I made an R data package to make Pokemon data more usable in R!
library(pokedex)
library(tidyverse)
library(knitr)
How many Pokemon in the package?
I’ve tried to make the data set ‘tidy’ from the start, so we can use
summarise to count them, and kable to make some dev.to friendly
markdown tables.
pokemon %>%
summarise(count = n()) %>%
kable()
| count |
|---|
| 807 |
Types
Types are pretty key to Pokemon. Lets have a quick look at the Kanto
starters and types.
pokemon %>%
top_n(n = -9, wt = species_id) %>%
select(identifier, type_1, type_2) %>%
kable()
| identifier | type_1 | type_2 |
|---|---|---|
| bulbasaur | grass | poison |
| ivysaur | grass | poison |
| venusaur | grass | poison |
| charmander | fire | NA |
| charmeleon | fire | NA |
| charizard | fire | flying |
| squirtle | water | NA |
| wartortle | water | NA |
| blastoise | water | NA |
Single and dual types
So Pokemon can have either 1 or 2 types. What’s the split between single
type and dual type Pokemon?
pokemon %>%
mutate(dual_type = case_when(is.na(type_2) ~ TRUE,
TRUE ~ FALSE)) %>%
group_by(dual_type) %>%
summarise(count = n()) %>%
kable()
| dual_type | count |
|---|---|
| FALSE | 405 |
| TRUE | 402 |
So, it’s nearly a 50:50 split of Pokemon that are single type to Pokemon
that have 2 types.
How many by type?
But there are also quite a few types of Pokemon. Starting with the
primary type, lets make a quick chart to understand the distribution of
primary types. Using group_by will mean the summarise gets
calculated per group. We can then pipe directly into ggplot for a
col chart with geom_col.
pokemon %>%
group_by(type_1) %>%
summarise(count = n()) %>%
ggplot(aes(x = type_1, y = count)) +
geom_col() +
labs(title = "Pokemon by primary type")

Lots of water type Pokemon, and lots of normal type Pokemon, but very
few flying types. Interesting. How about the secondary types?
pokemon %>%
filter(!is.na(type_2)) %>%
group_by(type_2) %>%
summarise(count = n()) %>%
ggplot(aes(x = type_2, y = count)) +
geom_col() +
labs(title = "Pokemon by secondary type",
caption = "For Pokemon with dual type")
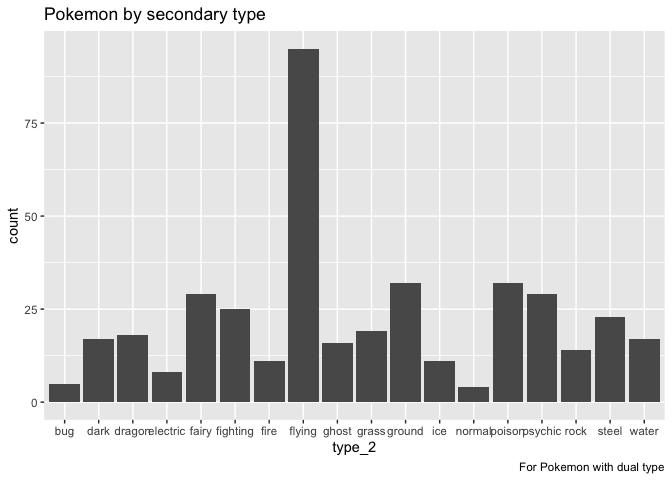
Look at all those ’mons with flying as a secondary type! The thing is
that, game-wise, the order of the typing doesn’t matter. We can easily
count the occurrence of a specific type in either primary or secondary
position with pivot_longer.
pivot_longer is actually a newer tidyverse function. It is
complemented with pivot_wider and this pair are intended to eventually
replace spread and gather. By filtering out the NA I remove any
observations of secondary types for Pokemon that don’t actually have
them.
pokemon %>%
select(identifier, type_1, type_2) %>%
pivot_longer(-identifier, names_to = "slot", values_to = "type") %>%
group_by(type) %>%
summarise(count = n()) %>%
filter(!is.na(type)) %>%
ggplot(aes(x = type, y = count)) +
geom_col() +
labs(title = "Pokemon by either type",
caption = "This will count a dual type Pokemon twice,\nonce for each type")
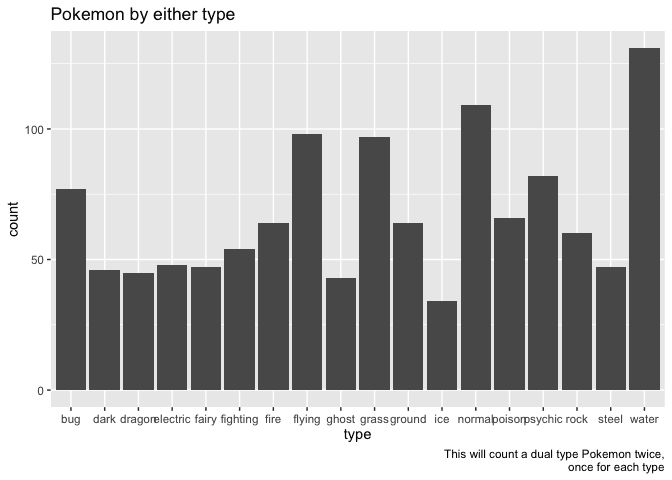
So is there any consistency in order at all?
