In this post, I will share my experiences leveraging Domain Driven Design strategies and Team Topologies to reorganise two product engineering teams in the Purchasing domain at Coolblue (one of the largest e-commerce companies in the Netherlands), along business capabilities to improve team autonomy, reduce cognitive load on teams and improve our architecture to better align with our business.
Disclaimer : I am not an expert in Team Topologies, I have only read the book twice and spoken to one of the core team members of Team Topologies creators. I am always looking to learn more about effectively applying those ideas and this post is just one of the ways we applied it to our problem space. YMMV!🙂
Context
Purchasing domain is one of the largest at Coolblue in terms of the business capabilities we support and the number of engineering teams (4 as of this writing, possibly growing in the future) and it has one very critical goal: to ensure we have the right kind of stock available to sell in our central warehouse at all times without over or under stocking and secure most optimum vendor agreements to improve profitability of our purchases. Our primary stakeholders are supply planners and buyers in various product category teams that are responsible for various categories of products we sell.
We buy stock for upwards of tens of thousands of products to meet our growing customer demands, so its absolutely critical that not only we are able to make good buying decisions (which relies on a lot of data delivered timely from across the organisation) but that we’re also able to manage pending deliveries and delivered stock efficiently and effectively (which relies on timely and accurate communications with suppliers).
Growth of the Purchasing Domain
Based on the strategic Domain Driven Design terminology Purchasing would be categorised as a supporting domain i.e. Purchasing capabilities are not our core differentiator. The workings of the domain are completely opaque to end customers. Most organisations will have similar purchasing processes and often similar systems (sometimes these systems are bought instead of being built).
However, over the last 10 years Purchasing domain has also increased in complexity, we have expanded our business capabilities: data science, EDI integration, supplier performance measurement, stock management, store replenishment, purchasing agreements and rebates etc. We have come to rely on more accurate and timely data to make critical purchasing decisions. Being able to