
Hi fellow Dev, just want to share what I have done for my school project for a Deep Learning course. I hope you will like it. In this project we did a few things:
- crawling the image data from IMDB
- deciding and measure the effect of different cropping methods
- models and tweaks to improve classification performance
If you have a summer blockbuster or a short film, what would be the best way to capture your audience’s attention and interest? The 2 most prominent methods are apparent: posters and trailers.
Movie posters communicate essential information about the movie such as the title, theme, characters and casts as well as producers involved in the movie. Movie posters serve to inform the audience what genre of movie they are watching, so if given a movie poster, can a machine learning model tell the genre of a movie?
Movie posters are a crucial source of promotion with a great poster design being advantageous to appeal as extensive a viewership as possible. We want to find out if given a movie poster, can we predict if the movie is going to do well in the box office?
In this article, we will explore the data preparation and using convolution neural networks to build machine learning models to answer these questions.
Dataset
We collected 45466 movies metadata from The Movie Database (TMDb). There is a wide variety of attributes we can get from TMDb, but for this experiment, we are only interested in the following fields, 1) title, 2) genre, 3) poster, 4) popularity, 5) budget, 6) revenue.
Since a movie can fall into multiple genres, we will only pick the first genre of each movie so that each movie can only have 1 genre. In this experiment we intend to predict if a movie will do well in the box office, we will use revenue/budget ratio, defined as the movie is making money if the value is greater than 1; otherwise, it is not.
Here is the sample dataset loaded in Pandas data frame:
| id | title | genre | poster_path | popularity | budget | revenue | revenue_budget_ratio |
|---|---|---|---|---|---|---|---|
| 862 | toy-story | animation | /rhIRbceoE9lR4veEXuwCC2wARtG.jpg | 21.946943 | 30000000.0 | 373554033.0 | 12.45 |
| 8844 | jumanji | adventure | /vzmL6fP7aPKNKPRTFnZmiUfciyV.jpg | 17.015539 | 65000000.0 | 262797249.0 | 4.04 |
| 31357 | waiting-to-exhale | comedy | /16XOMpEaLWkrcPqSQqhTmeJuqQl.jpg | 3.859495 | 16000000.0 | 81452156.0 | 5.09 |
| 949 | heat | action | /zMyfPUelumio3tiDKPffaUpsQTD.jpg | 17.924927 | 60000000.0 | 187436818.0 | 3.12 |
| 9091 | sudden-death | action | /eoWvKD60lT95Ss1MYNgVExpo5iU.jpg | 5.231580 | 35000000.0 | 64350171.0 | 1.84 |
Data analysis and filtering
We won’t download all 45466 images right away. Instead, we will do some analysis, filter out those with data issues and select the list of movie posters to download.
Firstly, we will remove those with missing information:
- blank title after removing all non-alphanumeric characters
- no genre
- no poster URL
- no budget
- no revenue
After filtering out the undesirable data, there are 40727 movies. Below is the distribution of the number of movies in each genre:

