![Cover image for Web Scraping with NodeJS: a comprehensive guide [part-3]](https://media2.dev.to/dynamic/image/width=1000,height=420,fit=cover,gravity=auto,format=auto/https%3A%2F%2Fdev-to-uploads.s3.amazonaws.com%2Fuploads%2Farticles%2Fb692as1wbxtl3hwsxjyg.png)
Shorthand technique to extract the selectors.
Let's look at a simpler and faster way to gather selectors to scrape data from a website. This method is useful when you need to get something done quickly without having to worry too much about it. The only disadvantage is that it can be more vulnerable to errors. So, let's get this party started. Previously, when we wanted to scrape something from the IMDB scraper, we went to the website, used the inspector to look at the HTML structure, and then built a specific selector for that type of data. Let's look at an example. If we wanted to extract the title, we used a section with a class of ipc-page-section and then div with a class of TitleBlock, followed by other tags/elements, and then we needed to get the text, but this is a very long method.
section.ipc-page-section > div > div > h1
So, let's see what we can scrape for this example, let's say we wanted to get the movie plot, so what we can do is right-click inspect as we did previously, and what we can see right here is that the element that we want to scrape is a span containing some text.
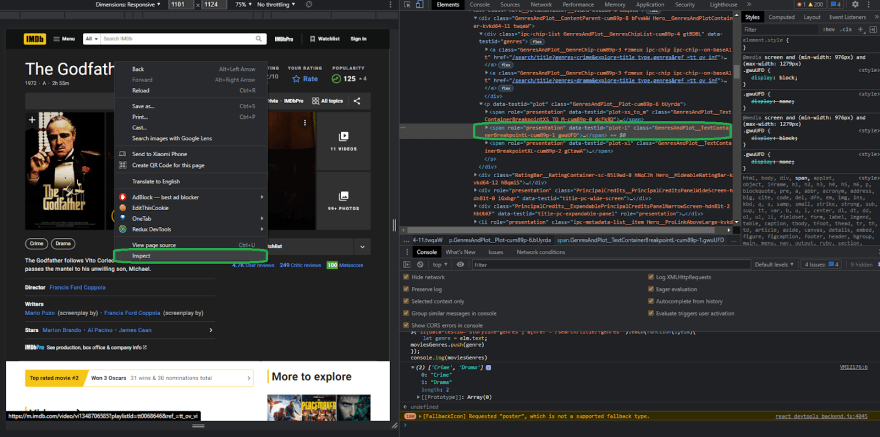
After that, what we want to do is scrape everything, and this is the simplest way to do it without overcomplicating things, so right-click on the element that we want to scrape, click on copy, and then copy selector by right-clicking on the selector and copying it. This implies that the browser will construct the selector for you and will apply its best reasoning to provide you with the results you desire.
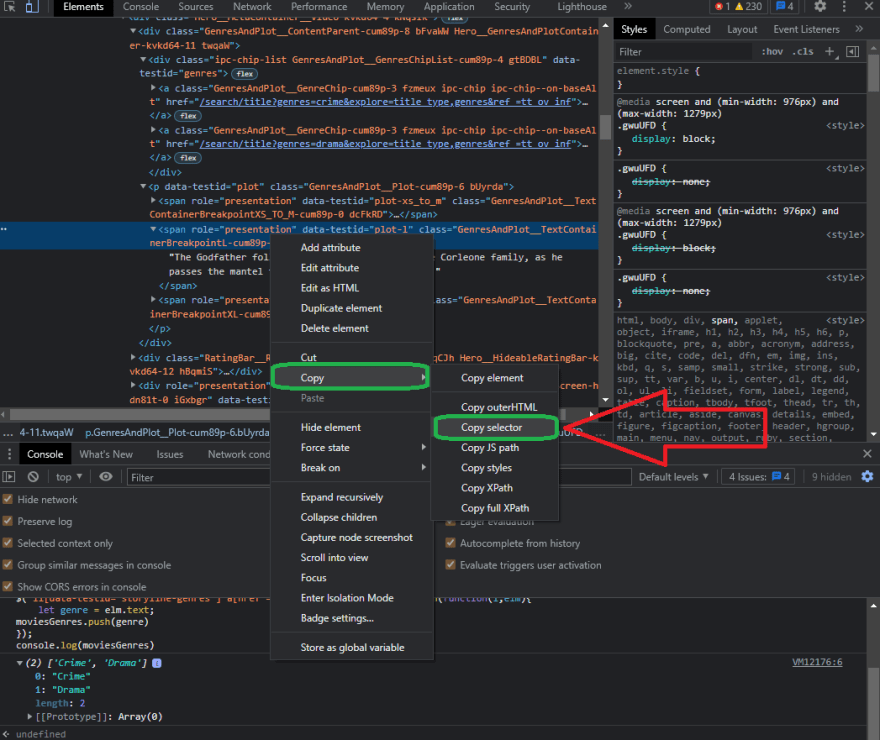
Let's try it out in our code editor as well, so go to the code and create a new variable called moviePlot, and then do it the same way we did before, copying everything and pasting it right here. We want to get the text and also trim it, so now that we have the variable, let's set a breakpoint right at it or simply console log it to see what the moviePlot variable is spitting out.