quickly adapt our purchasing strategies during COVID-19 helped us stay on our business goals. For the most part we have built our own software due to the need to tackle this increased complexity, maintain agility in the face of global upset events and to integrate with the rest of Coolblue more effectively and efficiently. The following sub-domain map shows a very high level composition of the Purchasing domain:
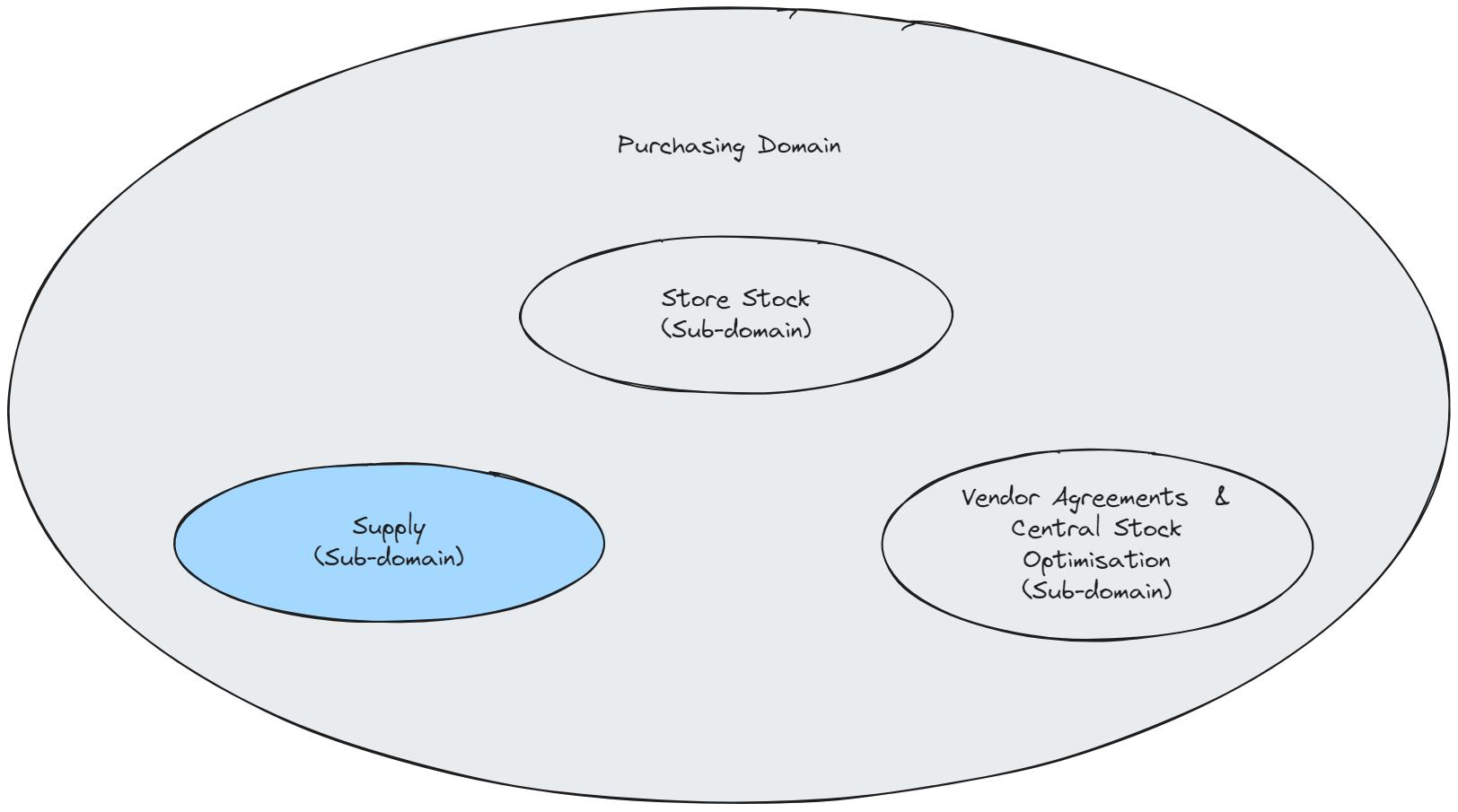
High level break down of the Purchasing domain (simplified)
For this post, I will be focussing on the Supply sub-domain (shown in blue above) where we redesigned the engineering team organisation.
Domain vs Sub-Domain vs Bounded Contexts vs Teams
In DDD terminology, a sub-domain is a part of the domain with specific logically related subset of overall business responsibilities, and contributes towards the overall success of the domain. A domain can have multiple sub-domains as you can see the above visual. A sub-domain is a part of the problem space.
Sometimes it can be a bit difficult to differentiate between a domain and a sub-domain. From my pov, its all just domains. If a domain is large and complex enough, we tend to break it down into discrete areas of responsibilities and capabilities called sub-domains. But I don’t think this is hard and fast rule.
A bounded context is the one and only place where the solution (often software) to a specific business problem lives, the terminology captured here is consistent in its usage and meaning. It represents an area of applicability of a domain model. E.g. Supplier Price and Availability context will have software systems that know how to provide supplier prices and stock availability on a day to day basis. These terms have an unambiguous meaning in this context. The model that helps solve the problem of prices and stock availability is largely only applicable here and shouldn’t be copied in other bounded contexts because that will duplicate knowledge in multiple places and will introduce inconsistencies in data leading to expensive to fix bugs. Bounded contexts therefore provide a way to encapsulate complexities of a business concept and only provide well defined interfaces for others to interact with.
In an ideal world each sub-domain will map to exactly one bounded context owned and supported by exactly one team, but in reality multiple bounded contexts can be assigned to a sub-domain and one team might be supporting multiple bounded contexts and often multiple software systems in those contexts.
