
So far in this series, we’ve talked about what Kafka is, what it does and how it does it. But all of our discussions has been centred on the components that lives within Kafka itself, we are yet to discuss about those other components that live outside of Kafka but interacts with it. We’ve caught a glimpse of few like producers and consumers. In the upcoming segments, we will be having a closer look at each of these components, starting from producers and consumers to Kafka Streams and Kafka Connect.
At the basic level, any component that interacts with Kafka is either a producer, a consumer or a combination of both. Let’s start with The Producer.
Producer
A producer is any system or application that writes messages to a Kafka topic. This can be anything, from a car that sends GPS coordinates to a mobile application that sends the details of a transaction.
Producers can send messages to one or more Kafka topics, also, a topic can receive messages from one or more producers.
When writing messages to Kafka, we must include the topic to send the message to, and a value. Optionally, we can also specify a key, partition, and a timestamp.

Batching
By default, producers try to send messages to Kafka as soon as possible. But this means an excessive produce requests over the network and can affect the whole system performance. An efficient way to solve this is by collecting the messages into batches.
Batching is the process of grouping messages that are being sent to the same topic and partition together. This is to reduce the number of requests being sent over the network.
There are two configurations that controls batching in kafka, time and size.
- Time is the number in milliseconds a producer waits before sending a batch of message to Kafka. The default value is 0, which means to send messages immediately they are available. By changing it to 20ms for example, we can increase the chances of messages being sent together in a batch.
- We can also configure batching by size. Where size is the maximum number in bytes a batch of messages will reach before being sent to Kafka. By default, the number is 16384 bytes. Note that if a batch reaches its maximum size before the end of the time configured, the batch will be sent.
Batching increases throughput significantly but also increases latency.
Sending the same amount of data but in fewer requests improves the performance of the system, there is less CPU overhead required to process a smaller number of requests.
But since in order to batch messages together, the producer must wait a configurable period of time while it groups the messages to send, this wait time is increased latency.
Partitioning
If we didn’t explicitly specify a partition when sending a message to Kafka, a partitioner will choose a partition for us. Usually, this is based on the message key, messages with the same key will be sent to the same partition.
But if the message has no key, then by default, the partitioner will use the sticky partitioning strategy; where it will pick a partition randomly, then send a batch of messages to it, then repeat the process all over again.
Previously, before Kafka 2.4, the default partitioning strategy is round-robin; the producer sends messages to Kafka partitions serially, without grouping them into batches, starting from partition zero upwards, until each partition receives a message, then starts over again from partition zero.
Serialization
But before the producer send these messages, it must be converted to bytes in a process known as serialization, as messages stored on Kafka has no meaning to Kafka itself, so they are stored as bytes.
Kafka comes with out of the box serialization support for primitives (String, Integer, ByteArrays, Long etc), but when the messages we want to send is not of primitive type (which is most times), we have the option of writing a custom serializer for the message or using serialization libraries like Apache Avro, Protocol Buffers (Protobuf) or Apache Thrift.
It is highly recommended to use serialization libraries, as custom serialization means writing a serializer for every different type of message we want to send, and this does not handle future changes gracefully.
Consumer
A consumer is any application that reads messages from Kafka. A Consumer subscribes to a topic or a list of topics, and receives any messages written to the topic(s).
When a single consumer is reading from a topic, it receives messages from all the partitions in the topic.

Apart from reading messages from Kafka, a consumer is similar to a producer except for an important distinction; Consumer Group.
Consumer Group
A consumer generally, but not necessarily, operates as part of a consumer group. A consumer group is a group of consumers that are subscribed to the same topic, and have the same group ID. A consumer group can contain from one to multiple consumers.
When consuming messages, consumers will always try to balance the workload evenly amongst themselves. If the number of consumers in the group is the same as the number of partitions in the topic, each consumer is assigned a partition to consume from, thus increasing throughput.

But if the number of consumers in a consumer group is more than the number of partitions, the consumer(s) without partitions will be idle.

Consumer group ensures high availability and fault tolerance of applications consuming messages. For example, if a consumer in a group goes offline, its partition gets assigned to an available consumer in the group to continue consuming messages.
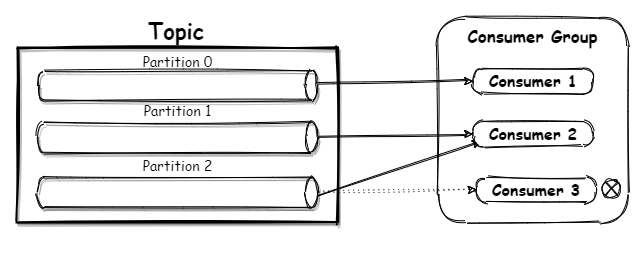
This design also allows consumers to scale, if a consumer is lagging behind a producer, we can just add another consumer instance to the group. Also with consumer groups, different applications can read the same messages from a topic, we just create a consumer group with a unique group ID for each
application.

It is also important to note that Kafka guarantees message ordering within a partition, but does not guarantee ordering of message across partitions. That is, if a consumer is consuming from a single partition, messages will always be read in the order they were written, First-In-First-Out (FIFO). But if consuming from multiple partitions, messages might get mixed up.
Deserialization
As mentioned earlier, producers serialize messages before sending them to Kafka, as Kafka only work with bytes. Therefore, consumers need to convert these bytes into its original format. This process is called deserialization.
And with that, the end of this segment.
Coming up, the Kafka Streams Library.

Top comments (0)