
Benjie is the community–funded maintainer of the Graphile suite — a collection of MIT–licensed Node.js developer tooling for GraphQL and/or PostgreSQL. A key project in this suite is PostGraphile, a high performance, customizable and extensible GraphQL schema generator for APIs backed primarily (but not exclusively!) by PostgreSQL.
This is part three in the "Intro to PostGraphile V5" series, which started with Part 1: Replacing the Foundations. This week, Benjie talks about his new introspection and schema generation system, and how it leads to improved type safety, documentation, and better compatibility. This new system is coming in PostGraphile Version 5, available in pre–release now for all Graphile sponsors, find out more at postgraphile.org
For PostGraphile to be able to build an API based on your PostgreSQL database, it needs to know what your database contains: what are the schemas, tables, columns, indexes, constraints, functions, views, grants, etc. To do this, it uses a technique called "introspection": it issues SQL SELECT statements against the "system catalog," effectively having the database describe itself. PostGraphile (and previously PostGraphQL) has done this since the very beginning of the project.
PostGraphile V4 inherited its introspection query from PostGraphQL v3, v3 from v2, and v2 from v1. Each version added tweaks, enhanced support for various entities, or improved compatibility with newer versions of PostgreSQL, but the structure remained similar throughout. The result was a very PostGraphile–specific introspection query, with its own documentation and typing needs, a lot of accommodations for different PostgreSQL versions, and very poor compatibility with PostgreSQL–alike databases, such as Cockroach DB.
Meanwhile, during consulting…
Whilst reviewing various PostGraphile–based client projects, I noticed a number of very common issues that people would have in their database schemas. Things like forgetting to enable row level security on a table despite creating policies for it (a major security issue!), forgetting to create indexes on foreign key constraints (making reverse lookups often require table scans — a major performance issue) and other such things. I came up with a large number of rules, and wrote a system that could detect these problems, which you can use at https://pgrita.com . It's a little rough around the edges (PostGraphile V5 has taken all my attention recently), but it packs a hell of a lot of value for its early access price of just $25/mo. There's even a free plan!
Whilst building pgRITA I needed to support lots of different PostgreSQL versions, and I needed an easy way to deal with the introspection results from them — not least making sure I didn't make typos, and knowing what fields like attinhcount even meant. So I built something that parsed the PostgreSQL documentation and converted it into TypeScript types, with documentation built in via TSDoc. It was delightful, and made writing the rules for pgRITA much easier. It even knew which properties were common to all the different PostgreSQL versions, versus which ones might only be in earlier or later versions and marking them as optional (using ?).
A new hero arises…
When it came time to build the introspection for PostGraphile V5, I decided not to reuse the introspection query that had served us well for the past 7 years. I had something better to base it on: the pgRITA system. Some customization later and I'm proud to announce the pg-introspection library — a fully–typed introspection library for PostgreSQL. It's already out on npm, and you can use it for any other projects too! Don't worry that it's not had any updates in a number of months, it's essentially "finished" and will only need updates when breaking versions of PostgreSQL (or TypeScript) come out.
This new system has many advantages over the old one:
- it's much easier to keep in sync with new PostgreSQL versions because it's generated from the documentation,
- it doesn't need a different query for different versions of PostgreSQL because it rarely references the columns directly, instead using
SELECT *or similar techniques, - it doesn't need as much documentation (or custom TypeScript types) because these are auto–generated,
- it works better with Postgres–alikes because it doesn't use as many fancy query features,
- it’s easier to understand thanks to being generated — it reuses many of the same patterns which makes the structure uniform and consistent.,
- we've augmented it with a number of helpers to make life easier,
- and much more.
Revisiting abstractions
A question remained though. In V4, plugins would use the introspection results directly to generate the types, fields, args, etc in our GraphQL API. Was this what we wanted for V5? One issue with the V4 approach is that when you make breaking changes there’s no easy way to "fake" a duplicate table to support the deprecated usage patterns whilst moving everything over to the new way.