Here’s an illustration of this organisation (names are for illustrative purposes only):
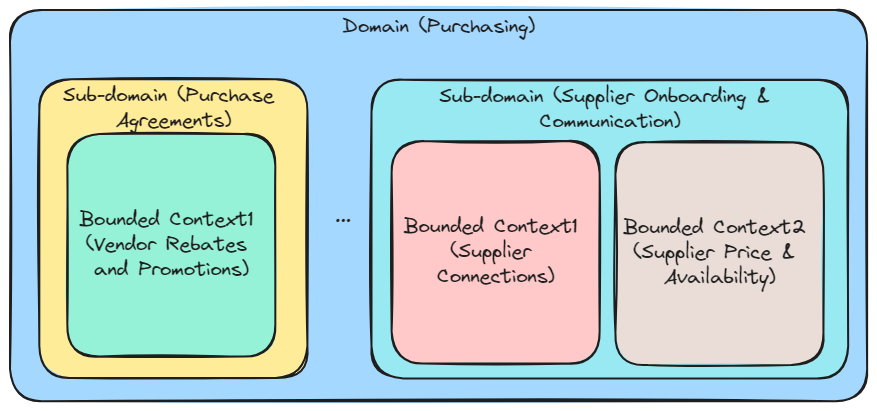
An illustration of relationship between domain, sub-domain and bounded contexts (assume one team per sub-domain)
I am not going to go into the depths of strategic DDD but here are some excellent places to study it and understand it better. The strategic aspects of DDD are really quite crucial to understand in order to design software systems that align well with business expectations.
Old Team Structure
Simply put, the Supply sub-domain is primarily responsible for creating and sending appropriate purchase orders for products that we want to buy, to our suppliers, and managing their lifecycle to completion. There are of course ancillary stock administration related responsibilities as well that this sub-domain handles but not all of those software-ified…yet.
Historically, we had split the product engineering teams into two (the names of the teams should foreshadow the problems we will end up having):
Stock Management 2 : responsible for generating automated replenishment proposals and maintaining pre-purchase settings, and
Stock Management 1 : responsible for everything to do with purchase orders, but also over time responsibilities of maintaining EDI integration and store replenishment also fell on this team.
Both teams though had a separate backlog, they shared the same Product Owner and the responsibilities allocated to the teams grew…”organically”, that is to say, the allocation wasn’t always based on team’s expertise and responsibility area but mostly based on who had the bandwidth and space available in their backlog to build something. Purely efficiency focussed (how do we parallelise to get most work done), not effectiveness focussed (how do we organise to increase autonomy and expertise, and deliver the best outcomes for the business).
Because of this mindset, over time, Stock Management 2 also took on responsibilities that would have better fit Stock Management 1 e.g. they built a recommendation system on top of the purchase orders, something they had very little knowledge of. They ended up duplicating a lot of purchase order knowledge in this system – they had to – in order to create good recommendations. This also required replicating purchase order data in a different system which would later create data consistency problems.
As a result, dependencies grew in an unstructured and unwanted ways e.g. a lot of database sharing between the two teams, complex inter-service dependencies with multi-service hops required to resolve all the data needed for a given use case. The system architecture also grew “organically” with little to no alignment with the business processes it supported and the accidental complexity increased. Looking at the team names, no one could really tell what either teams were responsible for because what they were responsible for was neither well documented nor stable.
We ended up operating in this unstructured way until July 2023.
Trigger for Review
The trigger to review our team boundaries came in Q1 2023, when we nearly made the mistake of combining two teams into one single large team with joint scrum ceremonies with a proposal to add more process to manage this large team (LeSS). None of it had taken into account the business capabilities the teams supported or the desired state architecture we wanted. It was clear that no research had been done into how the industry is solving this problem, and it was being approached purely from a convenience of management pov.
Large teams, specially in a context that supports multiple business processes, is a bad idea in many ways (some of these are not unique to large teams):
- Large teams are expen$ive, you’d often need more seniors on a large team in order to keep the technical quality high and technical debt low
- No real ownership or expertise of anything and no clear boundaries
- Team members are treated as feature factories instead of problem solving partners
- Output is favoured over outcomes, business value delivered is equated to story points completed
- Cognitive load and coordination/communication overhead increases
- Meetings become less effective and people tend to tune out (I tend to doodle geometric shapes, its fun !😉)
- Product loses direction and vision, its all about cramming more features which fuels the need to make the team bigger. Because of course, more people will make you go faster…NOT!
