In part 1 I showed how I leveraged event storming to map out the whole flow for my personal financial health maintenance “domain”, identified major sub-domains and mapped them to bounded contexts, drilled in deeper into process and design level event storming to enrich the storm with commands, read models, policies and systems.
In this final part, I will review the current domain model for the Budgeting and Expense Tracking bounded context, explore alternatives and make some model improvements keeping in mind the outcome of the design level event storm. Finally I will end with some DDD takeaways that should be applicable generally.
Budgeting and Expense Tracking Domain Model with Aggregate
From the process level event storm, three different things have emerged: budget, pot and expense. Budget is opened first, then pots are allocated in that budget, then expenses are recorded (or reversed) against those pots and then eventually the budget reaches its end date and is closed, all based on some constraints that must be met. Each budget has a lifecycle of about a month (called a “Period”) and at the end of that period, no more changes are allowed to the budget i.e. it, all the pots and expenses in it, become immutable.
“Pot” is just the name I chose for expense categories because in ancient times money would often be stored in earthen pots and jars – just my ubiquitous language
The flow is strongly unidirectional i.e. open budget -> pot -> expense -> close budget where each step depends on the step before it and the constraints in each step often come from the step before it. So even though the terminology switches from budget to pots to expenses, because of the strongly interdependent and related nature of the flow it makes sense to keep all of those steps in one bounded context.
Based on this thinking I created an aggregate that looks like this:
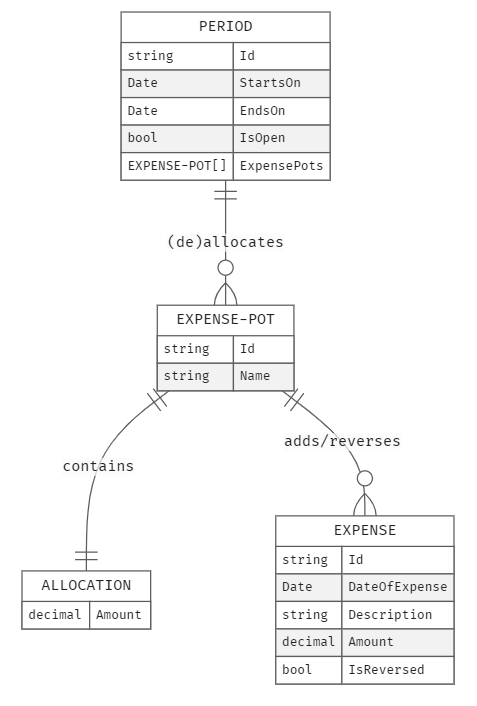
Current domain model
A Period can allocate one or more Pots and one or more Expenses can be added or reversed against each Pot. Period is at the root of this aggregate, meaning, any and all changes to the state of any and all constituent entities can only be made via the aggregate root. As an example:
Role of an Aggregate
A DDD aggregate is often a confusing and a misinterpreted idea and much has been talked and discussed about it so I am not going to redefine it, but I will attempt to describe how I understand it.
An aggregate is a logically related cluster of objects that exposes certain domain behaviour(s) and enforces invariants i.e. constraints that should hold true for all objects in a group, for all state changes done to them. These are checks that prevent invalid state transitions for a given object.
It also allows me to reduce the exposed API surface area of the aggregate and minimise out of band changes that could compromise the integrity or validity of the aggregate. The root object doesn’t have to do everything itself or know how everything will be done, it delegates to the child objects in its graph. For example, the Period object doesn’t know or care exactly how an expense is added, it delegates that to the Pot object. The Pot object knows how to record the expense correctly, and to ensure no shortcuts around the Period object are possible, methods in the Pot object are marked as internal. Once expense is successfully added i.e. no exception gets thrown, the root object will then execute post-conditions e.g. updating the remaining allocation on the pot or anything else it might need to do. Bypassing the root will compromise these checks and the integrity of the aggregate.
Some of the most useful design heuristics/constraints for an aggregate that I have come to understand are:
- It should have invariants that need to be enforced for the whole aggregate, e.g. if I have one or more expenses recorded against a pot, I am not allowed to deallocate that pot or I am not allowed to add an expense if its date is outside the period date range. So these become invariants that I will enforce via the Period aggregate root because it is the only entry point into the aggregate.
