def __init__(self):
super().__init__()
self.dir = ''
self.batch_size = 32
self.transform = transforms.Compose([
transforms.ToTensor()
])
def prepare_data(self):
datasets.FashionMNIST(self.dir, train = True, download = True)
datasets.FashionMNIST(self.dir, train = False, download = True)
def setup(self, stage=None):
data = datasets.FashionMNIST(self.dir,
train = True,
transform = self.transform)
self.train, self.valid = random_split(data, [52000, 8000])
self.test = datasets.FashionMNIST(self.download_dir,
train = False,
transform = self.transform)
def train_dataloader(self):
return DataLoader(self.train, batch_size = self.batch_size)
def val_dataloader(self):
return DataLoader(self.valid, batch_size = self.batch_size)
def test_dataloader(self):
return DataLoader(self.test_data, batch_size = self.batch_size)
data = DataModuleFashionMNIST()
Perfect that's basically it but if you want an in-depth explanation on them you can refer this article I wrote explaining about DataModules.
Lightning Callbacks & Hooks
Callbacks are basically programs that contain code that's run when it is required. When and what a callback should do is defined by using Callback Hooks, a few of them are on_epoch_end, on_validation_epoch_end, etc. You can maybe define a logic to monitor a metric, save a model, or various other cool stuff. If I have to define callbacks as a meme it'll be the following.

Well necessary for training but useful for other stuff. There are many inbuilt callbacks that can be used for various important tasks. A few of them are:-
| CallBack | Description |
|---|---|
| EarlyStopping | Monitor a metric and stop training when it stops improving. |
| LearningRateMonitor | Automatically monitors and logs learning rate for learning rate schedulers during training. |
| ModelCheckpoint | Save the model periodically by monitoring a quantity. |
| Callback | Base Class to define custom callbacks. |
| LambdaCallback | Basically Lambda Function of Callbacks. |
We'll be using the first two for this article but you can refer to docs to learn more about them. Lightning's video tutorials on their website are pretty good.
TPU - Hulkified GPU?
TPUs are accelerators used to speed up Machine Learning Tasks. The catch is that they are platform dependant i.e. TensorFlow. TPUs are optimized for Tensorflow mainly which I think is quite selfish given PyTorch is so awesome.