let moviePlot = $("#__next > main > div.ipc-page-content-container.ipc-page-content-container--full.BaseLayout__NextPageContentContainer-sc-180q5jf-0.fWxmdE > section.ipc-page-background.ipc-page-background--base.TitlePage__StyledPageBackground-wzlr49-0.dDUGgO > section > div:nth-child(4) > section > section > div.Hero__MediaContentContainer__Video-kvkd64-2.kmTkgc > div.Hero__ContentContainer-kvkd64-10.eaUohq > div.Hero__MetaContainer__Video-kvkd64-4.kNqsIK > div.GenresAndPlot__ContentParent-cum89p-8.bFvaWW.Hero__GenresAndPlotContainer-kvkd64-11.twqaW > p > span.GenresAndPlot__TextContainerBreakpointL-cum89p-1.gwuUFD").text().trim()
console.log(moviePlot);
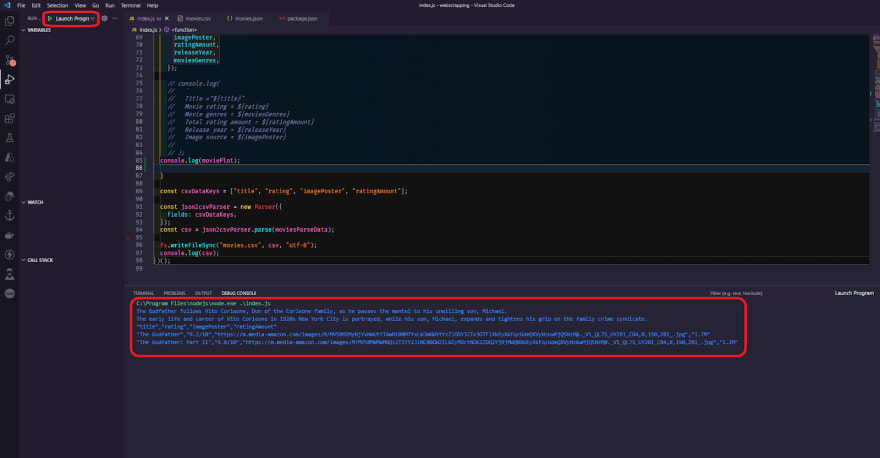
So, as you can see, all we had to do was copy and paste the selector generated by the Chrome browser. Of course, this is a lot easier than writing the selectors ourselves, and before we go any further, let's talk about the disadvantages of using this method versus the others we've discussed previously. There is no actual problem with using this method; no one is stopping you, but there is one thing to consider. As you can see, this selector is much larger than the others we constructed by hand. This is because the browser works its magic and tries to offer you the selector for the element it feels is the finest. However, there are far more selectors than are required. The disadvantage of having a lot of elements in your query is that the chances of it failing in the future are much higher. As you can see from what we wrote before, we used about one, two, or even three or four elements to scrape something, but in this case, we are using five, six, and seven elements to get that exact text. If one of those elements from the website changes, the query stops working, So, depending on the website and the circumstance, it's preferable to have two or three elements in our query selector than seven or even more. Always remember, the simpler the better. So, here's the question you might want to ask yourself: when would I choose one more than the other?
So, if you need to get something done quickly for any reason, or you know that a particular website doesn't change very often, you may use this copy and paste selection method. The beautiful thing about this method is that you don't even need to know how to write CSS selectors to build a scraper and this method may seem way easier and faster.
Scraping and extracting the images locally
In this segment, we'll learn how to more precisely download anything from a website and save it as a file. We'll go over how to get the image posters for all the movies that you wish to scrape.
First, a brief reminder that we'll be using the request library rather than the request-promise library we've been using up to this point. So, before we go any further, let's implement it right at the top, in the import area of the code, and just import the library.
// index.js
const requestPromise = require("request-promise");
const cheerio = require("cheerio");
const fs = require("fs");
const { Parser } = require("json2csv");
const request = require("request");
Also, don't forget to update the variable name from "request" to "requestPromise.". The reason we're using the request library rather than the request-promise library is that the request library is the original library dedicated to straightforward processing of the types of requests we make in Node. The request-promise library that we previously used is just a wrapper around the original request library, and it allows you to use the ES 2015 syntax with async-await instead of going into callback hell with the original library. This is the main reason we used request-promise rather than the request library itself for our scraper.
Now, before we get started on actually developing the scrapper for obtaining and storing images/posters, let's perform some fast preparation.
So, instead of an array of just strings, transform it into an array of objects. So, instead of just a URL as a string, make it an object and pass it URL prop and then close it, and then URL prop again for the next one and close it.
const URLS = [
{ url: "https://www.imdb.com/title/tt0068646/?ref_=fn_al_tt_1" },
{ url: "https://m.imdb.com/title/tt0071562/?ref_=tt_sims_tt_t_1" },
];
Okay, to make this work with our current code, we'll simply alter the url because instead of passing in a string, we'll just pass in the object and access the url of this object, which will be the url that we defined.