I'm a big believer in GraphQL (in fact, at time of writing I'm #2 contributor to the GraphQL spec itself) so it pains me that a tool I built doesn't always have easy ways to achieve the "versionless schema" design that GraphQL encourages when it comes to making significant breaking changes to your underlying database tables. (Personally, I think you should aim for your database schema itself to be versionless, but this is not always possible.) Of course you can build your PostGraphile schema over views instead of tables, but views have their own problems that I won't go into here…
“No,” I thought to myself, “clearly the V4 approach had problems. There should be an intermediate layer. And I'm rebuilding everything, so why not?”
Introducing build phases
Leveraging our new plugin system's scopes, I split the schema building into four phases: inflection (naming things), gather (performing introspection and similar tasks), behavior (which we'll look at next week) and schema (actually building the schema, synchronously, based on the previous phases' outputs).
The inflection phase registers a number of "inflector" functions, named by purpose, that accept as input a description of an entity and return a string to be used as the name for that entity for that purpose (e.g. when creating (the purpose) a user (the entity) you might want the mutation field name createUser, or userCreate, or even create_a_user — with inflection, it's up to you). Importantly, inflectors can be added but they can also be replaced; the replacement has access to the previous inflector allowing it to add to, augment, or fully replace the previous value.
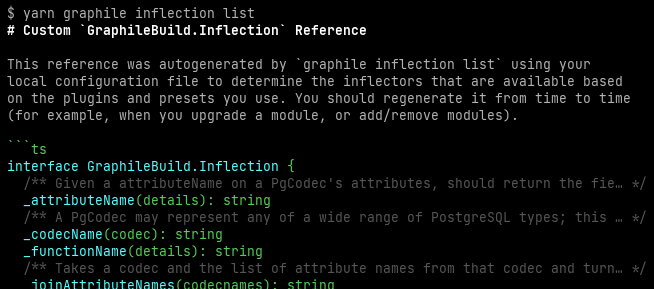
The initial output of the new graphile inflection list command, including a summary of the available inflectors and their arguments.
Next up is the gather phase, during which all the information necessary to build the GraphQL schema is brought together. This includes things like the introspection results from the PostgreSQL database, row values in enum tables, and anything else essential which needs to be fetched from a remote source. At the end of the gather phase an "input" object is produced, ready to be fed into the next phase. This object currently consists of "resources", "codecs” and the relations between them. Resources describe things that PostGraphile can pull data from: tables, views, functions, etc. Codecs describe the data and how to parse it from (or serialize it to) the database; and not just the base types such as int, float, text — codecs also cover more complex things like arrays, domains, and composite types (records).
The behavior phase squeezes in just before the schema phase, and gives a chance to indicate or override what the specific behaviour of each of the codecs, resources and relationships will be. We'll look more at this next week.
Finally, is the schema phase. The schema phase takes the "input" object produced by the gather phase and – by applying all the schema hook callbacks – uses it to synchronously build out the GraphQL schema. It's important to note that unlike the gather phase, the schema phase can be synchronous because any asynchronous data fetching should already have been done in the gather phase.
Bring your own resources
An interesting feature of this system is that you don't actually need a gather phase at all — you could describe your tables, columns and functions yourself and have the schema be generated from these descriptions. Or you can combine the gather phase with a post–processing step where you copy a source with a few changes and a different name in order to back–fill your backwards compatibility needs. You can also gather from multiple different databases, building a GraphQL schema from multiple PostgreSQL databases without your schema consumers being any the wiser. It's a very powerful feature!
Of course it's critical when using a (mostly) auto–generated schema that you can hone its shape easily and quickly, hence the behaviour system we'll talk about next time…
Next week, Benjie will be discussing how Version 5 users can customize and shape their GraphQL schema using a globally configurable behaviour systemNext, check out Intro to PostGraphile V5 (Part 4): Making the Schema Yours; and remember: to get your hands on a pre–release version of PostGraphile V5, all you need to do is sponsor Graphile at any tier and then drop us an email or DM! Find out more at graphile.org/sponsor

Top comments (0)