Another example of this could be a purchase order with many purchase order lines, say the overall value of a purchase order should be limited to some threshold based on what type of product is being ordered and you want to enforce this limit. Then, the PO aggregate will be retrieved each time you want to add/modify a line to it to make sure the invariant of max value limit (price x quantity), is enforced across all the lines and the change rejected if the invariant is broken. In this case we are trading off performance for correctness and reliability.
Its also possible that there are no aggregate spanning invariants like the value one here, but there are local invariants specific to an object in the aggregate e.g. price corrections on a given purchase order line are only allowed between the range of $10 and $100, in this case, it might not make sense to pay the cost of retrieving a potentially large aggregate so it might be more acceptable to retrieve the target line and make changes to it. You still want to make sure that the the line object is responsible for making changes to its own state based on these constraints, we are only foregoing the one-to-many nature of a purchase order for performance reasons, not foregoing encapsulation of state and behaviour on each object.
- An aggregate must be transactionally consistent i.e. all changes made to the aggregate in a single flow/use case, MUST all be persisted successfully or they should all fail (i.e. atomicity) otherwise the aggregate will have data consistency issues. Using our purchase order aggregate example, if I add/modify multiple purchase order lines for a given purchase order, I am expecting all these changes to succeed or all of them to fail so that the end state of the system is consistent. The key influencing factor for this requirement is preserving the symmetry between invariant enforcement and ultimate persistence of valid changes. In other words, if all the invariants for the modified objects have been satisfied, then they should all be made durable successfully or they should all fail, otherwise the invariant enforcement is of little value if the end state of the system is still inconsistent such that subsequent invariant checks might fail again.
You can always break apart the aggregate where transactional consistency and invariant enforcement are not needed, and accept eventual consistency instead.
- Because the whole aggregate needs to be retrieved from persistence in order to enforce invariants, aggregates must be small enough to not impact data access performance negatively. Just because there is a one to many relation between objects/entities, doesn’t always mean that’s a good aggregate e.g. order and order lines have a natural one to many relation but an order can have thousands of order lines, which could make it a poor aggregate from a performance pov. Pulling thousands of objects (or more) every single time from the database could hurt performance of the system for no benefit to the consistency of the model. Yet, if there are aggregate wide invariants to be enforced we might take the performance hit, its a trade-off, though at that point we might also want to improve the design of the aggregate.
Of course persistence will become tricky the more objects in the aggregate are modified in one transaction, you’d need to know what’s changed in order to atomically commit the changes correctly. Most ORMs like Entity Framework, might do this change tracking heavy lifting for you and that could ease up persistence concerns, with the trade-off that you become dependent on an external framework for your domain model to work efficiently. This is also why small aggregates are preferred.
- An aggregate doesn’t necessarily have to mean one object containing an
IListof other objects so to speak, it could also be a composition of smaller singular objects. The whole object is still an aggregate if it matches the above criterion. - Two aggregates are independent from each other from a transactional consistency pov i.e. each can fail independently. Each is immediately consistent with respect to itself but eventually consistent with respect to the other.
- An aggregate is only allowed to refer to another aggregate by the id of its root, in other words, its not allowed direct reference to the internal objects of another aggregate. This is because if the internals change, that can leave multiple objects in a system broken or inconsistent.
Reviewing the Period Aggregate
The first thing that I avoided pointing out until now, is the mismatch in naming of the aggregate root between the event storm and the actual aggregate model. The event storm captured the ubiquitous language and used the term “budget”, whereas in code I used the very generic and obfuscated term “period”. So that’s Improvement number 1 I made. It required quite some refactoring across the whole system as I made names consistent everywhere but this was an important change.
From here on out I will use the ubiquitous term “budget” to indicate the finite time period within which I create pots and record expenses.
Next, I checked this budget aggregate against the constraints that I laid out above:
Invariants
There is a global invariant that applies to all state transitions within the aggregate: the budget should still be active (i.e. not closed) at the time of desired state change. Then there are behaviour specific invariants
- Opening a budget : dates must be in the future, not past
- Closing a budget : budget can only be closed a day prior to its end date and only if its not already closed. Like I said before, closed budgets are immutable, i.e. I cannot allocate pots or add expenses to them. They are done!