Also, the last section must be commented out because it is unnecessary and not required as of now.
![]()
Let's start actually writing some code, so let's say you want to download something from a website, say an image, a word document, music, or a pdf, you will basically need to create a file stream within node.js so that it can put data into it and build the actual file, so let's start and create a variable let's say it "imageExtractFile" which equals to file system and attach "createWriteStream" function and we only need to pass in a parameter related to the actual path of the file that we want to create, so keep in mind that we are in a for loop that iterates over each of the URLs that we are using, so we must use a dynamic file name; we can't just use "some_name.jpg" because it will be overwritten in the second call, and we only have one file.
let imageExtractFile = fs.createWriteStream(`some_name.jpg`);
Before we go any further, we need to send in an id or anything for the actual file that we're going to utilize, so let's go to the top and add id, and simply pass in the movie name of this movie or something unique name, like "the godfather" and "the godfather 2".
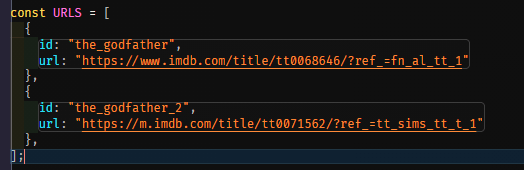
Now we can use these ids to create the actual file with these names, so let's go back and do that right here. We want to create a file with the name of the movie dot id and then we're going to put it as a jpeg. We need to specify it because we don't know what type of file it is when we're actually downloading it, and this will make it easier because we can find out what type of file it is from either the URL or from the request response, but for now, we'll presume it'll be a jpeg because we already know movie posters are jpeg, and we'll just pass in dot jpg. Now that we have this, we can test it out. However, before you do that, your code should look like this.
let imageExtractFile = fs.createWriteStream(`${movieUrl.id}.jpg`);
and we should expect to see two files created on the system with the ids of the “the_godfather.jpg” and “the_godfather_2.jpg”, so let's do this quickly to make sure everything works, and then let's return to the files, where we find "the_godfather.jpg" and "the_godfather_2.jpeg," which is an empty file because we didn't pass any data into it.
Now we need to take care of the request that goes to the server for the actual movie poster and then stream the data into our newly created files, so let's look at a quick example of how to stream data into a file. You need to make the same request as before, pass in the URL, and then use the pipe function to pass in the data to the newly created file that we previously did also with “createWriteStream”.
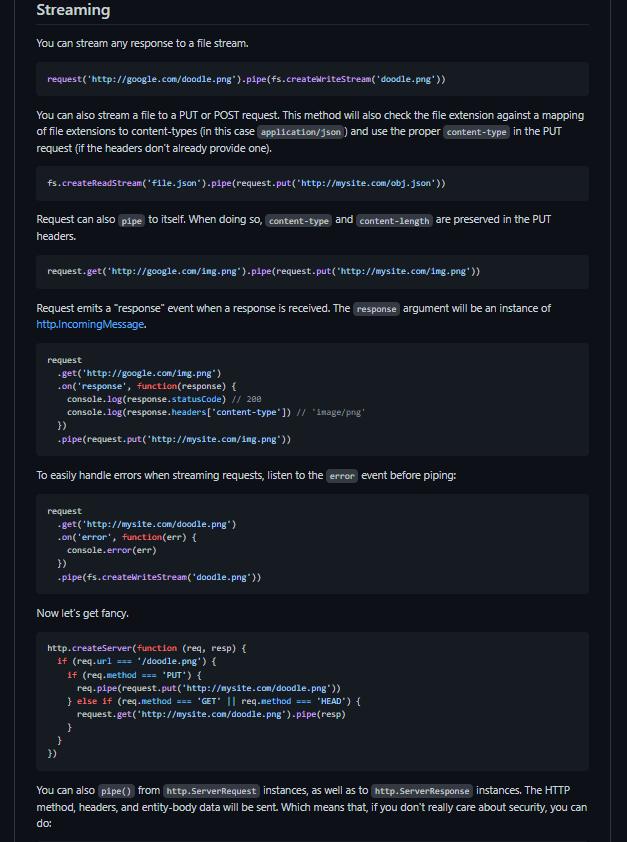
This is very simple, so let's get started. First, let's create a new variable called "streamImage," and then we'll use the request library to do the same thing we did previously in the URI, passing in the "movieUrl.imagePoster" which holds the image's actual link, and then for the headers, just copy-paste what we did above copy all of the. Copy all of the headers and paste them below. We only need to remove the HOST part of the code because the host isn't the IMDB main site URL; instead, the posters are using a S3 bucket from Amazon, which will cause some issues, so we'll just remove it. Also, don't forget to add the gzip. All right, right now we just want to pipe it out, so pipe it and then specify the actual imageExtractFile. Finally, here's what your code should look like now.
