I'm currently working on a celebrity face recognition app, leveraging the api provided by Clarifai team.
This api returns a list of candidates' name when you send a image url with celebrities face(s) to it.
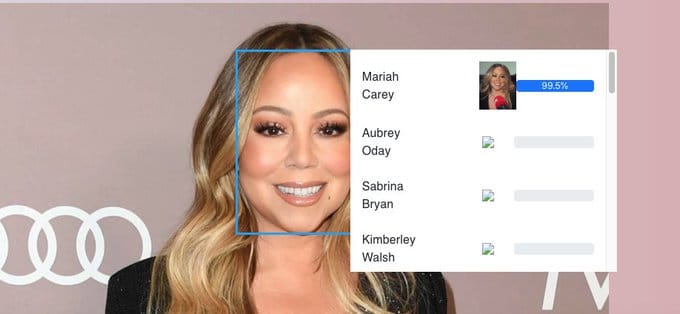
To increase the performance, I decided to not only show the names of the candidates, but also attach a thumbnail of the celebrity, like this:
The solution came up to my mind is using wikipedia to get the profile page of that celebrity, which normally contains an image of the celebrity as well.
But how should I parse the page and retrieve the thumbnail url from it?
I tried to use the curl-request package first, which worked well locally. But when I tried to deploy it on Heroku, I got a whole bunch of errors. It turned out that one of the dependancy package of curl-request - node-gyp is not supported by node higher than 10.x, which is sebsequently not supported by npm higher than v6. When I use npm 6.x to build the project, I also get error from heroku.
To solve this conflict, I started to think about whether I really need to use curl-request. And the answer is No.
After googling, I found this solution - using http module to get the html code then parse it.
A slightly modified version of @sidanmor 's code. The main point is, not every webpage is purely ASCII, user should be able to handle the decoding manually (even encode into base64)
function httpGet(url) {
return new Promise((resolve, reject) => {
const http = require('http')
https = require('https');
let client =Up until now I've understood why we have to think carefully when we are adding a new package. Because when you add a new package, it means you are being dependant on it. Once it's deprecated, you might get trouble.





Top comments (0)