- Often more process is required to “manage” large teams which kills team motivation and autonomy
This achieves the exact opposite of agility and we saw these degrading results when for a brief amount of time we experimented with the large team idea.
- Joint sessions were becoming difficult and inefficient to participate in (not everyone can or will join on time)
- Often team members walked away with completely different understanding and mental models which got put into code 😱.
- Often there was confusion about who was doing what which increased the coordination overhead
- Given historically the two teams had been separate with their own coding standards and PR standards, there often was friction in resolving these conflicts which slowed down delivery and reduced inter team trust.

Communication overhead grows as number of people in the group increases
The worst part of all of this is learned helplessness! We become so desensitised to our conditions that we accept it the sub-optimal conditions as our new reality.
So combining teams and adding more process wasn’t going to be the solution here and it most certainly shouldn’t be applied without involving the people whose work lives are about to be impacted i.e. the engineering teams.
These reorganisations should also not be done devoid of any alignment with the business process because you risk system architecture either not being fit for purpose or too complex for the team(s) to handle because all sorts of assumptions have been put into the design.
Team Topologies and Domain Driven Design
I had a feeling that we needed to take a different approach here and by this time I had been hearing a lot about Team Topologies so I bought the book (highly recommended), and read it cover to cover…twice…to understand the core ideas in it. A lot of people know about Conway’s Law but Team Topologies really brings the double edged nature of Conway’s Law into focus. Ignore it at your own peril!
This Comic Agile piece sums up how that realisation after reading TT book, dawned on me:

Check out more hilarious strips here
Traditionally, team and domain organisation in most companies, has been done by business far removed from the engineering teams, meaning they miss out a critical perspective in those discussions: that of the system architecture. And because the team design influences software design, many companies end up shooting their foot with unwieldy and misaligned software that delivers the opposite of agility. This is exactly why its crucial to have representation from engineering in these reorganisations. Just because something works doesn’t mean, it’s not broken!
By this time we had also conducted several event storming sessions for the core Supply sub-domain (for the entire purchase ordering flow) to identify critical domain events, possible bounded contexts and what we want our future state to be. I cannot emphasise enough how important this kind of event storming can be in helping surface complexity, potential boundaries and improvement opportunities to the current state.
Putting Team Topologies and strategic DDD together to create deliberate team boundaries was just a no-brainer.
Don’t worry, you are not meant to read the text, the identified boundaries are more important
Also worth bearing in mind that this wasn’t a greenfield operation, we had existing software systems that had to be mapped onto some of the bounded contexts, at least until we can determine their ultimate fate. Some of the bounded contexts had to drawn around those existing systems to keep the complexity from leaking out to other contexts.
Brainstorming on New Team Design
In May 2023, I, our development lead and our domain manager got to brainstorming on how can we organise our teams not only for efficiency but this time crucially also for effectiveness.
In these discussions I presented the ideas of Team Topologies and insights from the event storms we had been doing. According to Team Topologies, team organisations can essentially be reduced to the following 4 topologies:
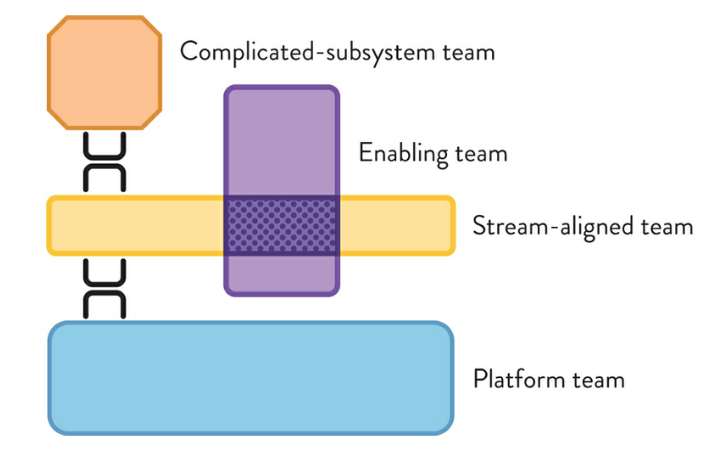
Four fundamental topologies
Based on these and my formative understanding, I presented the following team design options:

The 2 team model
This model makes the Purchase Ordering team (stream aligned) solely responsible for full purchase order lifecycle handling, including the replenishment proposals (which is an automated way to create purchase orders). The Pre Purchase Settings team (platform team) will provide supporting services to the PO team (e.g. supplier connectivity and price & availability services, purchase price administration services, various replenishment settings services etc).
