
Welcome to the first installment of Learning Kafka series. It’s time to meet Kafka proper.
What Exactly is Kafka?
According to Kafka’s documentation, Kafka is described “as an open-source Distributed Event Streaming Platform used by thousands of companies for high-performance data pipelines, data integration and mission critical-applications”.
But Kafka can be captured the three words really; distributed, event and streaming-platform.
Let’s take a closer look at each of these words.
Distributed
A distributed system is nothing but a group (two or more) of systems or computers working together in parallel as a single, logical unit. They appear as a single unit to the end user. A system in this context can be anything from a laptop, a desktop, a server to a compute instance on the cloud.
For example, traditional databases are run on a single instance, whenever we want to query the database, we send request to that single instance directly.
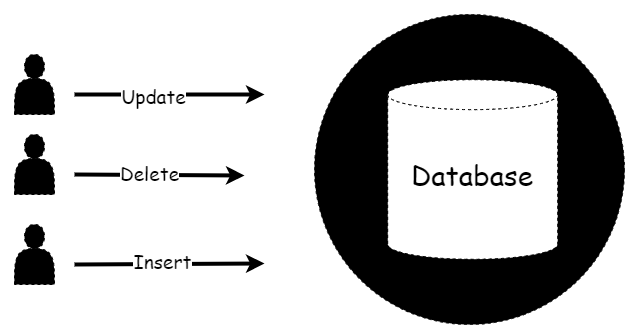
A distributed version of this system will have the same database running on multiple instances at the same time. We would be able to talk to any of these instances and not be able to tell the difference. For example, if we inserted a record into instance 1, then instance 3 must be able to return the record.
A group of these instances is collectively known as a cluster while a single instance in the cluster is called a node or server.

Apache Kafka works in a distributed fashion, although it’s possible to run Kafka on a single node, this means losing out on all the things that makes Kafka……… Kafka.
Event
An event is…… just an event. Okay, that’s not helpful, but an event is really just an event. Sometimes (most-times?) traditional English words can mean a totally different thing in computer, but that’s not the case here. According to Oxford dictionary “An event is a thing that happens, especially something important”. An event in Kafka means just that. A user clicks on a particular link? An event. A traffic light changed from red to green? An event. An administrator logs into a computer? And event. Someone tweets a tweet? (Okay, don’t know if that is correct) An event. We now hopefully get the idea of what an event is. An event is an event. Moving on.
Streaming platform
Before discussing streaming platform, lets first understand what streaming is. Streaming is the unending, continuous generation of data. These data can be from different sources, be of diverse types and comes in different formats. They are also generated by both humans and machines.
A streaming platform is a platform or a system that helps in the gathering and movement of streaming data.
From the above explanations, we can say that Kafka is a group of systems (working together as one) that facilitates the movement of streaming data (called events) from source systems to target systems.
Origin
Developed at LinkedIn in 2010, by team that included Jay Kreps, Jun Rao, and Neha Narkhede, Kafka was used originally for the purpose of tracking LinkedIn users’ activities in real time. It was open-sourced and released to the Apache Software Foundation in 2011, and was graduated to a full Apache Project in 2012.
Kafka is written in Java and Scala and was named after the author Franz Kafka.
Features
Kafka is known for being durable, scalable and fault tolerant. Coupled with its high-throughput and high availability, Kafka has become the most popular choice for event driven systems. A quick refresher;
- Durability is the ability of a system to retain and not lose data permanently.
- Scalability is the ability of a system to grow and manage increased demands.
- Fault tolerance is the ability of a system to continue operating without interruption when one or more of its components fail.
- Throughput is the measure of how many units of work, information or request a system can handle in a given amount of time.
- Availability is the percentage of time that a system remains operational under normal circumstances.
Use cases
Kafka’s original use case was to track users’ activities like page views, searches and other actions users may take, but its success has seen it evolved to other uses, for example;
Streaming Data Pipelines
One of the most popular use cases for Kafka is building streaming data pipelines. Where data is continuously being moved from source to destination in real time.
Messaging system
Messaging system is a system that enables applications to share data between each other.
Because of its design architecture (which we will cover in part three), Kafka can also be used as a replacement for traditional messaging systems like ActiveMQ and RabbitMQ.
Stream Processing
Instead of just storing and moving streams of data, Kafka can also be used to process, transform and enrich these data in real time with Kafka streams.
And that’s the end of this section, we have discussed what Kafka is, its origin and use cases, we also touched, briefly, on distributed systems, streaming, and events. And a quick explanation on words like throughput, availability, fault tolerance, durability, and scalability. Now that we are better equipped, lets dive even deeper into Kafka.
Up next, the core components of Kafka.

Top comments (0)