
by author Federico Kereki
Hi! Welcome to this "Forever Functional" series of articles, in which we'll be looking at how to using several Functional Programming patterns and solutions to simplify your JavaScript programming or, as in this particular case, enhance the performance of your code.
In this first article in the series, we'll consider a performance problem: dealing with slow, long-running functions, and improving them by using memoization, an interesting technique to avoid unnecessary work. We'll first see a simple example with slowness problems, then solve it by hand in a particular way, move on to apply a generic solution, and finish by seeing how some current frameworks also provide memoization to get faster-reacting web pages.
Slowness: an example
Let me show you an easy well-known example of a function with severe performance problems. In agile methodologies, the Fibonacci numbers (0, 1, 1, 2, 3, 5, 8, 13...) are often used, albeit with minor changes, for estimating complexity. This series starts with 0 and 1, and after those two first values, the next are calculated as the sum of the two previous values: 0+1=1, 1+1=2, 1+2=3, 2+3=5, etc. We can then say that fibo(0)=0, fibo(1)=1, and for n greater than 1, fibo(n)=fibo(n‑2)+fibo(n‑1) -- very straightforward!
Trivia: Fibonacci actually stands for "filius Bonacci", or "son of Bonacci". Fibonacci was also famous for having introduced Arabic numbers to Europe, replacing the more cumbersome Roman numerals. His Fibonacci series derives from the solution of a puzzle he posed, related to rabbits that reproduce according to some easy rules!
We can directly implement this in JavaScript by using recursion.
const fibo = (n) => {
if (n === 0) {
return 0;
} else if (n === 1) {
return 1;
} else /* n > 1 */ {
return fibo(n - 2) + fibo(n - 1);
}
};
The function performs correctly, and everything's fine and dandy... except that the code is quite slow! I timed the function for many values of n, producing the chart below (which you can find in my Mastering JavaScript Functional Programming book). The chart shows exponentially growing times for a simple calculation that should require just a few sums... what gives?

To understand the root cause for those delays, let's just map out the calls when calculating fibo(6). The image below (also from my book) helps see the underlying problem... too many repeated, unnecessary function calls!
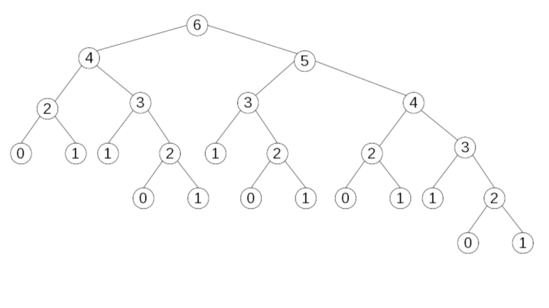
We can check: there's one call for fibo(6) --fine!--, one for fibo(5) --also fine!--, but fibo(4) gets called twice, fibo(3) three times, and counts are even worse for the remaining fibo(2), fibo(1), and fibo(0).
How many calls are needed to calculate fibo(n)? Naming it calls(n), calls(0)=calls(1)=1 (no recursion needed) and if n>1 calls(n)= 1+calls(n‑2)+calls(n‑1): the call to fibo(n) plus calls for fibo(n‑2) and fibo(n‑1). The sequence goes 1, 1, 3, 5, 9, 15, 25 (the calls for fibo(6); check it out!), 41, 67, 109, etc. These numbers are called Leonardo numbers but the name seems to come from Fibonacci's name (Leonardo Bonacci), not from Leonardo da Vinci's.
So, it's clear that our recursive method is wasting lots of time redoing work that had been already done... how can we solve this?
A particular solution
The kind of problem we are trying to solve is quite frequent; for instance, in Dynamic Programming (an optimization technique for certain classes of problems) we also get repeated calls (as in our Fibonacci example) that redo previously done work. We can solve the problem of skipping those repeated calls by rewriting parts of our code, making our function more complex, and working with a cache.
const already_calculated = {};
const fibo = (n) => {
if (!(n in already_calculated)) {
if (n === 0) {
already_calculated[0] = 0;
} else if (n === 1) {
already_calculated[1] = 1;
} else /* n > 1 */ {
already_calculated[n] = fibo(n - 2) + fibo(n - 1);
}
}
return already_calculated[n];
};
We will use an object (already_calculated) as a cache. Whenever a fibo(n) call is made, we first check if we already did this calculation, testing if n is already in our cache. If that isn't so, we do our work to calculate the needed result, and we place it in the cache. The result is always returned from the cache: return already_calculated[n].