Another model was this:
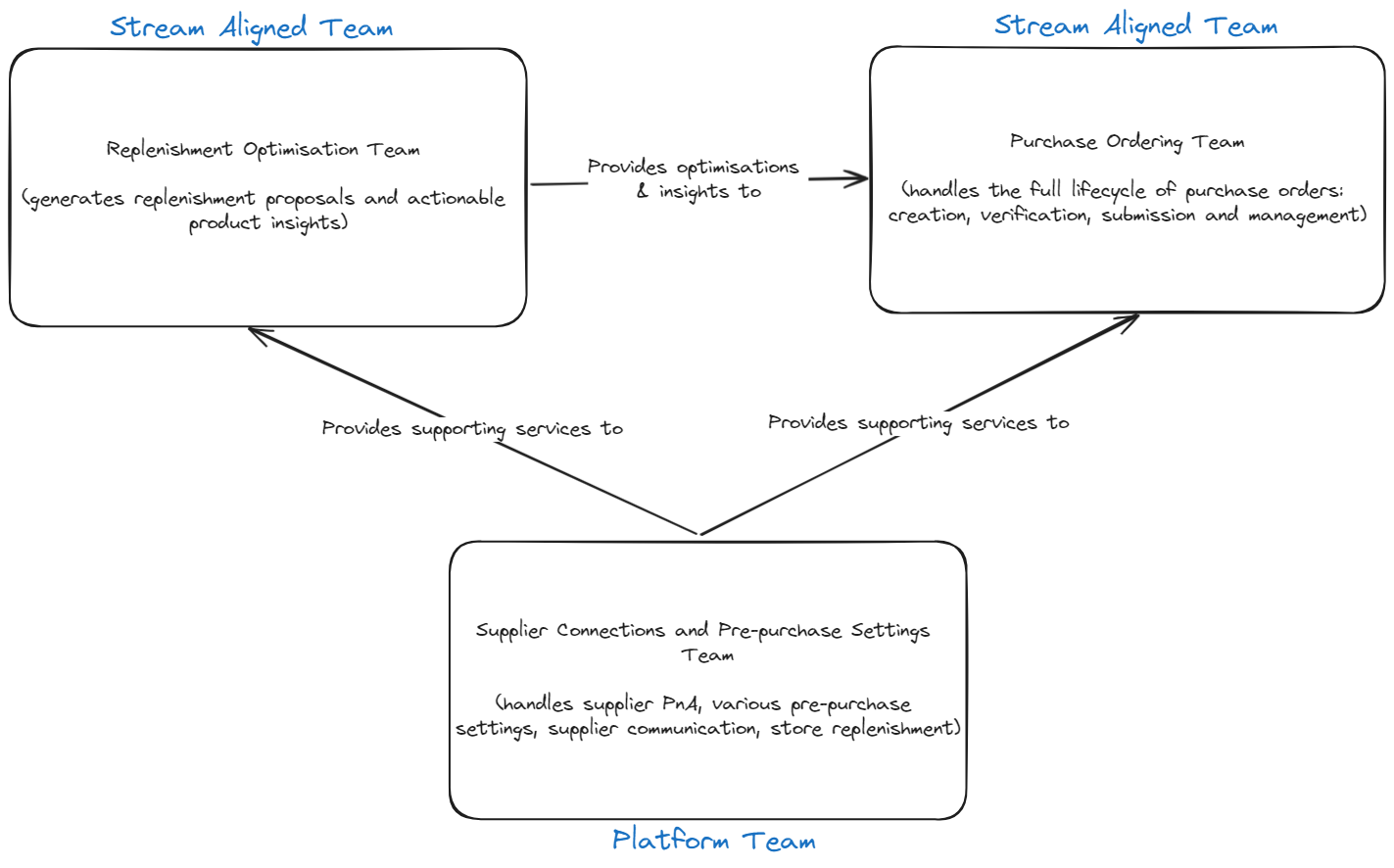
The 3 team model
In the 3 team model, I split out the replenishment proposals part out of Purchase Ordering team, added the new actionable products capability that we were working on, to it and created another stream aligned team: Replenishment Optimisation Team. The platform team will now provide supporting services to both these stream aligned teams and the new optimisation team will essentially provide decision making insights to purchase ordering team.
