
Welcome to the third part of this blog series in which we build our own Twitter Analytics service, including followers and unfollowers data.
In case you are just jumping in, here is what happened so far:
- In the first part we created a Twitter Developer Account and used the API to download statistical data of our tweets as well as follower data.
- In the second part we used Azure Functions to run these downloads periodically and store them in the Azure Cloud
Today, we will use Azure Functions with a Blob Trigger to analyze our downloaded data.
In case you haven't already, please make sure, that the __init__.py file of your time triggered Azure Function from part two also downloads the tweet statistics. This is handled by the code below the # Upload tweet stats to Azure Storage line here:
import datetime
import logging
import os
import json
import gzip
from twitterstats import Fetcher
from azure.storage.blob import BlobServiceClient
import azure.functions as func
def main(mytimer: func.TimerRequest) -> None:
utc_timestamp = datetime.datetime.utcnow().replace(
tzinfo=datetime.timezone.utc).isoformat()
# Getting follower data
fetcher = Fetcher()
followers = fetcher.get_followers()
# Connecting to Azure Storage
AZURE_CONNECTION_STRING = os.getenv('AzureWebJobsStorage')
container_name = str("output")
blob_name = f"FOLLOWERS_{utc_timestamp}.json.gz"
blob_service_client = BlobServiceClient.from_connection_string(AZURE_CONNECTION_STRING)
blob_client = blob_service_client.get_blob_client(container=container_name, blob=blob_name)
# Upload compressed data to Azure Storage
json_data = json.dumps(followers)
encoded = json_data.encode('utf-8')
compressed = gzip.compress(encoded)
blob_client.upload_blob(compressed)
# Upload tweet stats to Azure Storage
promoted_tweets = fetcher.get_tweets(promoted=True)
unpromoted_tweets = fetcher.get_tweets(promoted=False)
blob_name = f"TWEETS_{utc_timestamp}.json.gz"
blob_client = blob_service_client.get_blob_client(container=container_name, blob=blob_name)
json_data = json.dumps(dict(promoted=promoted_tweets, unpromoted=unpromoted_tweets))
encoded = json_data.encode('utf-8')
compressed = gzip.compress(encoded)
blob_client.upload_blob(compressed)
Preliminary Thoughts
Just as a recap: We now have several files in our bucket. For every full hour, we have one file prefixed with FOLLOWERS_, one prefixed with TWEETS_.
All of these files are in gzip compressed JSON format, so that we start with writing a function to get them from our storage and parse them with Python's json module.
def get_data_from_azure(blob_service_client, blob_name, container_name="output", default=None):
try:
blob_client = blob_service_client.get_blob_client(container=container_name, blob=blob_name)
data = blob_client.download_blob().readall()
uncompressed = gzip.decompress(data)
return json.loads(uncompressed)
except:
return default
Since we need to store the results of our analysis back to Azure, we need a function that writes a Python dict to Azure in the same way:
def write_to_azure(blob_service_client, blob_name, data, container_name="output"):
blob_client = blob_service_client.get_blob_client(container=container_name, blob=blob_name)
json_data = json.dumps(data)
encoded = json_data.encode('utf-8')
compressed = gzip.compress(encoded)
blob_client.upload_blob(compressed, overwrite=True)
Now that we have prepared that, we can start analyzing our followers.
Creating a New Azure Function
What we need is a function, which is triggered right after we got the results from Twitter's API. This function should take the current snapshot of Twitter's API results and compare that snapshot to the snapshot of the previous run. This comparison includes checking which new users appear in the followers list and which users are now missing (unfollowers).
Since we store each of these snapshots in the Azure Blob Storage, we can use what is called a "Blob Trigger" in Azure. This trigger will run our function, whenever a new Blob ("file") is stored in our container.
So, we start by adding a new function in VSCode:
Again, click on "Create Function…" in the Azure Tab of VSCode (look in the last article in case you missed it)
This time, select "Azure Blob Storage trigger"

Give your function a name

Make sure you select the AzureWebJobsStorage environment variable
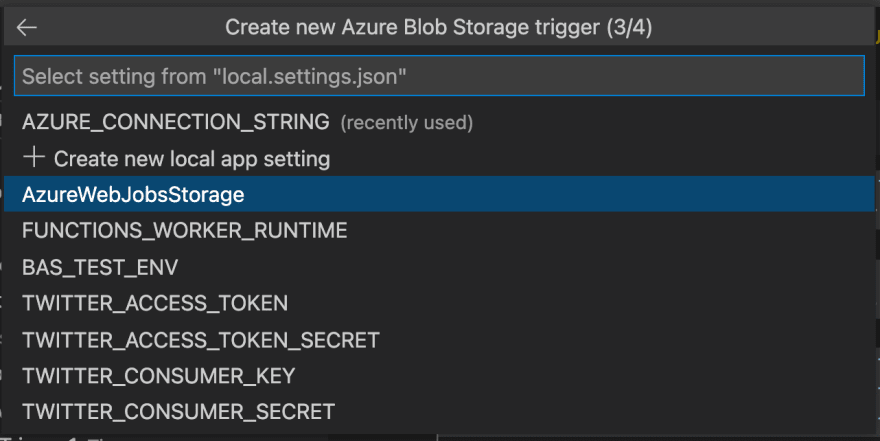
In the last step, choose output/{name} as the path to be monitored. If you changed the container name from output to something else, make sure, this setting reflects your change.