This works (test it out!) and performance is great because if there are any repeated recursive calls, they are summarily dealt with by getting the needed value from the cache. But, there are some not-so-great points about the solution:
- we had to use a global cache object (
already_calculated), but global variables aren't a good idea in general - we had to modify the code for our function to use the cache, and changing code may always introduce errors
- our work doesn't scale: if we have to optimize several functions, we'll need more global variables and more code changes
The idea works (we can see that!) but we need a more general solution, optimally not involving the disadvantages listed above: the answer is Memoization, a functional programming technique.
A first general solution
Our problem is finding a way to avoid redoing long, slow calculations, that we have already done before. Memoization is a generic functional programming technique that you can apply to any pure function, meaning a function without any side effects, which always produces the same result if called with the same arguments.
Memoizing a function produces a new function that will internally check a cache of previously calculated values, and if the needed result is found there it will be returned without any further work. If the value isn't found in the cache, all required work will be done, but before returning to the caller the result will be stored in the cache (as we did by hand in the previous section) so it will be available for future calls.
As we don't want to modify our original code, we'll want to write a memoize(...) function that will take any generic function as an argument, and create a new one, which will work exactly like the original function but using caching to avoid repeated work. We can write such function in the following way:
const memoize = (fn) => {
const cache = new Map(); /* (1) */
return (n) => {
if (!cache.has(n)) { /* (2) */
cache.set(n, fn(n)); /* (3) */
}
return cache.get(n); /* (4) */
};
};
Our memoize(...) function is a higher-order function, because it receives a function as its parameter, and returns a new function as its result; a common pattern in Functional Programming. What's the returned function like? A cache map is defined at (1) -and using a JavaScript Map is more appropriate than using an object as a map- and the cache variable will be bundled together with the returned function by using a closure; no need for any global variables here! The new function starts by checking (2) if the cache already has the needed result; if not, we do the calculation (3) and set the result in the cache. In all cases, the returned value (4) comes directly from the cache. Elegant!
We can test this easily enough; we would write the following.
const fibo = memoize((n) => {
if (n === 0) {
return 0;
} else if (n === 1) {
return 1;
} else {
return fibo(n - 2) + fibo(n - 1);
}
});
Note that this is the same code as before, with the only difference that we enclosed the body of the fibo() function with a call to memoize(). If we test this function, no matter what value of n you try out, performance will be top-notch, and fibo(n) will be returned at full speed. However, our solution isn't really good enough... what if our original problematic function had expected two or three arguments instead of only one? We need to do better.
A truly generic solution
This is not generic enough; what would we do with functions with two or more parameters? The trick is to transform the arguments of the function into a string that we can use as a key for our map. That's easy to do by using JSON.stringify and our new version of memoize(...) would be as follows.
const memoize = (fn) => {
const cache = new Map();
return (...args) => {
const strX = JSON.stringify(args);
if (!cache.has(strX)) {
cache.set(strX, fn(...args));
}
return cache.get(strX);
};
};
This is generic enough and we can use it for all functions, no matter how many parameters they expect -- it would even work with functions with a variable number of parameters; can you see why? Our memoization function is quite efficient, also, but if you need memoization in your code, you'd do even better by using fast-memoize, which boasts of being the speediest available memoizer; you can read how it was written in How I wrote the world's fastest JavaScript memoization library by Caio Gondim.
We've seen a performance problem, and how we could solve it with specific or generic solutions... but before considering what some common Web UI frameworks provide along the lines of memoization, let's see a possible bug.
Frontend Monitoring
Whether you're seeing performance issues that require a memoization solution or not, Asayer is a frontend monitoring tool that replays everything your users do and shows how your web app behaves for every issue. It’s like having your browser’s inspector open while looking over your user’s shoulder.
Asayer lets you reproduce issues, aggregate JS errors and monitor your web app’s performance. Happy debugging, for modern frontend teams - Start monitoring your web app for free.
A subtle error!