For our genre prediction task, we want to predict between 10 classes. So we will select the top 10 genres and remove the rest.
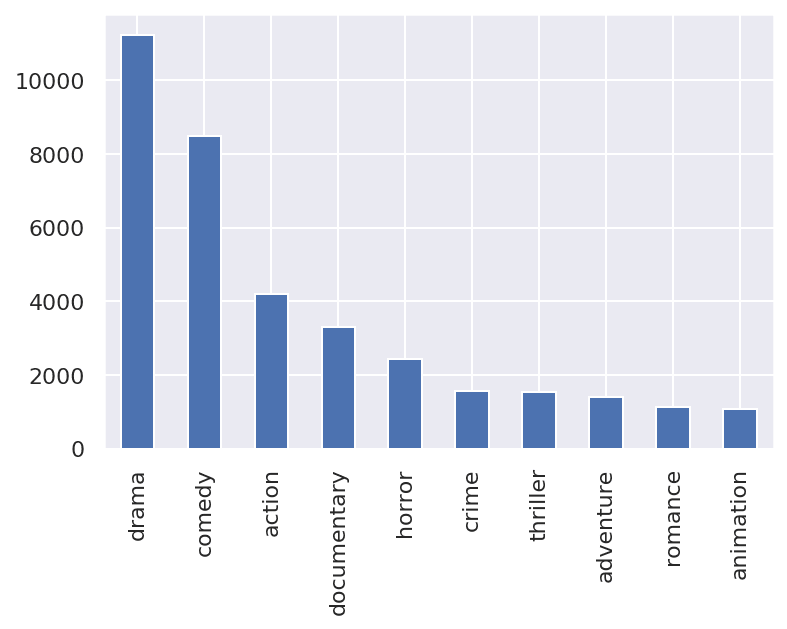
Hence, we select the top 1000 most popular movies in each genre based on popularity. These are the movies posters we will be downloading, 10,000 images across 10 genres.
Download the movie posters
From the data frame shown above, the poster_path is the name of the file. To get the image URL for Toy Story poster, we append http://image.tmdb.org/t/p/w185/ to the poster URL to get: http://image.tmdb.org/t/p/w185//rhIRbceoE9lR4veEXuwCC2wARtG.jpg.
We can download all the images with the Requests library. I would suggest adding a 1-second delay between each image download. This code is to download and save the images into respective genre folders for predicting the genre of the movie:
import requests
import time
import re
import os
def download_poster(downloaded_image_dir, title, label, poster_path):
if not os.path.exists(downloaded_image_dir):
os.makedirs(downloaded_image_dir)
if not os.path.exists(downloaded_image_dir+'/'+label):
os.makedirs(downloaded_image_dir+'/'+label)
imgUrl = 'http://image.tmdb.org/t/p/w185/' + poster_path
local_filename = re.sub(r'\W+', ' ', title).lower().strip().replace(" ", "-") + '.jpg'
try:
session = requests.Session()
r = session.get(imgUrl, stream=True, verify=False)
with open(downloaded_image_dir+'/'+label+'/'+local_filename, 'wb') as f:
for chunk in r.iter_content(chunk_size=1024):
f.write(chunk)
except:
print('PROBLEM downloading', title,label,poster_path,imgUrl)
time.sleep(1)
# download image by iterate pandas
for index, row in df_movies.iterrows():
download_poster(
'images_movies_genre',
str(row['title']),
str(row['genre']),
row['poster_path']
)
Image processing
In order to make use of pretrained models, we would first need to transform our rectangular posters into a square. Furthermore, to reduce the computation cost, the image size is resized to 224 by 224. We have identified 4 image processing methods to achieve these requirements:
- PIL library resize
- center crop library resize
- padding
- random crop and resize

Method #1: PIL library resize
Use the PIL library to resize the images to 224x224.
from PIL import Image
image = Image.open(PATHOFIMAGE)
image = image.resize((224, 224), Image.BILINEAR)
image.save(NEWPATH)
The processed image after resize was distorted below:

Method #2: center crop
We will transform the images using PyTorch’s Torchvision.
do_transforms = transforms.Compose([
transforms.CenterCrop(input_size),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])
])
dataset = datasets.ImageFolder(PATH, transform=do_transforms)
The processed image caused both the top and bottom of the image are cropped.

Method #3: padding
As most movie posters are portrait orientated, we decided to add black padding on the left and right. This would avoid any distortion and cropping of the original poster image. Since black padding is zeros in RGB, it will have a minimum effect on our convolution neural networks.
from skimage.transform import resize
def resize_image_to_square(img, side, pad_cval=0, dtype=np.float64):
h, w, ch = img.shape
if h == w:
padded = img.copy()
elif h > w:
padded = np.full((h, h, ch), pad_cval, dtype=dtype)
l = int(h / 2 - w / 2)
r = l + w
padded[:, l:r, :] = img.copy()
else:
padded = np.full((w, w, ch), pad_cval, dtype=dtype)
l = int(w / 2 - h / 2)
r = l + h
padded[l:r, :, :] = img.copy()
resized_img = resize(padded, output_shape=(side, side))
return resized_img
The processed image after applying Padding:

Method #4: random crop and resize
We will transform the images using PyTorch’s Torchvision.
do_transforms = transforms.Compose([
transforms.RandomCrop((280,280), padding=None, pad_if_needed=True, fill=0, padding_mode='constant'),
transforms.Resize(input_size, interpolation=2),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])
])
dataset = datasets.ImageFolder(PATH, transform=do_transforms)
The processed image after Random Crop and Resize.