But we can actually use them in PyTorch by making and passing a TPU Sampler in the DataLoader. It's one hell of a messy task you have to replace the device type with xm.xla_device() and add 2 extra steps for optimizer and not just that you'll have to install PyTorch/XLA to do all that. It goes something like this:-
import torch_xla.core.xla_model as xm
dev = xm.xla_device()
# TPU sampler
data_sampler = torch.utils.data.distributed.DistributedSampler(
dataset,
num_replicas=xm.xrt_world_size(),
rank=xm.get_ordinal())
dataloader = DataLoader(dataset, batch_size=32, sampler = data_sampler)
# Training loop
for batch in dataloader:
...
xm.optimizer_step(optimizer)
xm.mark_step()
...
Man the above code is a mess but in Lightning all that is reduced to a simple single line. All you need to do is pass the number of tpu_cores to be you and you are done for the day. Really it's that simple.
trainer = pl.Trainer(tpu_cores = 1)
trainer.fit(model)
I mean it literally couldn't get any simpler than this but still, there is one more thing that's left to talk about and that is Loggers. Let's take a look at that.
Loggers
Loggers are a kind of utility that you can use to monitor metrics and hyperparameters and much more cool stuff. In fact you probably already have tried one, Tensorboard. Ever heard of it? If you are here chances are you might have. Along with Tensorboard, PyTorch Lightning supports various 3rd party loggers from Weights and Biases, Comet.ml, MlFlow, etc.
In fact, in Lightning, you can use multiple loggers together. To use a logger you can create its instance and pass it in Trainer Class under logger parameter individually or as a list of loggers.
from pytorch_lightning.loggers import WandbLogger
# Single Logger
wandb_logger = WandbLogger(project='Fashion MNIST', log_model='all')
trainer = Trainer(logger=wandb_logger)
# Multiple Loggers
from pytorch_lightning.loggers import TensorBoardLogger
tb_logger = TensorBoardLogger('tb_logs', name='my_model')
trainer = Trainer(logger=[wandb_logger, tb_logger])
The point is how to log the values? We'll take a look at how you can do that along with applying all the stuff I talked about above.
Putting it All Together
The Ingredient to a model is the data that you feed it, we talked about DataModules in this article so let's start by creating a DataModule for out Fashion MNIST data.
import pytorch_lightning as pl
from torchvision import datasets, transforms
class DataModuleFashionMNIST(pl.LightningDataModule):
def __init__(self, batch_size = 32):
super().__init__()
self.dir = ''
self.batch_size = batch_size
self.transform = transforms.Compose([
transforms.ToTensor()
])
def prepare_data(self):
datasets.FashionMNIST(self.dir, train = True, download = True)
datasets.FashionMNIST(self.dir, train = False, download = True)
def setup(self, stage=None):
data = datasets.FashionMNIST(self.dir,
train = True,
transform = self.transform)
self.train, self.valid = random_split(data, [52000, 8000])
self.test = datasets.FashionMNIST(self.download_dir,
train = False,
transform = self.transform)
def train_dataloader(self):
return DataLoader(self.train, batch_size = self.batch_size)
def val_dataloader(self):
return DataLoader(self.valid, batch_size = self.batch_size)
def test_dataloader(self):
return DataLoader(self.test_data, batch_size = self.batch_size)
data = DataModuleFashionMNIST()
Now let's create our model class and setup logs for the WandbLogger and then create a model instance for the same.
from torch import nn, optim
import torch.nn.functional as F
class FashionMNISTModel(pl.LightningModule):
def __init__(self):
super().__init__()
# 28 * 28 * 3
self.conv1 = nn.Conv2d(1,16, stride = 1, padding = 1, kernel_size = 3)
# 14 * 14 * 16
self.conv2 = nn.Conv2d(16,32, stride = 1, padding = 1, kernel_size = 3)
# 7 * 7 * 32
self.conv3 = nn.Conv2d(32,64, stride = 1, padding = 1, kernel_size = 3)
# 3 * 3 * 64
self.fc1 = nn.Linear(3*3*64,128)
self.fc2 = nn.Linear(128,64)
self.out = nn.Linear(64,10)
self.pool = nn.MaxPool2d(2,2)
self.loss = nn.CrossEntropyLoss()
def forward(self,x):
x = F.relu(self.pool(self.conv1(x)))
x = F.relu(self.pool(self.conv2(x)))
x = F.relu(self.pool(self.conv3(x)))
batch_size, _, _, _ = x.size()
x = x.view(batch_size,-1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
return self.out(x)
def configure_optimizers(self):
return optim.Adam(self.parameters())
def training_step(self, train_batch, batch_idx):
x, y = train_batch
logits = self.forward(x)
loss = self.loss(logits,y)
# Logging the loss
self.log('train/loss', loss, on_epoch=True)
return loss
def validation_step(self, valid_batch, batch_idx):
x, y = valid_batch
logits = self.forward(x)
loss = self.loss(logits,y)
# Logging the loss
self.log('valid/loss', loss, on_epoch=True)
return loss
As you can see in the above code we are using self.log() to log our loss values for which chart will be generated. Now let's create our logger and fit our trainer.
from pytorch_lightning.loggers import WandbLogger
model = FashionMNISTModel()
wandb_logger = WandbLogger(project='Fashion MNIST', log_model='all')
trainer = pl.Trainer(max_epochs=10, tpu_cores = 1, logger = wandb_logger)
wandb_logger.watch(model)
trainer.fit(model, data)
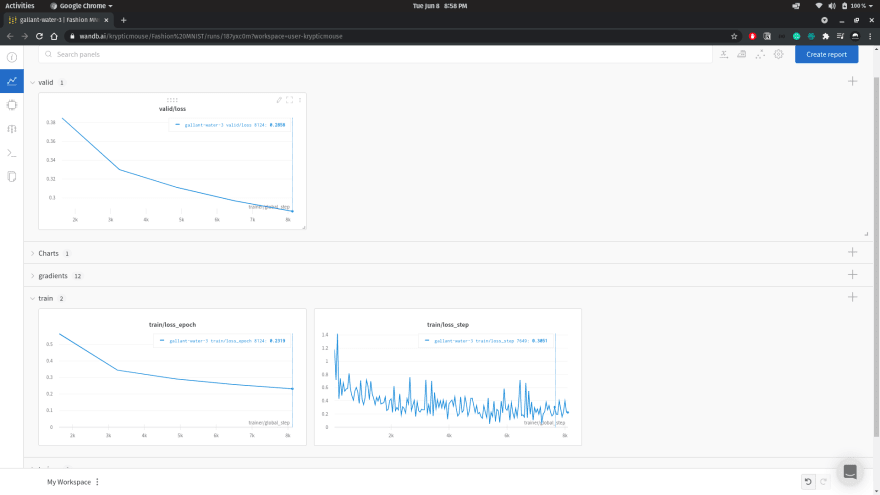
Once you run the above code the logs will be plotted in runtime. I am plotting loss values using the self.log() and logging gradients using watch().
If you get MisconfigurationException: No TPU devices were found. then run the following command to fix it.
%%capture
!curl https://raw.githubusercontent.com/pytorch/xla/master/contrib/scripts/env-setup.py -o pytorch-xla-env-setup.py > /dev/null
!python pytorch-xla-env-setup.py --version nightly --apt-packages libomp5 libopenblas-dev > /dev/null
!pip install pytorch-lightning > /dev/null
Since the model is extremely simple I didn't use any callbacks but you can use if you like. In Learning Rate Monitor Callback you need to have a scheduler to make it work and pass the Model Checkpoint Callback in checkpoint_callback instead of callback.
From Me to You...
Wow, that seemed like an exciting ride. Honestly, I think Lightning has many cool stuff that a person can utilize the fact that we can use all these while keeping it as close to PyTorch proves how powerful it is. I hope now you are convinced that Lightning is a great tool to be learned and used.





Top comments (1)
Awesome post keep up the great work!