You may see the code above, and wonder: why didn't I write the following code to avoid modifying the definition for fibo(n)?
const betterFibo = memoize(fibo);
Therein lies a subtle error, but let's first see it in action! First, I timed some calls to the original, un-memoized fibo() function. (I wasn't quite careful with the timing, and I didn't take several measurements; you'll see why that wasn't needed.) Times were something like the following -- and note I did calculate fibo(45) twice... and it obviously (roughly) produced the same times; surely the load in my computer varied somewhat between experiments, but that's not important.
| n | fibo(n) |
|---|---|
| 45 | 17644 ms |
| 45 | 17652 ms |
| 40 | 1602 ms |
| 35 | 135 ms |
| 30 | 12 ms |
| 25 | 1 ms |
I repeated the tests with the memoized fibo(n) function, and they showed the expected big enhancements. The first calculation took only 7 ms, and all the others took just about nothing because all the required values had been previously calculated when finding fibo(45). Great, everything as expected!
| n | memoized fibo(n) |
|---|---|
| 45 | 7 ms |
| 45 | 1 ms |
| 40 | 1 ms |
| 35 | 1 ms |
| 30 | 1 ms |
| 25 | 1 ms |
Now I repeated the tests, but using betterFibo(n), and unexpected results pop up! The first call takes as long as the original fibo(n) function? The repeated call to betterFibo(45) is quite fast, so it's using the cached value... but all the other calls are slow again?
| n | betterFibo(n) |
|---|---|
| 45 | 17692 ms |
| 45 | 1 ms |
| 40 | 1749 ms |
| 35 | 186 ms |
| 30 | 16 ms |
| 25 | 1 ms |
The problem is important and may easily be missed. The key is that betterFibo(n) internally is calling the original fibo(n) function, and not the memoized one. The result for betterFibo(45) does get cached (and thus the optimized 2nd row in our table) but all the other calls to fibo(n) aren't cached, and performance is logically as bad as earlier.
What would have worked is writing something like this - but note that we didn't use const in the definition for fibo(n).
let fibo = (n) => {
if (n === 0) {
return 0;
} else if (n === 1) {
return 1;
} else /* n > 1 */ {
return fibo(n - 2) + fibo(n - 1);
}
};
fibo = memoize(fibo);
The other way that would have worked would be defining fibo(n) in the classical way, without using an arrow function.
function fibo2(n) {
if (n === 0) {
return 0;
} else if (n === 1) {
return 1;
} /* n > 1 */ else {
return fibo2(n - 2) + fibo2(n - 1);
}
}
fibo2 = memoize(fibo2);
The fibo2(n) function performs perfectly well, because in JavaScript you may reassign a function. However, if you are using ESLint you'll get an objection, because reassigning functions is often a source of bugs, and the no-func-assign rule prohibits it.
Memoizing or caching?
You must be careful when reading about "caching" or "memoizing" in the documentation for frameworks such as Vue or React because it doesn't mean what you would think it does. For instance, in Vue you have computed properties and their documentation says that "computed properties are cached based on their reactive dependencies [and] will only re-evaluate when some of its reactive dependencies have changed." Similarly, the documentation for getters for computed values in Vuex mentions that "a getter's result is cached based on its dependencies, and will only re-evaluate when some of its dependencies have changed". These two references don't imply memoizing: only that Vue is smart enough not to redo the calculation for a computed value if none of its dependencies have changed: if a computed value depends on attributes X, Y, and Z, Vue won't recalculate the computed value unless X, Y, or Z changes; meanwhile, it will cache the previously computed value.
A similar problem is present in React. The useMemo() hook says that it "useMemo will only recompute the memoized value when one of the dependencies has changed" -- essentially the same thing Vue does, but not actually memoization; it only remembers a single previous calculation. Then again, useCallback() does the same kind of limited caching, and it's clear because useCallback(fn, dependencies) is equivalent to useMemo(()=>fn, dependencies). Finally, React.memo(...) also does a similarly simplified caching optimization, just avoiding redrawing a component if its props are the same as in the last call -- but it doesn't do memoization in all its glory, just caching one previous result.
Summary
In this article we've seen several approaches at memoization, and how using it may speed up your code. However, don't err by thinking that memoization is a "silver bullet" for all speed problems; it may even make your problems worse! Note that memoizing implies two added costs: you need extra cache memory for all the already calculated values, and you need some extra time to check and use the cache itself. If you are working with a function that seldom (if ever) gets called with the same arguments, memoizing won't have any positive impact, and you'd be probably better off by skipping it. As always, you shouldn't do optimization "on instinct"; measure first!
The solution we've seen here applies to common functions, but what about functions that do some I/O as API calls? You could also consider using memoization for promises, which would not only provide the expected optimizations but also enable other patterns that would produce more responsive code; see you!

Top comments (0)