// index.js
const requestPromise = require("request-promise");
const cheerio = require("cheerio");
const fs = require("fs");
const { Parser } = require("json2csv");
const request = require("request");
const URLS = [
{
id: "the_godfather",
url: "https://www.imdb.com/title/tt0068646/?ref_=fn_al_tt_1",
}
// {
// id: "the_godfather_2",
// url: "https://m.imdb.com/title/tt0071562/?ref_=tt_sims_tt_t_1",
// },
];
(async () => {
let moviesParseData = [];
for (let movieUrl of URLS) {
const response = await requestPromise({
uri: movieUrl.url,
headers: {
"accept":
"text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"accept-encoding": "gzip, deflate, br",
"accept-language": "en-IN,en-US;q=0.9,en;q=0.8",
"cache-control": "no-cache",
"pragma": "no-cache",
"sec-ch-ua":
'" Not A;Brand";v="99", "Chromium";v="96", "Google Chrome";v="96"',
"sec-ch-ua-mobile": "?1",
"sec-ch-ua-platform": "Android",
"sec-fetch-dest": "document",
"sec-fetch-mode": "navigate",
"sec-fetch-site": "same-origin",
"sec-fetch-user": "?1",
"sec-gpc": "1",
"upgrade-insecure-requests": "1",
"user-agent":
"Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Mobile Safari/537.36",
},
gzip: true,
});
let $ = cheerio.load(response);
// console.log(response);
let title = $("section.ipc-page-section > div > div > h1").text().trim();
let rating = $("div.ipc-button__text > div > div:nth-child(2) > div > span")
.text()
.slice(0, 6);
let imagePoster = $("div.ipc-media > img.ipc-image").attr("src");
let ratingAmount = $(
"div.ipc-button__text > div:last-child > div:last-child > div:last-child"
)
.text()
.slice(0, 4);
let releaseYear = $("li.ipc-inline-list__item > a").text().slice(0, 4);
let moviesGenres = [];
let movieGenresData = $(
'li[data-testid="storyline-genres"] a[href^="/search/title/?genres"]'
);
let moviePlot = $(
"#__next > main > div.ipc-page-content-container.ipc-page-content-container--full.BaseLayout__NextPageContentContainer-sc-180q5jf-0.fWxmdE > section.ipc-page-background.ipc-page-background--base.TitlePage__StyledPageBackground-wzlr49-0.dDUGgO > section > div:nth-child(4) > section > section > div.Hero__MediaContentContainer__Video-kvkd64-2.kmTkgc > div.Hero__ContentContainer-kvkd64-10.eaUohq > div.Hero__MetaContainer__Video-kvkd64-4.kNqsIK > div.GenresAndPlot__ContentParent-cum89p-8.bFvaWW.Hero__GenresAndPlotContainer-kvkd64-11.twqaW > p > span.GenresAndPlot__TextContainerBreakpointL-cum89p-1.gwuUFD"
)
.text()
.trim();
movieGenresData.each((i, elm) => {
let genre = $(elm).text();
moviesGenres.push(genre);
});
moviesParseData.push({
title,
rating,
imagePoster,
ratingAmount,
releaseYear,
moviesGenres,
});
// console.log(
// `
// Title ="${title}"
// Movie rating = ${rating}
// Movie genres = ${moviesGenres}
// Total rating amount = ${ratingAmount}
// Release year = ${releaseYear}
// Image source = ${imagePoster}
// `
// );
// console.log(moviePlot);
let imageExtractFile = fs.createWriteStream(`${movieUrl.id}.jpg`);
let streamImage = request({
url: movieUrl.imagePoster,
headers: {
"accept":
"text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"accept-encoding": "gzip, deflate, br",
"accept-language": "en-IN,en-US;q=0.9,en;q=0.8",
"cache-control": "no-cache",
"pragma": "no-cache",
"sec-ch-ua":
'" Not A;Brand";v="99", "Chromium";v="96", "Google Chrome";v="96"',
"sec-ch-ua-mobile": "?1",
"sec-ch-ua-platform": "Android",
"sec-fetch-dest": "document",
"sec-fetch-mode": "navigate",
"sec-fetch-site": "same-origin",
"sec-fetch-user": "?1",
"sec-gpc": "1",
"upgrade-insecure-requests": "1",
"user-agent":
"Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Mobile Safari/537.36",
},
gzip: true,
}).pipe(imageExtractFile);
}
// const csvDataKeys = ["title", "rating", "imagePoster", "ratingAmount"];
// const json2csvParser = new Parser({
// fields: csvDataKeys,
// });
// const csv = json2csvParser.parse(moviesParseData);
// fs.writeFileSync("movies.csv", csv, "utf-8");
// console.log(csv);
})();
We actually have the code written and ready to go, but first, comment out the second movie because we only want to run it for the first movie. The reason for this is because we're in a for loop, and what's happening is that it's making the first request for the first movie, waiting for it to finish because we use the await syntax, and then it's going to make a request for the imagePoster is going to get saved to the file, but it will not wait for the entire process to complete before continuing; instead, it will immediately return to the top and make the second request, after which it will return to the bottom and which will collide. Hence, run it for a single movie and then deal with the issue later. Let's put it to the test and see how it goes, so fire up the debugger.