- Allocating a pot/deallocating a pot : pot cannot be deallocated if it has one or more expenses against it.
-
Recording expenses: expense date for all expenses should fall between the budget date range and expense amount shouldn’t be negative. Remaining allocation for the pot should be reduced by the expense amount such that,
remaining allocation + sum(expenses in this pot) = total allocationin this pot, this is also potentially an invariant because it indicates a relation or a constraint at the pot level that should hold true for all expenses in that pot. - Reversing expenses: Same as recording expenses from the pov of updating remaining allocation, so an invariant at the Pot level.
Transactional Consistency
All the above state changes are persisted atomically to ensure consistency but each state change typically only involves a single object in the aggregate. This is because the changes are not all made in one go i.e. budget opening, pot allocation, expense adding etc can’t happen in one go because I may not know what pots I will allocate before hand, I will definitely not know what expenses I will make before hand. These operations are spread out over the period of a month or more. So the scope of the transaction is often restricted to a single object at a time which keeps transactions and database locks, short and quick.
These kinds of insights come from talking to the domain experts and understanding the business process. As developers we’ve been indoctrinated into ACID properties, so we are driven to force ACID on every little operation. If the business process is eventually consistent or can be eventually consistent without negative impact to the business, don’t force ACID on it. If all you have is a hammer…and all that!
Another example of applying appropriate technical solutions to solve a business problem instead of forcing out of band technical decisions on the business, my domain model has no concurrency handling mechanism implemented for the aggregate. This is because there are only 2 users so its easy to ensure only one is using the system at a time to avoid contention. Granted, no body else gives a shit about my application and its a tiny little pet application, but then that’s all the more reason for me to go crazy and implement all sorts of cool things as an engineer. I don’t!
Aggregate Size
How about the size of the aggregate? Well, for my personal expense tracking application, a budget can realistically only contain less than a dozen or so pots (p) and each pot will typically contain less than a hundred expenses often even less than 50 (e), so the overall cyclomatic complexity will be: 500 <= O(p.e) <= 1000objects retrieved if I retrieve the whole aggregate. From experience of running the application for the past 5 years with this model, I can tell that retrieval performance has not been a problem. Most queries are in single digit milliseconds.
Of course, there is no hard limits on these so if “p” and/or “e” increase enough for performance to be a bottleneck, I will have to remodel. If the read performance is to be improved I might create dedicated read only models with the possibility that they will be eventually consistent. Once again its trade off between: slow and immediately consistent vs fast and eventually consistent
Alternate Models I Considered
There is almost never just one true model that will always work for all kinds of problems, there are usually multiple models that we need to consider to identify which one fits our problem the best.
“Nothing is more dangerous than an idea when it is the only one you have.”
Emile Chartier Alain
To that end, let me sketch out couple of alternative models that I considered, and see how the dynamics of invariants and transactional consistency look for each:
Budget and Pot Aggregates

Separate Budget and Pot aggregates
In this model, budget and pot are separate aggregates because most of the budget level state changes are constrained by invariants in the budget itself. They have no bearing on the rest of the aggregate. So separating budget into its own albeit very small aggregate, might make sense.
Pot and expenses seem more cohesive together, there are invariants (like the deallocation one), where a pot needs to know how many expenses its recorded so it might make sense to put them together into another aggregate.
However, Pot (de)allocation and expense recording also require the budget to be active i.e. the global invariant but since the aggregates are now separated, the most Pot can do is reference BudgetId (id of the aggregate root) and hope that the budget is active when the state changes are being performed. There is no easy way to guarantee that the referenced budget is active and what’s worse, is that the invariant enforcement starts to move out of the objects and into some kind of service class (see example below). The more we break up the aggregate, the worse this leakage gets.