In a perfect world, you want to assign one team per bounded context and as evident from the event storm we had several contexts, but Team Topologies also warns us to make sure the complexity of the work warrants a dedicated team. Otherwise, you risk losing people to low motivation, and still bearing the cost of creating multiple teams.
Nevertheless, after taking into account the practical constraints like money, complexity and team motivation but perhaps most importantly taking into account the impact of each design on the overall system architecture and what we wanted our desired state architecture to look like, we settled on the following cut:
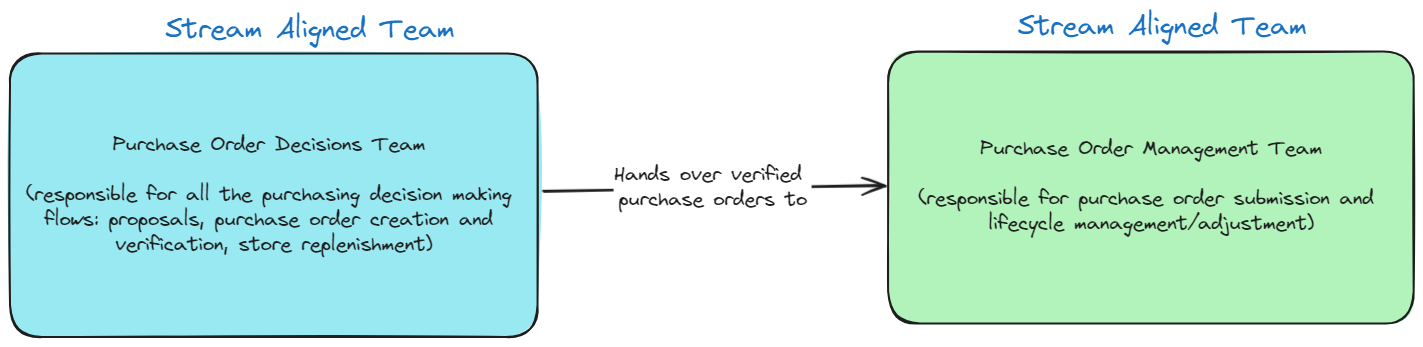
Final team split
Basically, at their core, the Purchase Order Decisions team will own all components that factor into purchasing decision making:
- Replenishment recommendation generation
- Purchase order creation and verification
- Actionable product insights
And the Purchase Order Management team will own all components that factor into the management of lifecycle of submitted purchase orders (I know “management” is a bit of a weasel word, but I am hoping over time we will be able to find a better name):
- Purchase order submission
- Purchase order lifecycle management/adjustments (manual and system generated)
The central idea behind this split being that purchase order verification is a pivotal event in our event storm and once a purchase order is verified, it will always be submitted. Submission is a key pre-condition to managing pending purchase order lifecycle and it has sufficient complexity due to communication elements involved with suppliers and our own warehouse management system, so it makes sense for Purchase Order Management to own everything from submission onwards. This also makes them the sole owner of the purchase order database and this breaks the shared database anti-pattern, and relies on asynchronous event driven communication between the bounded contexts owned by the teams. Benefit of this is that we can establish clearer communication contracts and expectations without knowing or needing to know the internals of another context.