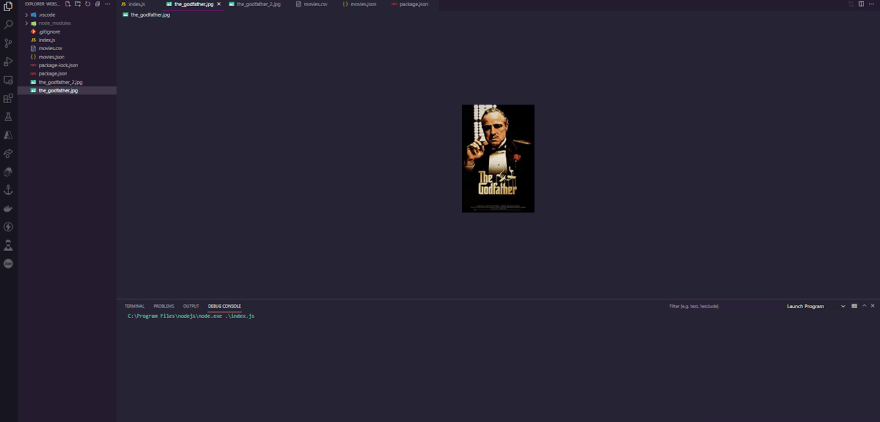
Now that we have the actual image downloaded, it appears that the_godfather.jpg is the actual image poster that we intended to extract. It completes the task as planned.
Promisify callback functions.
Let's keep going with the image downloading part that we left off and see if we can address the problem we're having, so the main problem was that the downloading process starts, but it doesn't wait for it to finish before continuing. So, before we go any further, let's deep dive into “what is promisifying?”, so promisifying is the process of converting a non-promise function based on callbacks into a promise-returning function.
So let’s start fixing this issue, by default in node.js you can create your promise here is a quick example.
let promisifyStuff = await new Promise((resolve,reject) => {
let alien = true;
if(alien){
resolve(true)
} else {
reject(false)
}
});
Let's imagine we're waiting for a new promise, and this function only has two parameters: resolve and reject. Let's say we have a variable called alien, and we're going to build a quick if statement that says if an alien is true, resolve with true and if not, reject with false.
Let's put everything into a variable and place a breakpoint at the end so we can observe what value that variable is spitting out. Let's run it quickly and test the value.

We have true since we checked to see if the alien is true and if it is, we resolve the promise using the function true, passing a string inside resolve, and then running it again, this "promisifyStuff" variable will be the exact string.
Let's see if we can quickly test it for the false as well, and see what we get when it rejects. Let's add a random string message in there and run it again, and we now receive an unhandled promise rejection error.
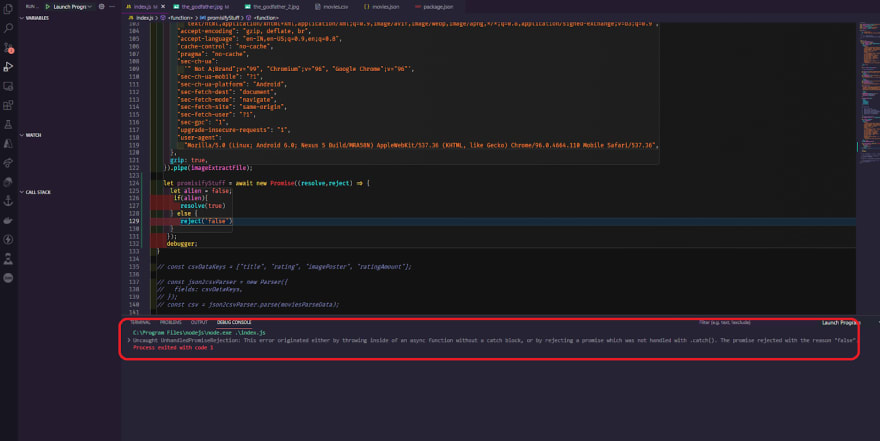
That's because we didn't catch the actual error. The reject throws an error, which we need to capture by wrapping it in a try-catch, then catching the error and console. log the error, and if we test again, the false message should be console logged.
try {
let promisifyStuff = await new Promise((resolve, reject) => {
let alien = false;
if (alien) {
resolve(true);
} else {
reject("false");
}
});
} catch (error) {
console.log(error);
}
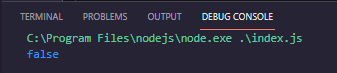
This was only a quick introduction to javascript promises, and it is highly advised that you investigate them further.
Let's return to our objective and start implementing this into what we need to accomplish. Basically, we need to wrap around this new promise thing into our stream request and let's get started right away. We'll just await a new Promise with resolve reject param and put it at the top of the streamImage, and then we'll end/wrap the promise. Now we need to figure out when the actual stream is completed. We can figure this out by adding an on() listener to an event. The event that we need to listen to is "finish," since after the request library is finished with the actual request, it will throw a finished event, which we need to grab onto. Now we'll just open up a function and declare a console. We'll log "some message or whatever custom message you want," and then we'll specify the resolve, which we'll say is true or you can leave them empty because we don't have to catch the message and we don't have to utilize it, so leaving it empty is fine. This is what your code should look like.