Image processing results
To measure the accuracy of image processing methods, we used pretrained ResNet18 to perform classification. We will classify between the comedy and horror genre, as their posters are distinctly different in general. To ensure our comparison is fair, we did the following:
- the same set of movies for training and same set for validation
- set seed number
- load pretrained ResNet18 from PyTorch’s Torchvision
Model accuracy with different image processing methods are as follows:
- PIL library resize is approximately 80%
- Center crop library resize is approximately 80%
- Padding is approximately 85%
- Random crop and resize is approximately 85%

Random Crop and Resize method performs the best in model accuracy and processing speed. Position of the object in an image does not matter in convolution neural networks.
Can we tell the genre of the movie, by its poster?
In our preprocessing step, we can achieve approximately 85% accuracy for classification between 2 classes: comedy and horror. We choose comedy and horror because their posters are distinctly different between the 2 genres. Comedy generally brighter colours, while horror may be darker in contrast.
Here are some of our test cases, which are unseen by the model:

Interestingly, the model can learn and differentiate between these 2 genres. The model can likely pick up posters with skulls designs and associate the poster with horror movies. The 4th image shows that not all posters with a white background are comedy movies and that the model prediction is correct.
However, as not all genres following the general requirement of movie poster designs, these posters may cause the model to misread the designs. Subsequently, the model may misclassify these movies into the opposite genre. Below are some examples of movie posters deviating from the general designs associated with their respective genres.

The first image contains many regions of white and generally looked cheerful while the second image contains large regions of black which resulted in the poster looking dark despite cartoonish designs and fonts. These layouts misled the model, thus resulting in the wrong prediction.
Model identifying between 10 genres
In our dataset, we have 10 genres; each genre contains 1000 movie posters. An 80/20 split was performed to train and validate the model. We used 8000 images for training and 2000 images for validation (not used for training).
We utilised weights from the pretrained ResNet18 model to train a model to classify the genre of the movie based on its poster. These are the accuracies and losses during the training.

The validation accuracy is approximately 32%. Our model can learn and overfit on the trainset, but unable to generalise on the validation dataset.
The top-3 accuracy is approximately 65%. Which leads us to think, what could be causing all the misclassification? How could we further improve its accuracy? Below is a heatmap showing all the misclassification for top-1 model:
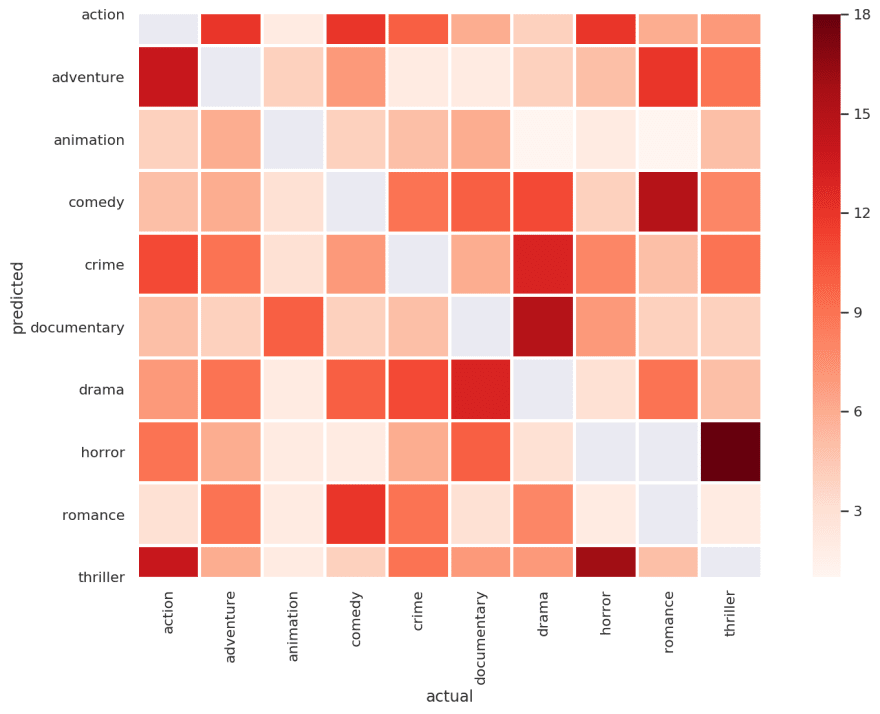
What we realised is that the model is having difficulty differentiating between horror and thriller posters. If you think about it, it is true even for us humans, where we might not be able to tell the difference between horror and thriller posters.
The same result is observed for comedy and romance, as both genres’ posters are in the lighter mood, and contains human and smiling faces.
Can we tell if the movie will make money in the box office, by its poster?
Since posters are a marketing tool for a movie, we want to find out whether a movie poster attracts more viewers. Can a model identify if a particular type of poster tends to do better in the box office?
In our experiment, we define how well a movie is doing by its revenue to budget ratio. A higher budget movie would require higher revenue to break even. The higher the ratio, the better the movie is doing.
We created 2 classes with the revenue to budget ratio, “did well” and “didn’t do well”. Movies with the ratio of 1 and higher “did well”, otherwise it is classified as “didn’t do well”.
Pretrained ResNet18
Yes! Our pretrained ResNet18 model can correctly identify if a movie would potentially make money, approximately 68% of the time.