For comparison sake, here’s the service class code for the currently implemented budget aggregate model, for adding a new expense. Notice the reduced branching complexity due to all the major invariants being enforced inside the Budget object (ignoring the comment):
Performance wise also it doesn’t win much since in order to use the system effectively, the whole budget (with pots and expenses) have to be retrieved anyway. Also if the number of expenses are sufficiently high, even with a smaller aggregate, retrieving expenses will still be slower. Sure, we can split the retrieval across all 3 objects and do on demand loading with paging etc but this model still leaves something to be desired. The interaction complexity between the aggregates goes up with eventual consistency being introduced in a place where it doesn’t naturally fit (see the event storm).
Budget and Expense Aggregates

Separate Budget and Expense Aggregates
This model is similar but gets even more complex, in order to make sure expense is recorded against the right active budget and pot, the expense aggregate needs to reference both PotId and BudgetId. In order to satisfy the deallocation invariant, Pot needs to keep a collection of ExpenseId. The same problem of leaking invariant enforcement still exists in this model, just a lot worse and also since the transactional consistency boundaries are split up, both these aggregates can fail independently which could introduce data consistency issues where there were none.
Budget, Pot and Expense Aggregates

Each object is its own aggregate
In this model, each object is its own aggregate referencing each others’ ids, with transactional consistency only limited to one object at a time and eventual consistency across aggregates. Enforcing invariants is fully leaked out to the service class because the domain objects don’t have much behaviour to speak of and not enough state to do enforcement, meaning a lot of communication and coordination overhead between aggregates. This makes the code a lot more difficult to reason about, its almost akin to the entity service anti-pattern.
Whilst its entirely possible to adopt any one of these models to solve the problem of budgeting and expensing, none of them are necessarily wrong, but each of these alternates make invariant enforcement more difficult and complex, and that defeats the point of an aggregate. If these objects don’t have any behaviour nor are there any invariants to be enforced, then they could simply be treated as anaemic entities in a CRUD style application using the TRANSACTION SCRIPT pattern.
⚠️⚠️⚠️Anaemic model should almost never be the starting point, effort should instead be put in identifying behaviour and invariants and capturing those in an expressive domain model. Only when its abundantly clear that no behaviour or invariants exist and its just data shovelling, should an anaemic model be adopted.
Improvements Made to the Budget Aggregate
Having gone through the alternates and seeing their weaknesses, I decided not to change the current model that fits better to the problem at hand. However, this whole exercise made me challenge all my assumptions about the system, domain and the practice of DDD, so I did come away with improvements that I made to the budget aggregate model.
Improvement 1: Make the domain model follow the ubiquitous language
Renaming Period to Budget and other changes to align with the ubiquitous language discovered in the event storm, like mentioned before. Thinking about it now, I should have always stuck with Budget not really sure why I chose Period back in the day to refer to budget, its very generic and vague.
One other improvement I can see based on DDD recommendation is, instead of Budget, the phrase MonthlyBudget will make it explicit what’s the lifecycle of this object and whilst opening a new monthly budget, the correctness can be enforced by controlling how dates get assigned. One for later!
Improvement 2: Get rid of fake invariants
First off, the purpose of the “remaining allocation” invariant was not clear. Looking at the code, the only place it was used was in the frontend applications for display purposes. There is no other case that I discovered in the event storm that highlighted the need for such an invariant. What’s more is that this computed value was stored in the database so it doesn’t have to be computed again and again.
Calculating this value is not complex or performance intensive but more importantly, I shouldn’t be creating aggregated values for display purposes in the domain model. Domain model should be presentation agnostic, this value can be calculated on the edges of the system: REST API or frontend, and that will allow me to get rid of this fake invariant from the aggregate. So that’s another change I made, got rid of this remaining allocation “invariant”, updated the frontend to calculate this value from raw allocation and spend values, removed the corresponding properties from the aggregate entirely and ultimately, dropped the column from the database table. Good win!
The current model also computed the total saving after closing the budget, and stored (or posted) these savings back to the database and once again, this responsibility was better handled in the summarisation bounded context because the total savings for the closed budgets was once again only used to display closed budget summary on the frontend. So that’s another bit of accidental complexity I removed from the aggregate and dropped another database column.
