Introduction
The goal of this series of articles is to introduce the features and explain the functionality of the Helm Universal Layer Library - in short HULL. It is a Helm library chart which can help in efficiently creating and managing applications in Kubernetes. The HULL project is open source and you can find it on GitHub:
 vidispine
/
hull
vidispine
/
hull
The incredible HULL - Helm Uniform Layer Library - is a Helm library chart to improve Helm chart based workflows
HULL - Helm Uniform Layer Library
This repository contains the HULL Helm library chart. It is designed to ease building, maintaining and configuring Kubernetes objects in Helm charts and can be added to any Helm chart as an addon to enhance functionality without any risk of breaking existing Helm chart configurations.
The chart itself and all documentation related to it can be found in the hull folder which is the root folder of the HULL library helm chart.
The Kubernetes API JSON Schemas are stored in the kubernetes-json-schema folder.
If you are unfamiliar with the terms Helm and Kubernetes a brief introduction will follow. However if you have no experience with Kubernetes and Helm it is recommended to study and get practical experience first before proceeding with the tutorials because some familarity with the concepts is required to follow the article(s).
Kubernetes is the defacto standard in modern application deployment and management, especially in the cloud. Helm is a wide-spread tool for packaging and managing Kubernetes applications in form of so-called Helm Charts. Helm supports the concept of 'Library' charts which in itself do not contain deployable objects but only helper funcions to foster Helm chart creation and configuration. HULL falls into this category and can be thought of as an extension or plugin to Helm.
Before getting started with creating a real-life HULL based Helm chart step-by-step in the next articles of this series, some light shall be shed on the concept of HULL and how it affects the Helm Chart based workflow in this introduction. Feel free to skip to the next article in the series if you like to start more practically. Yet it is recommended read on to have an idea why you might want to use HULL (or why not).
Chart design with Helm
Kubernetes objects are typically defined as YAML files and submitting these YAML files to the Kubernetes API (for example via kubectl commands) will create them as entities in the Kubernetes cluster. An application normally will consist of multiple objects such as Deployments, ConfigMaps, Ingresses and so on. Helm expects all the YAML files it needs to deploy to be created in the /templates folder of a Helm chart which is to be deployed.
Building a Helm chart now starts at defining which Kubernetes objects need to be created and which means to adapt them need to be provided in order to be able to run your application under a variety of conditions. Helm charts need to be deployable to different environments such as development, staging or production where different endpoints, credentials, resource sizings etc. all need to be configurable. Or simply think about cloud versus on premise systems where different rules apply in terms of networking, load balancing and scaling. All these aspects need to be tweakable in your applications Helm chart if your application is intended for wide-spread usability.
With plain Helm, technically all objects that may be created under a certain scenario need to be scaffolded in the /templates folder in form of Kubernetes YAML files. To exactly control the logic of which files need to be deployed and which values need to be modified in a particular system, Helm integrates a templating language (Go templating in this case). Using templating expressions in the Kubernetes YAML files it becomes possible to influence the templating logic and produce valid Kubernetes YAML files for a particular scenario (given that the scenario was considered when designing the chart).
The external source for controling the templating logic is in the first step the so-called values.yaml file which is contained in each Helm chart. It serves multiple purposes in reality:
- provide reasonable defaults that should satisfy most system needs → defaulting
- provide an overview of the configuration options a particular Helm chart aims to implement → documentation purpose
The values.yaml should never be modified itself on deployment for a particular system, it is a static artifact which itself can be modified by overlaying a system-specific configuration file that holds the deviations from the defaults which are required for a particular deployment scenario. Technically the additional system-specific configuration file must match the YAML structure of the values.yaml so its content can be merged with that of the values.yaml. It is even possible to provide multiple system-specific configuration files which will be merged in a defined order. The overlaying configuration files always have precedence over the defaults naturally.
For visualization consider some example mappings of a fictitious Helm chart with one deployment and a configmap in the /templates folder:
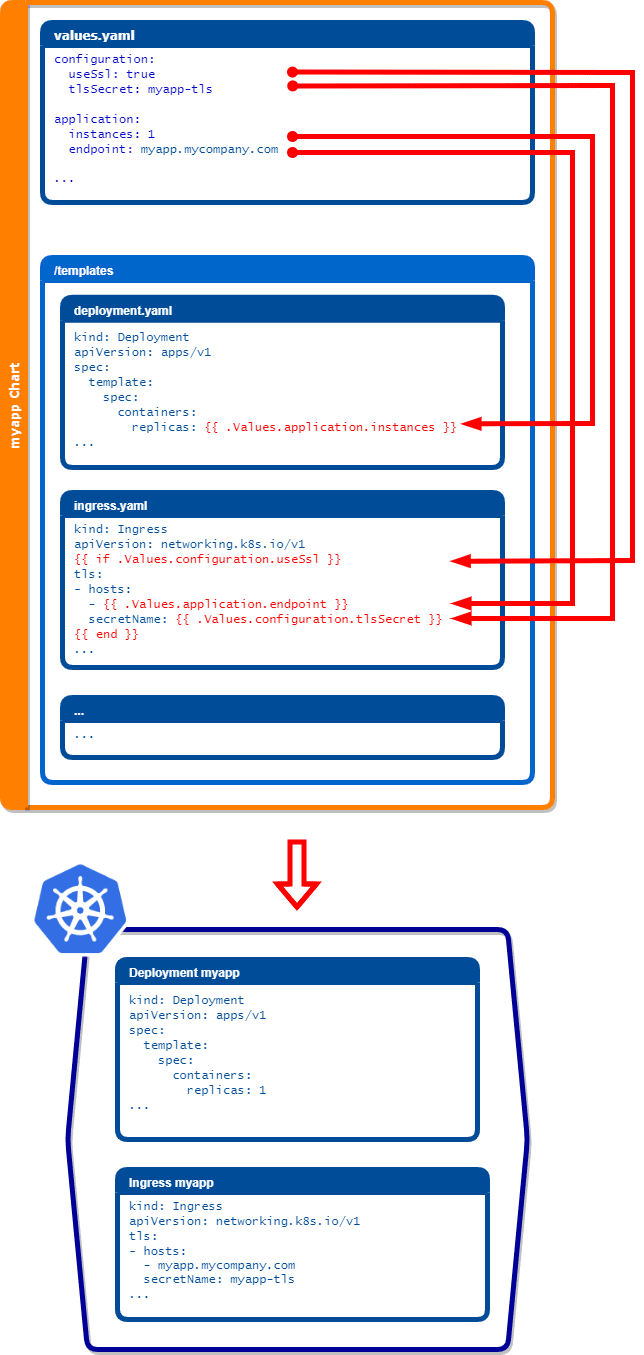
The following can be deduced from the example shown above:
- the more objects my application requires the more template files need to be created
- with each template file a significant amount of boilerplate YAML structure needs to be created
- the more aspects of objects that require controlling, the more mappings need to be manually defined
- there is no fixed naming relation between source values in
values.yamland the targeted values in the templates.
