Mergestat is a powerful tool that allows users to analyze Git repositories and gather important insights related to the commit history but not only it!
It comes in two different modes:
- Mergestat Lite
- Mergestat (Full)
The main difference between the two is that Mergestat Lite is a fast and lightweight local command line tool that uses SQL queries and SQLite to analyze Git repositories. It doesn't load data into a SQLite database file but fetches data directly from the source (like Git repositories on disk) as queries run. This makes it great for analyzing small repositories quickly, but it might not be the best option for larger ones.
On the other hand, Mergestat Full has a worker process that analyzes the repository and syncs the collected data into a PostgreSQL database. This mode provides a more robust and scalable solution for collecting data from larger repositories and analyze it at a later stage.
Although my initial plan for #GitHubHack23 challenge was to use Mergestat Lite to analyze the repository where the workflow was launched, perform the analysis and create an issue via the GitHub API to summarize all the information collected using the mergestat summarize commits command:
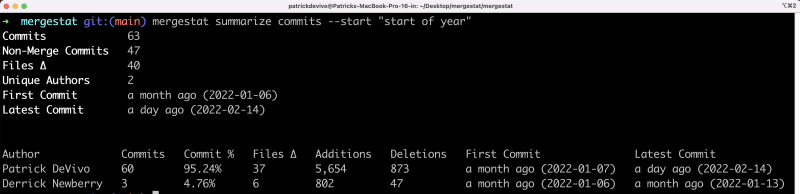
I eventually chose to pursue a more complex solution!
Despite being more challenging, I believed that this approach would be more versatile and capable of fully utilizing the potential of the tools available on GitHub 💪!
In the end, I decided to build a GitHub Action workflow that launch mergestat docker containers to analyze the repository, store the results in a PostgreSQL database and export it as workflow artifact.
Workflow implementation
The workflow itself was not complex and used standard GitHub Actions.
jobs:
start:
runs-on: ubuntu-latest
steps:
- name: Checkout
uses: actions/checkout@v3
- name: Start containers
run: docker-compose -f "docker-compose.yaml" up -d
working-directory: scripts/ci
- name: Setup node
uses: actions/setup-node@v3
with:
node-version: 16.13.x
cache: npm
cache-dependency-path: scripts/ci/package-lock.json
- name: Install
run: npm ci
working-directory: scripts/ci
- name: Run script
run: npm start -- ../../config.json http://localhost:5433/graphql
working-directory: scripts/ci
- name: Postgres Dump
run: |
docker exec -i postgres pg_dump -U postgres -Fc -Z 9 postgres > backup_mergestat.dump
- uses: actions/upload-artifact@v3
with:
name: pg-dump
path: 'scripts/ci/backup_mergestat.dump'
- name: Stop containers
if: always()
run: docker-compose -f "docker-compose.yaml" down
working-directory: scripts/ci
The only challenging part was finding a way to instruct Mergestat to index the selected repositories using the command line, as it is normally done via the UI.
Let's take it step by step.
Startup containers and install requirements
The first step is to download the source code and start all the required containers for mergestat using docker compose. To do this, I used the YAML script available on the mergestat website, removed the container for the graphical interface, and, most importantly, simplified the authentication process towards the GraphQL API by modifying the default_role of the Graphile Engine. This way, all API calls, even those not authenticated, will use the admin role, and it will be possible to bypass the authentication call... There might have been other ways, but for the project's purposes, this seemed to be the quickest and safest approach.
I had also started to figure out how to apply GitHub Services Container instead of docker compose to run PostgreSQL and the worker, but from what I've seen it's not (yet) possible to start a service container (in our case, the worker) only when another container (in our case, PostgreSQL) is ready.
After that, I set up the environment for Node.js, installed the necessary packages, and started compiling the TypeScript scripts.
Preparation script to indexing repository
For the writing of this script, I had mainly two options: either to understand the internal details of the database and write the appropriate SQL queries to insert the data, or alternatively, to use the same APIs that are used by the web portal.
In the end, I chose the second option and to speed up the process, I partly analyzed the calls made to the GraphQL endpoint using browser developer tools, and partly studied the code, reusing useful portions such as the schema, queries, and mutations. I also made extensive use of Codespaces to have a ready-to-use environment when needed to spin up all needed tools.
async function main() {
let configPath = process.argv[2];
if(!configPath) {
console.error('ConfigPath is not valid: ' + configPath);
process.exit(1);
}
console.log(configPath);
const config : ConfigRoot = ConfigReader.read(configPath);
let endpoint = process.argv[3];
console.log('Endpoint: ' + endpoint);
if(!endpoint) {
endpoint = defaultEndpoint;
}
graphQLClient= new GraphQLClient(endpoint);
await create(config.repositories);
let syncCompleted = false;
const total = config.repositories.length;
do {
const status = await getReposStatus();
console.log(status);
console.log('Wait completing count repositories: ' + total);
syncCompleted = await checkSyncCompleted(status, total);
await sleep(5000);
}
while(!syncCompleted)
}
The script is quite long, which is why you won't find it all in this article, but it is of course available on the GitHub repository.
I don't write much Typescript code in general (I mainly work on .NET projects), but apart from the initial configuration of the compilation scripts using ts-node, the rest went smoothly and it's just simple query and mutation GraphQL calls... actually, it was a great opportunity for me to deepen my knowledge of GraphQL with a different technology stack.
To make the script configurable, a JSON configuration file is read, such as:
{
"repositories": [
{
"url": "https://github.com/salem84/AspNetCore.VersionInfo",
"syncs": [ "Git Commits", "Git Files" ]
},
{
"url": "https://github.com/xmasdev-2022/xmaze-api",
"syncs": [ "Git Files"]
}
]
}
where there is:
-
url: repository absolute URL -
syncs: an array with the names of the synchronization types to enable on the repository (here you can find other types)
However, I would like to integrate in the next few days the association of a GitHub Personal Access Token (PAT) to enable all possible types of indexing 💡.
Final steps
The last step is to export the database and upload it as an artifact on GitHub. In this case too, there were many ways to perform the dump... from using GitHub Actions available on the Marketplace or using command line and exporting plain scripts or gzip compressed tarballs. I chose to use pg_dump which is directly available inside the PostgreSQL container and export a dump in custom archive compressed mode.
docker exec -i postgres pg_dump -U postgres -Fc -Z 9 postgres > backup_mergestat.dump
where:
-
-U: username parameter -
-Fc: custom archive output -
-Z 9: maximum compression
In conclusion, we upload the artifact to GitHub and shut down all the containers.
Don't miss out on next blog post, where we'll explore how to set up Codespace to get all the tools you need for analysis.
Stay tuned!

Top comments (0)