pokemon %>%
filter((type_1 == "ghost" & type_2 == "fire") |
(type_1 == "fire" & type_2 == "ghost")) %>%
select(identifier, type_1, type_2)
## # A tibble: 4 x 3
## identifier type_1 type_2
## <chr> <chr> <chr>
## 1 litwick ghost fire
## 2 lampent ghost fire
## 3 chandelure ghost fire
## 4 blacephalon fire ghost
It doesn’t look like it. a ghost fire Pokemon and a fire ghost
Pokemon both turn up. I’d like to see what the coincidence rate is of
each type in dual type Pokemon, so I need to get some ordering in. I can
use case_when in mutate to create a two new columns in the data. I
can make 2 in one call because mutate supports multiple expressions,
each of which names a column, and then operates conditionally on the
other 2 type columns. These new columns will:
- always have a value in the column
type_1_ordered - if the Pokemon is dual type, have a value in
type_2_ordered - always have the types alphabetically ordered between the two
columns. i.e. it will always be
fire, ghost, neverghost, fire.
pokemon %>%
mutate(
type_1_ordered = case_when(is.na(type_2) ~ type_1,
type_1 < type_2 ~ type_1,
TRUE ~ type_2),
type_2_ordered = case_when(type_1 > type_2 ~ type_1,
TRUE ~ type_2)
) -> pokemon
What might the distribution be of the flying secondary type, per primary
type?
pokemon %>%
mutate(type_combined = case_when(
!is.na(type_2_ordered) ~ paste(type_1_ordered, type_2_ordered),
is.na(type_2_ordered) ~ type_1_ordered
)) %>%
group_by(type_combined) %>%
summarise(count = n()) %>%
arrange(desc(count)) %>%
mutate(type_combined = as_factor(type_combined)) %>%
ggplot(aes(x = type_combined, y = count)) +
geom_col() +
labs(title = "Count of Pokemon by dual type",
caption = "Ordered by count") +
theme(axis.text.x = element_text(angle = 90))
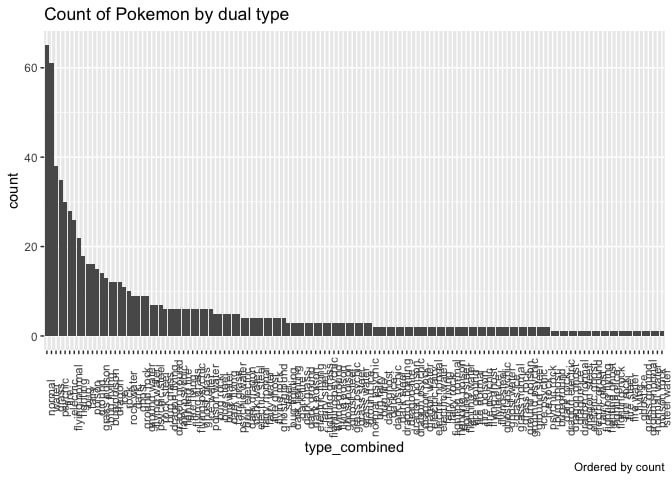
So the most often occurring dual type is flying normal. That explains
the first 2 charts. It’s a bit tricky to see the rest though. Lets make
a more useful plot.
pokemon %>%
group_by(type_1_ordered, type_2_ordered) %>%
filter(!is.na(type_2_ordered)) %>%
summarise(count = n()) %>%
ggplot(aes(x = type_1_ordered, y = type_2_ordered, size = count)) +
geom_point() +
labs(title = "Coincidence of a particular dual type")
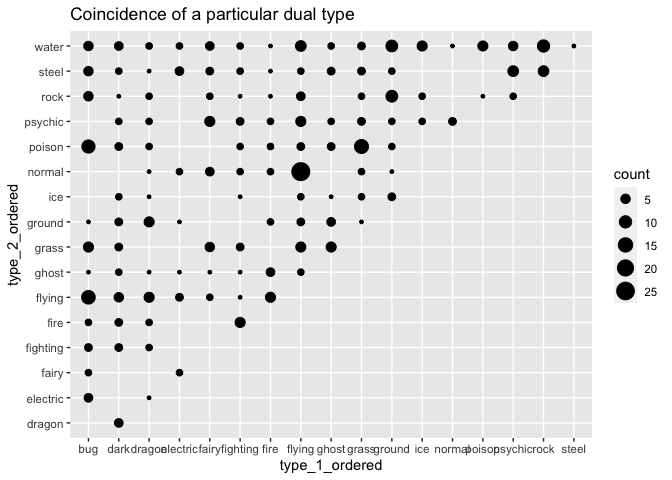
So flying normal has the biggest count, with there being quite a few
bug flying. That makes sense, as so many bug Pokemon have wings!
There are also lot’s of bug poison and grass poison. That makes
sense too, as so many bugs and plants are poisonous! How many Pokemon
have unique types though?
pokemon %>%
group_by(type_1_ordered, type_2_ordered) %>%
filter(!is.na(type_2_ordered)) %>%
summarise(count = n()) %>%
filter(count == 1) %>%
ungroup() %>%
summarise(count = n()) %>%
kable()
| count |
|---|
| 24 |
24 Pokemon have unique dual types. Out of 807 that isn’t very many!
Maybe these Pokemon might be particularly useful? I’ll try and work it
out…
Game Over
This post has been a simple example of both the data in the package, but
also the tidyverse methods of doing Exploratory Data Analysis. You can
find out more about tidyverse here
I got the raw data from this repo by
veekun. My package is available
here, and the particular version
I used for this post is
here.
Though it’s in a pretty raw state, I hope to improve over time.
I made this package to have a bigish, diverse set of data to play with,
that lots of people recognise, and that has some inherent real world
application. Pokemon is a huge franchise with multiple instalments. Lots
of people have played it, and even if you haven’t you probably have an
intuition about what a Pokemon is, and what data about a Pokemon might
make sense, and mean in context with other Pokemon. Feel free to fork
and mess around with as you like. I hope its fun, and maybe even
useful!

Top comments (0)