Can we do better than this? I could change to a deeper Resnet but would not be interesting, so here are a few other experiments that we tried.
Bag of Tricks for Image Classification with Convolutional Neural Networks
A paper by Tong He et al. suggested ResNet tweaks that would improve by receiving more information in the downsampling blocks.
The author used these tweaks to improve ResNet50 model top-1 accuracy on ImageNet from 75.3% to 79.29%
Mish activation function
Mish is an activation function that is unbounded above, bounded below, smooth and non-monotonic.
The positive range of Mish activation function resembles closely to the most popular activation function, ReLu. Being bounded below resulted in regularisation effect. The negative range preserved small negative inputs which improve expressivity and gradient flow. Read more in this article about Mish by Diganta Misra.
Data augmentation
Recently advances in model accuracy have been attributed to generating more data via data augmentation; which significantly increase the diversity of data available for training.
from torchvision import transforms
image_transforms = {
# Train uses data augmentation
'train':
transforms.Compose([
transforms.RandomResizedCrop(size=256, scale=(0.8, 1.0)),
transforms.RandomRotation(degrees=15),
transforms.ColorJitter(),
transforms.RandomHorizontalFlip(),
transforms.CenterCrop(size=224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])
]),
# Validation does not use augmentation
'validate':
transforms.Compose([
transforms.Resize(size=256),
transforms.CenterCrop(size=224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])
]),
}
Homemade deep and wide ResNet
This is inspired by the Wide & Deep model for Recommender Systems, by combining a pretrained ResNet with pretrained wide-ResNet.
Firstly, we loaded both pretrained ResNet and pretrained wide-ResNet and removed the last fully connected layers for ImageNet classification. We then appended a 3x3 convolution, batch normalisation and ReLu from the inputs to both ResNet. Lastly, we concatenate the output from both ResNet followed by addition of another 3x3 convolution and a fully connected layer for classification.
Classification results with various experiments
Here are our results:
| Method | Accuracy (best val. loss) | Time taken per epoch |
|---|---|---|
| ResNet18 | 0.6809 | 8s |
| ResNet18 + Bag of Tricks | 0.6968 (+2.3%) | 35s |
| ResNet18 + Mish | 0.7021 (+3.1%) | 13s |
| ResNet18 + Bag of Tricks + Mish | 0.6915 (+1.6%) | 40s |
| Deep and Wide ResNet | 0.6879 (+1.0%) | 47s |
| ResNet18 + Data augmentation | 0.7037 (+3.3%) | 8s |
Mish can get a 3% improvements because of the regularisation effect, thus generalise on the unseen a little better. I would give this activation more exploration in future.
Data augmentation have 3% improvements too, in fact, I am a little surprised that data augmentation would have improvements on this problem.
Conclusion
Given based off a movie poster alone, predicting earnings and popularity of a movie can be a daunting task. This issue rings true even for distribution companies and investors who have hundreds of experts and analysts working for them to ensure that their investments are not in vain and reap rich returns. The introduction and progress of our model may result in the future aid these analysts and companies in making more detailed and sound predictions.
Upon further experimentation, to achieve a more accurate reading, delving into a deeper ResNet model might increase in performance. However, in our experiments, we applied Mish activation and various tweaks from research papers; as such results returned are promising and is a path worth exploring further.
Training the AI model is half the battle; it is worth noting real-world data are “dirty” and “unrefined”; what these meant are not all data are accurate and present. For machine learning to work, we must first understand our data well and understand what is needed for our model to succeed.
Notebook on gist.github.

{kind=link}
Top comments (8)
An interesting read! Thanks.
Awesome post! Are you able to make the repo public?
I combined and uploaded to gist.github.
Thanks, you're a boss!
That is really helpful.
Thanks for sharing
Thanks! Glad you liked it.
Fantastic article 💥. Does your project have a repo on GitHub?
I just combined and uploaded to gist.github.