// index.js
const requestPromise = require("request-promise");
const cheerio = require("cheerio");
const fs = require("fs");
const { Parser } = require("json2csv");
const request = require("request");
const URLS = [
{
id: "the_godfather",
url: "https://www.imdb.com/title/tt0068646/?ref_=fn_al_tt_1",
},
{
id: "the_godfather_2",
url: "https://m.imdb.com/title/tt0071562/?ref_=tt_sims_tt_t_1",
},
];
(async () => {
let moviesParseData = [];
for (let movieUrl of URLS) {
const response = await requestPromise({
uri: movieUrl.url,
headers: {
"accept":
"text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"accept-encoding": "gzip, deflate, br",
"accept-language": "en-IN,en-US;q=0.9,en;q=0.8",
"cache-control": "no-cache",
"pragma": "no-cache",
"sec-ch-ua":
'" Not A;Brand";v="99", "Chromium";v="96", "Google Chrome";v="96"',
"sec-ch-ua-mobile": "?1",
"sec-ch-ua-platform": "Android",
"sec-fetch-dest": "document",
"sec-fetch-mode": "navigate",
"sec-fetch-site": "same-origin",
"sec-fetch-user": "?1",
"sec-gpc": "1",
"upgrade-insecure-requests": "1",
"user-agent":
"Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Mobile Safari/537.36",
},
gzip: true,
});
let $ = cheerio.load(response);
// console.log(response);
let title = $("section.ipc-page-section > div > div > h1").text().trim();
let rating = $("div.ipc-button__text > div > div:nth-child(2) > div > span")
.text()
.slice(0, 6);
let imagePoster = $("div.ipc-media > img.ipc-image").attr("src");
let ratingAmount = $(
"div.ipc-button__text > div:last-child > div:last-child > div:last-child"
)
.text()
.slice(0, 4);
let releaseYear = $("li.ipc-inline-list__item > a").text().slice(0, 4);
let moviesGenres = [];
let movieGenresData = $(
'li[data-testid="storyline-genres"] a[href^="/search/title/?genres"]'
);
let moviePlot = $(
"#__next > main > div.ipc-page-content-container.ipc-page-content-container--full.BaseLayout__NextPageContentContainer-sc-180q5jf-0.fWxmdE > section.ipc-page-background.ipc-page-background--base.TitlePage__StyledPageBackground-wzlr49-0.dDUGgO > section > div:nth-child(4) > section > section > div.Hero__MediaContentContainer__Video-kvkd64-2.kmTkgc > div.Hero__ContentContainer-kvkd64-10.eaUohq > div.Hero__MetaContainer__Video-kvkd64-4.kNqsIK > div.GenresAndPlot__ContentParent-cum89p-8.bFvaWW.Hero__GenresAndPlotContainer-kvkd64-11.twqaW > p > span.GenresAndPlot__TextContainerBreakpointL-cum89p-1.gwuUFD"
)
.text()
.trim();
movieGenresData.each((i, elm) => {
let genre = $(elm).text();
moviesGenres.push(genre);
});
moviesParseData.push({
title,
rating,
imagePoster,
ratingAmount,
releaseYear,
moviesGenres,
});
console.log(
`
Title ="${title}"
Movie rating = ${rating}
Movie genres = ${moviesGenres}
Total rating amount = ${ratingAmount}
Release year = ${releaseYear}
Image source = ${imagePoster}
`
);
console.log(moviePlot);
let imageExtractFile = fs.createWriteStream(`${movieUrl.id}.jpg`);
await new Promise((resolve, reject) => {
let streamImage = request({
url: imagePoster,
headers: {
"accept":
"text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"accept-encoding": "gzip, deflate, br",
"accept-language": "en-IN,en-US;q=0.9,en;q=0.8",
"cache-control": "no-cache",
"pragma": "no-cache",
"sec-ch-ua":
'" Not A;Brand";v="99", "Chromium";v="96", "Google Chrome";v="96"',
"sec-ch-ua-mobile": "?1",
"sec-ch-ua-platform": "Android",
"sec-fetch-dest": "document",
"sec-fetch-mode": "navigate",
"sec-fetch-site": "same-origin",
"sec-fetch-user": "?1",
"sec-gpc": "1",
"upgrade-insecure-requests": "1",
"user-agent":
"Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Mobile Safari/537.36",
},
gzip: true,
})
.pipe(imageExtractFile)
.on("finish", () => {
console.log("Movie Poster Image downloaded");
resolve();
});
});
}
const csvDataKeys = ["title", "rating", "imagePoster", "ratingAmount"];
const json2csvParser = new Parser({
fields: csvDataKeys,
});
const csv = json2csvParser.parse(moviesParseData);
fs.writeFileSync("movies.csv", csv, "utf-8");
console.log(csv);
})();
If we execute this, the scraper will go to the first movie and ask for the details, parse them, and then go to the "streamImage" and start downloading and waiting for it to finish, before repeating the process for the second movie. Let's run through the procedure quickly and see what happens. We should see a message that says "Movie Poster Image downloaded" and then another message that says the same thing.


