What Is Data Science Process?
We have previously seen what data is, we have talked about the field of data science and how it is influenced by mathematics and statistics. Now we will see what is data science processes.
So, in basic terms, the data process consists of a series of steps and operations. It is more like a cycle following consecutive steps that define the steps that start from data collection, storage of data, organizing data and last up to analysis and presentation of data. These steps ease the entire process of handling the data from the time it arrives to the time it is transformed into insights.
Why Do We Need A Data Science Process?
Let me rephrase that, why do we not need a data science process? After all, following meaningful steps and procedures in any manner can improve our efficiency and productivity. This cycle ensures that we customize the data and convert it to a higher quality state for further dealing with the data. This can effectively save time for the current team working on the data, all the time spent while cleaning the data can be spent on extracting insights from the data. These steps not only increase the current team's productivity but can also ease the work for any future team. As an addition, it also improves accuracy and reliability of data.
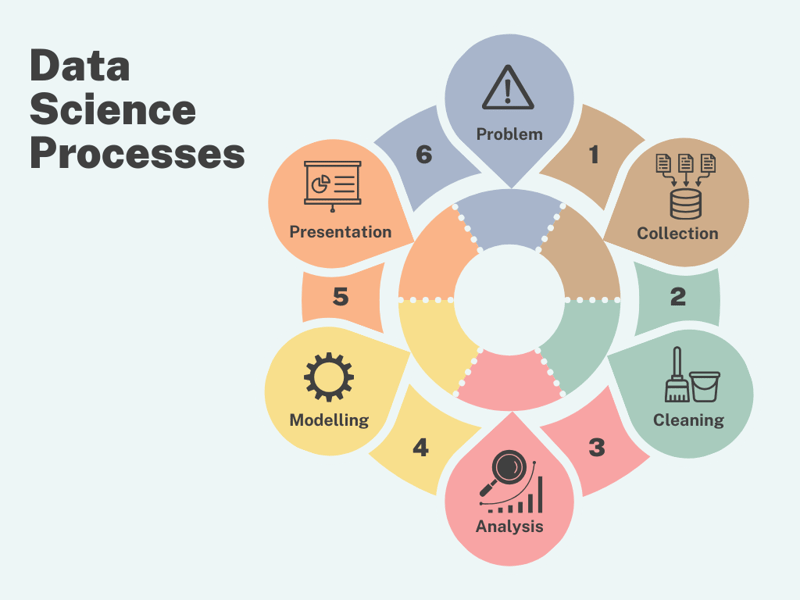
Step 1: Problem Identification

The very first step is to identify the problem you have been assigned or that needs to be solved. You need to ensure that you have clearly defined the problem in hand, for that you need to take every aspect of the problem and analyze it critically, ensuring that any solution you come up with is the best and optimal solution for that problem. Identify the key questions that have to be answered, and understand the what, why, and how of the problem.
A better approach towards this step would also include a side step, when identifying the problem a good data scientist can also define what is expected from his team and his organization while working and presenting the solution.
Identify the project goals, tasks, costs, and deadlines. It is best to start the project when one clearly understands every dimension of the problem as this can serve as a guide to even the team.

Step 2: Data Collection And Exploration
Once the problem has been defined, the next step is to collect the relevant data needed for analysis.
The data is provided by the organization, other times the data has to be collected by the team itself. A data scientist must look for data sources, either through data available publicly (Open Data), either from government sites or through organizations' databases.
Only collecting the data is not enough, one must ensure that data is of the highest quality or at least it is of enough quality that it can be worked with with the bigger picture. There can be many challenges in this process as sometimes the data is missing values or it is not consistent, sometimes also there is not enough data to work with.
During the retrieval phase, one should ensure that data is of the same data type, free of any typos and errors. However, this step is repeated again and sometimes repeated at every step to customize the data for different steps. The data should also be relevant to the problem at hand.
Step 3: Data Cleansing
This step is dedicated to the cleansing of the data and is an important step to ensure the best performance of the model.
During this process, the data is cleansed, transformed, and integrated. The data is checked for various points like, is the data of the same data type? Are there any outliers in the data? Are there any missing values?
The data that is collected is transformed and organized in a manner that it can be worked. This step involves removing any errors, duplicates, or missing values from the dataset, as well as transforming the data into a format that is suitable for analysis.

Step 4: Exploratory Data Analysis
Once the data has been cleaned, the next step is to explore the data to gain a better understanding of its characteristics and relationships
This involves visualizing the data using techniques such as histograms, scatter plots, and heatmaps, as well as calculating summary statistics such as mean, median, and standard deviation. This is where one can see the direct use of statistics and mathematics in the field of data science.
Step 5: Data Modelling
Once the data has been cleaned and prepared, and the features have been engineered, the next step is to select an appropriate model for the analysis. This may involve choosing from a range of machine learning algorithms, such as linear regression, decision trees, or neural networks, depending on the nature of the problem and the characteristics of the data.
The model when formed is trained using a portion of the dataset. It checks how fit is the model. Is the model poorly fitted? good fitted? best fitted?
Wanna know a secret? The best model is a good model (Literally) The model you want is good fitted not the best fit.

Step 5.1: Model Deployment
After the model has been trained and evaluated, the final step is to deploy the model in a production environment in order to generate predictions on new data.
This may involve integrating the model into an existing system or creating a standalone application that can be used to make predictions in real time. The model is now deployed and presented and is used for various exploratory purposes.
Step 6: Presentation
Any work done on the data, designs of the model, and solutions to the problems are now presented using various charts. These charts help others understand the complexity of the data and the solution in simpler terms.
This is the final step and once the satisfaction is reached from the project it is removed from the developing phase and presented to various audiences.
In conclusion, these processes are not rigid in any way, in fact, the best data scientists don't flow with the cycle instead customize it for their own needs and even add to it.
Comment out what steps you follow when working with the data and how does it improve your productivity!





Top comments (0)