Improvement 3: Make Bounded Contexts Clear in Modular Monolith
Next thing looking at the event storm that hit me was there were 3 clear bounded contexts yet in the monolithic code, it was difficult to find these bounded contexts.

Solution structure (before)
Bounded contexts boundaries often indicate module boundaries and in a monolithic system, its important to surface these modules to make the boundaries clearer. This allows for future evolution into a more distributed design where each of these modules could become an independent deployment unit, should the need arise. Taking a first crack at making the monolith more modular, I created the following structure:
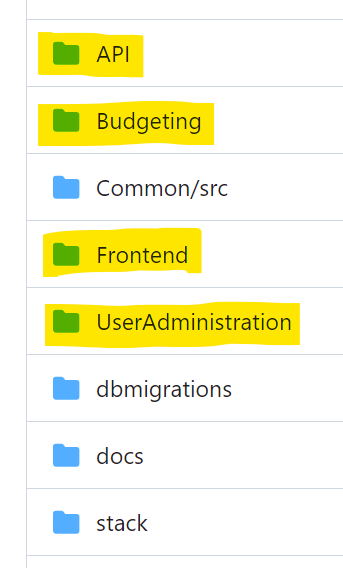
High level modules i.e. bounded contexts (after)
Ok, API and Frontend are not quite modules strictly speaking but they do represent entry and exit points in the system. Budgeting and User Administration modules map to the bounded contexts in the event storm. The one “missing” is Summarisation module, but for now I decided to keep it co-located within the Budgeting module, I shall pull it to the top soon.
Another benefit to this modularisation is that when I am working on one module, I don’t have other modules in my way. Its literally harder to navigate to a whole another project to get to another module than it is to navigate to another namespace in the same project, more clicks! 😉. I can therefore focus on one module that I am working on and keep all its context in my head.
I also made these modules almost plug and play by introducing DI hooks, that way if I don’t register a module into my main API, it wouldn’t be used. Each DI hook takes the responsibility of registering all components required for that module to work.
Then in order to plug this module into my main API:
This makes the overall modular structure and direction of dependencies clearer:

Whether or not it will be as easy to pull out “microservices” from this kind of a structure in general as I think or if the DI hook type design is robust, is still to be seen because this is still something I am settling into and still trying out different structures.
Improvement 4: Implementing Domain Events
The event storm also highlighted key domain events in the Budgeting and Expense Tracking context that I never captured in code before. When I first thought about adding these to the code, I almost went the whole hog with implementing TRANSACTIONAL OUTBOX pattern to store emitted domain events durably. That way I could publish them outside of the bounded context whenever I wanted. However, realising that at the moment aside from Budget Summarisation context, there is no other consumer for these events (and likely never going to be) and the fact that Budget Summarisation context needs some more refinement as to is current and future capabilities, I decided that I am not going to implement the TRANSACTIONAL OUTBOX pattern and avoid that architectural complexity and cost.
But what I did decide to do was model these events in the domain code so I can at least capture them when the state changes and verify them in tests. For now these events will not be durable because they will just stay in memory as long as the aggregate stays in memory, but that helps me amortise the cost of event implementation over a period of time.
In order to record these events in the aggregate, I made the aggregate root responsible for keeping a track of all events in memory:
The advantage of this approach is that the recorded events are colocated with the aggregate, meaning they are agnostic to publishing strategy, I can either publish them right away after the state change (this is less reliable because database update and event publishing are not atomic), or I can implement TRANSACTIONAL OUTBOX and store the events in the database durably and atomically, and publish them later. This approach is also a lot cleaner i.e. if you believe domain events should be treated as a first class part of the domain model.
I have documented some lessons architecting event driven systems here and here, might be worth a look because I am not going to go in more details here.
This is not the end of the improvements, DDD is a process of continuous learning so I am sure in a few months, I might revisit the domain model again as my understanding of DDD and the system design evolves, and see more areas of improvement. For example, Budget Summarisation context is something that I have not really put a lot of effort into due to my reporting needs not being too complex at the moment but that could be the next thing I will want to look at in order to realise the overall goal. I also have to revisit all my primitive types and see where the model can benefit from Value Objects, though there is nothing wrong with using primitive types where it makes sense.