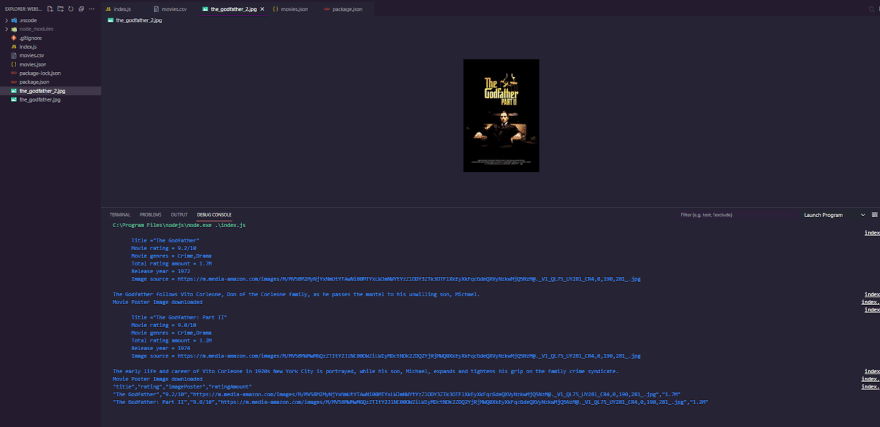
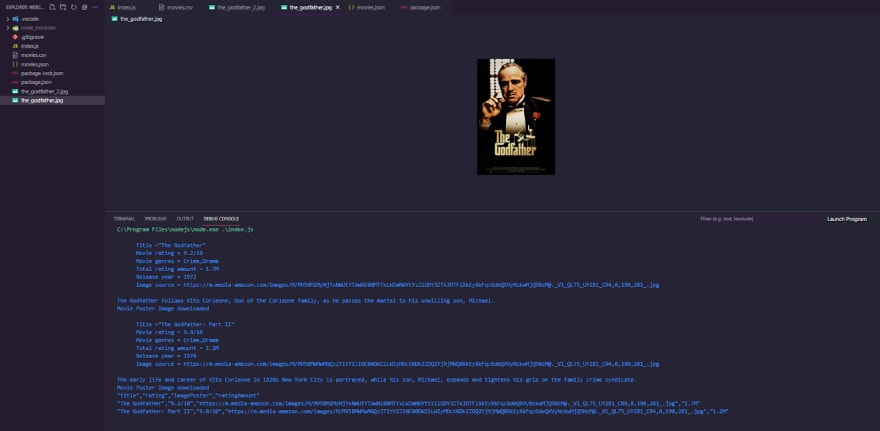
Finally, we're almost done, but we need to handle the fact that it can fail and throw an error, so let's create another on listener and just listen for an error, and then we'll have a function that takes an error parameter and then we'll reject the promise with the actual error that we get, and now that we've rejected the promise with the actual error that we get, we just need to catch it, so simply specify the catch method, then we'll receive the error, and then we'll console.log the error to record and display the error message itself.
await new Promise((resolve, reject) => {
let streamImage = request({
url: imagePoster,
headers: {
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"accept-encoding": "gzip, deflate, br",
"accept-language": "en-IN,en-US;q=0.9,en;q=0.8",
"cache-control": "no-cache",
"pragma": "no-cache",
"sec-ch-ua":
'" Not A;Brand";v="99", "Chromium";v="96", "Google Chrome";v="96"',
"sec-ch-ua-mobile": "?1",
"sec-ch-ua-platform": "Android",
"sec-fetch-dest": "document",
"sec-fetch-mode": "navigate",
"sec-fetch-site": "same-origin",
"sec-fetch-user": "?1",
"sec-gpc": "1",
"upgrade-insecure-requests": "1",
"user-agent":
"Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Mobile Safari/537.36", },
gzip: true,
})
.pipe(imageExtractFile)
.on("finish", () => {
console.log("Movie Poster Image downloaded");
resolve();
})
.on("error", (err) => {
console.log(err);
reject(error);
})
}).catch((err) => {
console.log(err);
});
Finally, we can identify which specific movie an error occurred in by simply replacing the single quotes with backticks, allowing us to use the javascript syntax inside it to designate the individual “movie.id” of the error so that future debugging becomes really very simple. So this is how the final code should look like.