In addition to this, we also identified several supporting capabilities/bounded contexts for which the complexity just wasn’t high enough to warrant a separate team entirely, at least for now:
- Supplier price and availability retrieval
- EDI connection management
- Despatch advice forwarding
- E-mail based supplier communication
These capabilities still had to be allocated between these two teams, so based on whether they belong more to decision making part or the management part, we created the following allocations:
- Supplier price and availability retrieval (Purchase Order Decisions because its only used whilst creating replenishment recommendations and subsequent purchase orders)
- EDI connection management, Despatch advice forwarding (Purchase Order Management because they already owned this and it definitely didn’t make sense as a part of decision making flows)
- Email based supplier communication (Purchase Order Management because purchase order submission can happen via EDI or via E-mail so it makes sense for them to own all aspects of submission)
This brought the final design of teams to this:
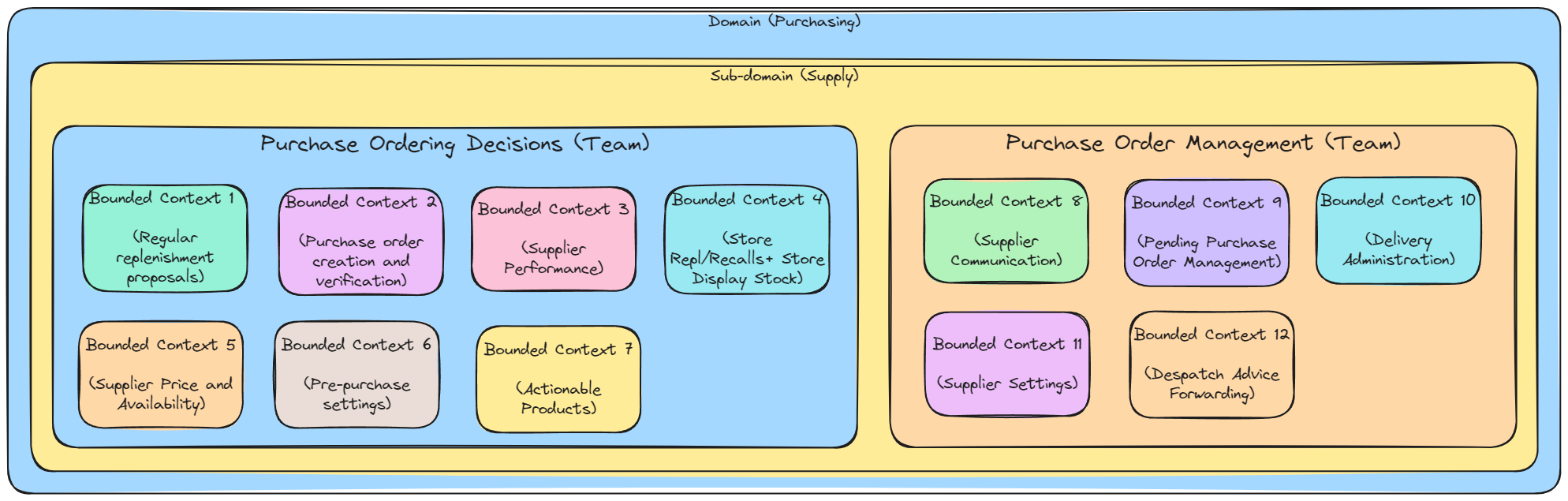
Final team cut with bounded contexts owned by each
It might seem a bit excessive to have multiple bounded contexts to a single team and like I said, in a perfect world I would have one team be responsible for only one bounded context. But considering the constraints I mentioned before (cognitive load, complexity of challenge and financial costs of setting up many teams), I think this is a pragmatic choice for now. The identified bounded contexts are also not set in stone, so its entirely possible we might combine some of them into a single bounded context based on conceptual and linguistic cohesion. We might even split them out into dedicated teams should some bounded contexts grow in complexity enough to warrant separate teams.