Takeaways
- Taking a database centric view of the system is likely going to result in unwieldy code that doesn’t capture the domain behaviour and doesn’t speak the language of the domain. What’s worse, you as an engineer aren’t going to be able to speak the language of the domain. Having to constantly translate between tech and business contexts leaves room for total misinterpretation and assumption, and this is where most complexity in software comes from. Learning the business domain and engaging with the domain experts regularly to sharpen your domain language is crucial, you will view code a lot more differently.
- Approaching DDD from a purely tactical point of view i.e. jumping straight into entities, value objects, aggregates or repositories (like I did years ago), is likely to put you at odds with your business’ value streams and the models you create are likely to be either over-engineered or under-engineered. They might not use the ubiquitous language and you are going to miss out on a whole bunch of business concepts that gives your model meaning, and this at best creates fake and anaemic domain models with very little behaviour and invariant enforcement, primitive obsession and general lack of expressiveness. Nothing wrong with it if that’s how you want to build software, but I believe we can do better than that.
- If you are going to “do DDD”, I very much recommend starting from the strategic part of DDD: exploring the business flows collaboratively with domain experts with big picture event storming, identifying/clarifying potential sub-domains/bounded contexts (be prepared to get these wrong in the first few attempts), drilling deeper into Process and Design Level Event Storming to identify potential commands, data, systems and aggregates, creating context maps to identify relationships between bounded contexts. From these you will be better able to distil the model in code that is aligned with the business flows and ubiquitous language. You don’t have to use all the tools DDD has to offer all the time, and you don’t have to have used all of them upfront before you code. Often you are going to have to apply strategic DDD and tactical DDD iteratively in order to implement, learn and improve (or red, green, refactor if you will). Practices like TDD can also work really well to incrementally improve the model.
- Aggregate design should try to strike a balance between invariants that need to be enforced, transactional consistency requirements and performance of the aggregate. Splitting an aggregate too much might make invariant enforcement more complex and domain objects potentially anaemic, and vice-versa, very large aggregates could present performance bottlenecks yet add no value, if there is no behaviour in them or no invariants to enforce.
- There is no single perfect model, there are just different models for different purposes. A good enough model will almost never be arrived at in one go or linearly, the process of exploration and discovery is divergent and that’s where insights come from. Don’t stop at the first model you create, explore alternatives even if to discard them and sticking with the original implementation (like I did here). At least you’d have made the decision deliberately and you will have generated ideas for the future.
- Doing an event storming and identifying domain events doesn’t always mean implementing all of those in code. Sometimes we use events to help us reason about the business process but the real life artifact might just be a database table (i.e. read model) that you read frequently. You might want to capture the important domain events in code upfront but instead of publishing them right away, just record them transiently in memory (like I did here). The need to trigger multiple business processes downstream, or to reduce temporal coupling, and/or generating analytical insights from critical domain events, are usually the triggers I look for to publish events outside the bounded context. Until then they are internal events.
- Embrace eventual consistency, its the natural order of things but drop it where it doesn’t fit. If your stakeholders’ mental model and the problem space isn’t naturally asynchronous, the smallest of eventual consistency can be seen as a problem. If the problem space is naturally asynchronous or can tolerate eventual consistency without negative impact to the business process, embrace eventual consistency with both hands.
- Using DDD need not result in microservices, its more important to identify boundaries instead and create a model that aligns with the business process and solves that business problem. Then you can start with a modular monolith and microfy it when there are strong enough drivers for it.
- You cannot do DDD once and be done with it any more than you can write code once and be done with it, its a continuous learning and improvement process. The more you think about your domain and system, the more questions you will have and resolving those questions with domain experts will often result in new insights that can help improve the system design just that much more. Most important improvements come not from one or two large scale design changes, but from small and continuous changes (this is how biological evolution works, all the complexity and highly optimised/adapted species we see wasn’t a result of one or two large scale changes but millions of micro-increments over a long time). I was wholly confident during this exercise that I will happen upon some genius insight that will improve the system design by leaps and bounds, but look at the scale of changes: renames, removing some code and data, restructuring the solution.
Hope you found that somewhat useful, if tiring. 





Top comments (0)