// index.js
const requestPromise = require("request-promise");
const cheerio = require("cheerio");
const fs = require("fs");
const { Parser } = require("json2csv");
const request = require("request");
const URLS = [
{
id: "the_godfather",
url: "https://www.imdb.com/title/tt0068646/?ref_=fn_al_tt_1",
},
{
id: "the_godfather_2",
url: "https://m.imdb.com/title/tt0071562/?ref_=tt_sims_tt_t_1",
},
];
(async () => {
let moviesParseData = [];
for (let movieUrl of URLS) {
const response = await requestPromise({
uri: movieUrl.url,
headers: {
"accept":
"text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"accept-encoding": "gzip, deflate, br",
"accept-language": "en-IN,en-US;q=0.9,en;q=0.8",
"cache-control": "no-cache",
"pragma": "no-cache",
"sec-ch-ua":
'" Not A;Brand";v="99", "Chromium";v="96", "Google Chrome";v="96"',
"sec-ch-ua-mobile": "?1",
"sec-ch-ua-platform": "Android",
"sec-fetch-dest": "document",
"sec-fetch-mode": "navigate",
"sec-fetch-site": "same-origin",
"sec-fetch-user": "?1",
"sec-gpc": "1",
"upgrade-insecure-requests": "1",
"user-agent":
"Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Mobile Safari/537.36",
},
gzip: true,
});
let $ = cheerio.load(response);
// console.log(response);
let title = $("section.ipc-page-section > div > div > h1").text().trim();
let rating = $("div.ipc-button__text > div > div:nth-child(2) > div > span")
.text()
.slice(0, 6);
let imagePoster = $("div.ipc-media > img.ipc-image").attr("src");
let ratingAmount = $(
"div.ipc-button__text > div:last-child > div:last-child > div:last-child"
)
.text()
.slice(0, 4);
let releaseYear = $("li.ipc-inline-list__item > a").text().slice(0, 4);
let moviesGenres = [];
let movieGenresData = $(
'li[data-testid="storyline-genres"] a[href^="/search/title/?genres"]'
);
let moviePlot = $(
"#__next > main > div.ipc-page-content-container.ipc-page-content-container--full.BaseLayout__NextPageContentContainer-sc-180q5jf-0.fWxmdE > section.ipc-page-background.ipc-page-background--base.TitlePage__StyledPageBackground-wzlr49-0.dDUGgO > section > div:nth-child(4) > section > section > div.Hero__MediaContentContainer__Video-kvkd64-2.kmTkgc > div.Hero__ContentContainer-kvkd64-10.eaUohq > div.Hero__MetaContainer__Video-kvkd64-4.kNqsIK > div.GenresAndPlot__ContentParent-cum89p-8.bFvaWW.Hero__GenresAndPlotContainer-kvkd64-11.twqaW > p > span.GenresAndPlot__TextContainerBreakpointL-cum89p-1.gwuUFD"
)
.text()
.trim();
movieGenresData.each((i, elm) => {
let genre = $(elm).text();
moviesGenres.push(genre);
});
moviesParseData.push({
title,
rating,
imagePoster,
ratingAmount,
releaseYear,
moviesGenres,
});
console.log(
`
Title ="${title}"
Movie rating = ${rating}
Movie genres = ${moviesGenres}
Total rating amount = ${ratingAmount}
Release year = ${releaseYear}
Image source = ${imagePoster}
`
);
console.log(moviePlot);
let imageExtractFile = fs.createWriteStream(`${movieUrl.id}.jpg`);
await new Promise((resolve, reject) => {
let streamImage = request({
url: imagePoster,
headers: {
"accept":
"text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"accept-encoding": "gzip, deflate, br",
"accept-language": "en-IN,en-US;q=0.9,en;q=0.8",
"cache-control": "no-cache",
"pragma": "no-cache",
"sec-ch-ua":
'" Not A;Brand";v="99", "Chromium";v="96", "Google Chrome";v="96"',
"sec-ch-ua-mobile": "?1",
"sec-ch-ua-platform": "Android",
"sec-fetch-dest": "document",
"sec-fetch-mode": "navigate",
"sec-fetch-site": "same-origin",
"sec-fetch-user": "?1",
"sec-gpc": "1",
"upgrade-insecure-requests": "1",
"user-agent":
"Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Mobile Safari/537.36",
},
gzip: true,
})
.pipe(imageExtractFile)
.on("finish", () => {
console.log(`Movie Poster Image of ${movieUrl.id} is downloaded`);
resolve();
})
.on("error", (err) => {
console.log(err);
reject(error);
})
}).catch((err) => {
console.log(`${movieUrl.id} image download error ${err}`);
});
}
const csvDataKeys = ["title", "rating", "imagePoster", "ratingAmount"];
const json2csvParser = new Parser({
fields: csvDataKeys,
});
const csv = json2csvParser.parse(moviesParseData);
fs.writeFileSync("movies.csv", csv, "utf-8");
console.log(csv);
})();
Let's do a final check to see if we have a great and curated console error message. So far, everything is working fine, and we've learnt a lot and gone to the depths of scraping from the ground up.

The complete source code is available here:
https://github.com/aviyeldevrel/devrel-tutorial-projects/tree/main/web-scraping-with-nodejs
Conclusion:
In this article, we learned about scraping from the ground up, including Nodejs and the fundamentals of javascript, why and when to scrape a website, the most common problems with scraping, different scraping methods such as to request method and browser automation method, and finally how to scrape the data from the IMDB website in extensive detail, as well as how to export scraped data into CSV and JSON files. If you wish to pursue a career in web scraping, this article may be very useful.
Follow @aviyelHQ or sign-up on Aviyel for early access if you are a project maintainer, contributor, or just an Open Source enthusiast.
Join Aviyel's Discord => Aviyel's world
Twitter =>https://twitter.com/AviyelHq

Top comments (1)
Trust me! It was much needed, thanks