NB: A bounded context might not always mean a single deployment unit (i.e. a service or an application). A single BC can map to one or more related services if the rates of change, fault tolerance requirements and deployment frequencies dictate as much. The single most important thing about BCs is that they encapsulate a single distinct business concept with consistent business language and consistent meanings of terms, so its perfectly plausible that there are good drivers for splitting one BC into multiple deployment units.

Some heuristics for determining bounded contexts
Go Live!
In June 2023 we presented this design to both the teams and asked for feedback, and both teams could see the value of the split because it created better ownership boundaries, better focus and allowed opportunity to reduce the cognitive overhead of communicating within a large team. So in July 2023, we put the new team organisation live and made all the administrative changes like changing the team names in the HR systems, Slack channels, assigning right teams to code repositories based on allocations etc. and got to work in the new set up.
Reflection
Whilst this team organisation is definitely the best we’ve ever had in terms of cleaner ownership boundaries, relatively appropriate allocation of cognitive load, better sense of purpose and autonomy, its by no means the best we will ever have. The most important thing about agility is continuous improvement, DDD tells us that there is no single best model, so it only makes sense that we revisit these designs regularly and seize any opportunities for improvement along any of those axes to keep aligned with the business and deliver value effectively. The organisation and the domain never stay the same, they grow in complexity so its crucial for engineering teams to evolve along with them in order to stay efficient and effective themselves, and also for the architecture to stay in alignment with the business. I loosely equate teams and organisations to living organisms that self-organise like cellular mitosis, its the natural order of things.
Ofcourse things are not perfect, both teams still have some degree of functional coupling i.e. if the model of the purchase order changes fundamentally or if we need to support new purchase order types, both teams will need to change their systems and coordinate to some extent. This is a trade-off of this team design option, but largely the teams are still autonomous and communicate asynchronously for the most part. Any propagation of model changes can still be limited by use of appropriate anti-corruption layers on either side.
One of the other significant benefits of this deliberate reorganisation, is that in both teams we created a north star roadmap for the desired state architecture because for a long time, both teams had incurred unwarranted technical complexities in the form of arbitrarily created services with mixed programming paradigms, which were getting difficult to maintain for a small team. Contract coupling at multiple service integration points made smallest of changes ripple out to multiple systems that had to be changed in a specific order to deploy safely (we’ve had outages in the past because we forgot to update the contracts consistently).
As a part of our new engineering roadmap, we are now reviewing these services with a strategic DDD eye and asking, “what business capability this service provides?” and if the answer is similar for two services and there are none of the benefits of microservices to be gained here, then those two services will be combined into a single modular monolith. Some services will not make sense in the new organisation so they will be decommissioned and the communication pathways simplified. We project a potential reduction of 40% in the complexity of overall system landscape because of these changes (and hopefully some money savings as well), or at the very least complexity will be better contained. But perhaps most importantly, we aim to make the architectural complexity fit the cognitive bandwidth of the teams and ensuring a team can own the flow end to end.
Another thing we will be working on next is strengthening our boundaries with dependent teams, historically the e-commerce database has been shared with all the teams in Coolblue and this creates challenges (subject for another post). So going forward we will be improving our web services and events portfolio so dependents can use our service contracts to communicate with our systems instead of sharing databases. With a better sense of what we own and don’t own, I expect these interfaces to become crisper over time.
These kinds of reorganisations can have a long maturity cycle before it becomes clear whether these decisions were the right ones or the team boundaries were the right ones, and organising teams is just the first though a significant step. The key is in keeping the discussion going and being deliberate about our system design decisions to ensure that business domains and system design stay in alignment. To that end we will continue investing in Domain Driven Design practices to ensure business and engineering can collaborate effectively to create systems that better reflect the domain expectations whilst keep the complexity low and keeping acceptably high levels of fault tolerance and autonomy of value delivery.

Top comments (0)