The Good
Flexibility
The most positive aspects of the above outlined approach is full flexibility in defining what the mappings shall do. Hence it is possible to control aspects of:
- multiple objects with a single configuration value (1:n)
- single objects with a combination of multiple configuration values (n:1)
- multiple objects with combination of multiple configuration values (n:n)
Basically anything is possible but must be explicitly realized by writing the templating logic - even the most simple 1:1 projections. Each Helm chart has in that sense its own individual API which can be tailored towards the usage of the application.
The Bad
Implementation
While the Helm mapping flexibility shines when complex application configurations are required, it cannot on the other hand work without existance of explicit mappings. Considering that within a regular Helm chart typically a significant number of the implemented mappings are rather simple 1:1 mappings between values.yaml properties and single object fields involving no further logic, the Helm mapping approach adds a noticeable overhead to chart writing. For each mapping or projection, template files for the objects need to be created, the templating logic needs to be inserted correctly and the values.yaml needs to be updated to indicate the mappable property and the underlying logic needs to be documented.
Maintenance
As seen there is a significant amount of manual caretaking required when developing and maintaining a Helm chart this way. Consider a real life Helm chart having dozens of objects with hundreds of YAML lines where many mapped values in the templates may need configuring. Furthermore often configurable options on objects are left out initially because they are either not as relevant as others to the chart creator or out of laziness. If someone needs to configure such an option for his deployment scenario the chart needs to be adapted by either submitting a pull request, local forking or any other similar method.
Intransparency
From the perspective of someone who is proficient with Kubernetes it is often unnecessarily unclear how to achieve the desired Kubernetes object configuration without inspection of the mappings between values.yaml and the templates. In this sense, each Helm chart has its own unique API which requires analysis to understand the effects configuration changes in values.yaml have on the templates. The documentation of this interface, the values.yaml comments, often lack in explaining the effects that setting a specific property has on the generated templates. Meanwhile certain conventions have been established that can be found in multiple charts but there is no guarantee that an identical named property in values.yaml will have the same effect in different charts.
What is the difference when using HULL?
The HULL library Helm chart provides a single common interface to specifying Kubernetes objects within Helm Charts. The interface itself is based on the Kubernetes API schema itself which is integrated as a JSON schema in the HULL chart. Since all objects are defined directly in the values.yaml under the hull key there is no need to create and maintain custom template files when creating objects with HULL, everything happens in the values.yaml.
The following diagram sketches how the myapp Helm chart would be built and processed when using HULL:

Being able to directly manipulate any object's property is advantageous in getting rid of the need for implementing explicit mappings, but it would alone not be sufficient to model more complex aspects such as the mentioned 1:n, n:1 or n:n mappings. To cater for this, HULL integrates a unique mechanism called HULL transformations to also allow integrating Go Templating expressions into the values.yaml itself without violating the constraint that the values.yaml file must be valid YAML.
This means you bascially have the same toolset available as with the regular Helm chart workflow but you can restrict yourself to only model configurational relations where it is useful or required. There is no need to model all exposed object properties explicitly, resulting in the amount of code to maintain within a Helm chart to be reduced drastically. Depending on application structure more than 50% of overall lines of configuration code can be saved when building a Helm chart with HULL.
So why would you want to choose using HULL?
The strengths of the HULL based approach are:
having less work when creating or maintaing a larger number of Helm charts since HULL based charts reduce the 'boilerplating' of template files to a minimum. Only explicitly model what you actually want or need to model explicitly saves time and effort in chart creation.
giving the chart users the full flexibility to configure all aspects of any Kubernetes objects right away without having to patch an existing Helm chart.
providing convenience features that simplify common tasks in the context of Helm chart creation. Automatic creation of extensive metadata is done without additional effort and including external files is done within a few lines of configuration.
So whenever you either maintain many not overly complex Helm charts and want to have a fully flexible, maintanable, documented and common interface to all of them, HULL may be the right choice for you.
If on the other hand you manage a single or small number of Helm chart(s) for your company to be deployed to a limited number of environments you might not benefit as much from building charts around HULL though because the benefit pays of when you have to scale the chart creation process.
Wrap Up
Thanks for reading and hoping this sparked your interest. If you'd like to please proceed with the tutorial on chart building with HULL where the popular kubernetes-dashboard Helm chart is being 'reinterpreted' using HULL to showcase its applicability to real life use cases!





Oldest comments (0)