Finding Followers, Unfollowers and Analyse Tweet Logs
CONTAINER_NAME = str("output")
def main(myblob: func.InputStream):
AZURE_CONNECTION_STRING = os.getenv('AzureWebJobsStorage')
blob_service_client = BlobServiceClient.from_connection_string(AZURE_CONNECTION_STRING)
container_client = blob_service_client.get_container_client(CONTAINER_NAME)
if myblob.name.startswith(f"{CONTAINER_NAME}/FOLLOWERS_"):
timestamps = sorted([blob.name.split("_")[1].replace(".json.gz", "") for blob in container_client.list_blobs() if blob.name.startswith("FOLLOWERS")])
try:
current_time_stamp = myblob.name.split("_")[1].replace(".json.gz", "")
idx = timestamps.index(current_time_stamp)
except:
current_time_stamp = None
idx = 0
this_filename = f"FOLLOWERS_{current_time_stamp}.json.gz"
this_followers = get_data_from_azure(blob_service_client, this_filename, default=[])
if idx > 0:
prev_ts = timestamps[idx-1]
prev_filename = f"FOLLOWERS_{prev_ts}.json.gz"
prev_followers = get_data_from_azure(blob_service_client, prev_filename, default=[])
else:
prev_followers = []
USER_INFO = get_data_from_azure(blob_service_client, "USER_INFO.json.gz", default={})
NEW_FOLLOWERS = get_data_from_azure(blob_service_client, "NEW_FOLLOWERS.json.gz", default={})
LOST_FOLLOWERS = get_data_from_azure(blob_service_client, "LOST_FOLLOWERS.json.gz", default={})
for twitter_user in this_followers:
USER_INFO[twitter_user['id']] = twitter_user
this_follower_ids = [f['id'] for f in this_followers]
prev_follower_ids = [f['id'] for f in prev_followers]
new_followers = [follower_id for follower_id in this_follower_ids if follower_id not in prev_follower_ids]
lost_followers = [follower_id for follower_id in prev_follower_ids if follower_id not in this_follower_ids]
NEW_FOLLOWERS[current_time_stamp] = new_followers
LOST_FOLLOWERS[current_time_stamp] = lost_followers
write_to_azure(blob_service_client, "USER_INFO.json.gz", USER_INFO)
write_to_azure(blob_service_client, "NEW_FOLLOWERS.json.gz", NEW_FOLLOWERS)
write_to_azure(blob_service_client, "LOST_FOLLOWERS.json.gz", LOST_FOLLOWERS)
elif myblob.name.startswith(f"{CONTAINER_NAME}/TWEETS_"):
STATS_TWEETS = get_data_from_azure(blob_service_client, "STATS_TWEETS.json.gz", default={})
promoted = this_stats['promoted']
unpromoted = this_stats['unpromoted']
all_tweets = promoted + unpromoted
for tweet in all_tweets:
tweet_id = tweet["id"]
created_at = tweet["created_at"]
text = tweet["text"]
if tweet_id not in STATS_TWEETS.keys():
STATS_TWEETS[tweet_id] = {}
STATS_TWEETS[tweet_id]["text"] = text
STATS_TWEETS[tweet_id]["created_at"] = created_at
if "stats" not in STATS_TWEETS[tweet_id].keys():
STATS_TWEETS[tweet_id]["stats"] = {}
STATS_TWEETS[tweet_id]["stats"][current_time_stamp] = dict(
promoted_metrics = tweet.get("promoted_metrics"),
public_metrics = tweet.get("public_metrics"),
non_public_metrics = tweet.get("non_public_metrics"),
organic_metrics = tweet.get("organic_metrics")
)
write_to_azure(blob_service_client, "STATS_TWEETS.json.gz", STATS_TWEETS)
Re-triggering the function
As soon as this function terminates for a particular blob in your container, this blob is marked as processed, so that the function will only be triggered once per blob. The only exception for this rule is when the blob has changed. But since we're continiously adding blobs instead of overwriting them, this does not count here.
If you, for whatever reason, want to retrigger the whole cascade of function calls, you need to update (or delete) a file called scanInfo. You can find this file in a container named azure-webjobs-hosts inside the storage account linked to your Azure Function App. Navigate to teh scanInfo file via these prefixes:
blobscaninfo/<Your Function Name>/storageAccount/storageContainer
You can delete that file. If you do, your Blob Trigger Function will be executed again and again for each file inside your output container.
Looking at the files
This function will create four new files for us:
-
USER_INFO.json.gz– Containing consolidated info about users. -
NEW_FOLLOWERS.json.gz– Containing time stamped lists of user ids of new followers. -
LOST_FOLLOWERS.json.gz– Containing time stamped lists of user ids of lost followers. -
STATS_TWEETS.json.gz– Containing consolidated and time stamped statistics about each tweet.
What we have now
Here is a recap of what we achieved in today's tutorial:
- We created an Azure Function triggered by a Blob Trigger
- We compared snapshots of our followers to the respective previous snapshot
- From this comparison we compiled a list of new and lost followers
- We extended a timestamp indexed JSON dict and uploaded this to Azure
In the next series, we will build a frontend for the data we created today. I am particularly looking forward to this one as we will use Python only but our Dashboard will still run in the browser! So stay tuned!
If you like stuff like this, make sure you follow me on Twitter where I constantly post interesting Python, SQL and CloudComputing stuff!

Top comments (0)