
Hi there you all! Yes I know, the title it's a bit weird: I was supposed to document my project during the Twilio hackathon; but alas I didn't have the time to do it. So, I decided to do a kind of post mortem describing the part that took me the longest to develop. On top of it, celebrating my second first post on DEV I wanted to tackle this with a different angle.
Instead of doing a by-the-book tutorial, Which would make me look super smart, I want to walk through my thought process and document all the gotchas along the way; whilst keeping this as beginner-friendly as possible. So let's start!
What are we going to build?
We are going to build a virtual bot using Twilio Autopilot, In the end, this bot will work via a Whatsapp channel, but Autopilot allows you to connect to several other channels without changing your bot's code. This fancy bot will ask the user for its name and will store it in a database along with the user's phone number and country. Use case for this? Well maybe you are building a virtual assistant or you just want to bot to be polite and greet the user via their name; the possibilities are endless!
The stack
You probably guessed by now the building blocks we need: firstly, we need to persist data; so we need a database. Also, we need something to interact with that database and do some processing, like figuring out the user's country. For the former, I used FaunaDB: a multi-cloud decentralized database service and, for the later, the Fastapi framework: an ASGI framework built for the modern Python.
Wait, what?
"Wait a minute Alessandro", I hear you say, "That's a lot of sophisticated technical mumbo-jumbo you have there, care to elaborate?" Sure, let's see what these technologies are all about and why I choose them.
FaunaDB

Fauna it's a NoSQL database that's "built for the JAMStack", that last part means that it's designed to be accessed directly from front-end applications and, because of that, it offers the possibility to set permissions in a very granular way; so you can control with precision which users can access what data.
The NoSQL part means (you guessed it) that it does not use the Schema Query Language for making queries to the data; but this name can come with a bit of an understatement: it also means that it makes no assumptions about the shape of your data (hold this); so that means that, inside a collection of data (say users for example), we can find inconsistencies in records; for example: maybe a user record has a last name field but other user doesn't.
The decentralized part means that your database it's replicated across multiple instances, that's a fancy way of saying that there are a bunch of copies of your database scattered across several different servers. Why is this good? Because this offers data redundancy; sure, maybe you've heard that data redundancy it's the root of all evil and it must be eradicated from the face of the earth, but that depends on the context. In this case, it's good because it means that, if one of your servers fails, the other replicas are there to ensure that your service does not interrupt and, more importantly, that you don't lose any data; it also means that data will be server from the replica geographically closet to the user, resulting in faster response times. This replication it's harder to achieve when you have to set it up by yourself, but Fauna abstracts away all this hassle for us.
Why I choose it
Well all this explanation sound well and good, but the reasons I chose it are far less romantic:
1) Cost, as in money: as devs, when we embark on a side project that needs to be hosted live, we try to minimize costs as much as possible. And database hosting is one of those things that can be costly, especially if you don't pay much attention to the pricing model: you can end up with a bill that's higher than you expected. Fauna has a great free plan that's more than enough.
2) The nature of the schema: as you have noticed, the data schema it's pretty simple (name, phone number, and country); so spinning up a whole relational database with SQLAlchemy, migrations, and such was a bit overkill.
3) Sheer curiosity: Being a database built for serverless, I was curious to see if Fauna could adapt to a more traditional application, and since they have a Python driver that was a no brainer (Spoiler alert: it does, kinda).
FastAPI
![]()
FastaAPI is an Asynchronous Standard Gateway Interface (ASGI) framework built for the modern Python. It's built upon two great projects: Starlette (another ASGI framework) and Pydantic (a validation library with zero dependencies). So, what's ASGI anyways? Well, it's the natural evolution of Web Server Gateway Interface (WSGI).
You see, if you have worked with a WSGI framework (like Flask or Django) you know that they have built-in servers; so you can just test your application in real-time when development, usually with nice logging and live reload built-in. Thing is that, when the project gets deployed, that dev server won't cut it: you'll need a real server like Apache's HTTP Webserver, Nginx or IIS. But the detail it's that those servers are usually written in C/C++ and they handle requests via sockets and all that low-level stuff, they don't speak Python! So you need a "glue" for the servers to be able to call your Python application, that's were WSGI came in.
The problem with WSGI it's that it is synchronous: it cannot take advantage of asynchronous programming, thus it's often "slower" than pure asynchronous applications like those written with the Express framework or the Go programming language.
For that, ASGI was created: it brings a new interface that supports asynchronous code on the server-side with Python's async/await syntax and also brings new features like HTTP/2 support and Websockets.
I won't be diving into more details about this, that would be a post in its own. But you can find plenty of material on the web or here in DEV
Why I choose it
1) Because of Python!
2) I had my eye on FastAPI for a while and was just looking for an excuse to use it
Yeah, a couple of pretty objective well-researched reasons right there; thank you very much.
The bot

So now, let's get into the bot's design. First, let's head to Autopilot's documentation and we'll that bots are composed as follows:
- The unique name of the bot
- The
defaultssection, which defines (you guessed it) default behaviors for your bot: the default task, default task to run on errors and the default task to run in case acollectaction fails (well's see what this is later on). - The
styleSheetdefines the "personality", here we define the default messages to say in case of errors or success, the default behavior ofcollectactions, and the voice for the bot (this in case we use the bot for automatic phone calls). - Tasks: the tasks (duh) they need to perform; each one with a name
- Actions: the individual actions that these tasks trigger.
- Samples: the part of the conversation that triggers this task.
- Fields: pre-defined fields that hold special value and will appear in your samples (we'll also see what's this about later on)
I will only be explained the tasks needed for this bot, so, for the complete list check the docs.
We can also see that task are a simple JSON schema and that there are two types of actions:
1) Static: those defined in the bot's JSON schema.
2) Dynamic: those that are returned from an API, must comply with the JSON schema.
As you probably have guessed by now, static actions cannot perform any kind of logic: they only trigger, perform the actions described in the schema, and end. If we are to do any kind of logic, we must use dynamic actions.
So, with this in mind, let's see which tasks we need. For the sake of making this article less boring, let's throw a flowchart right here:
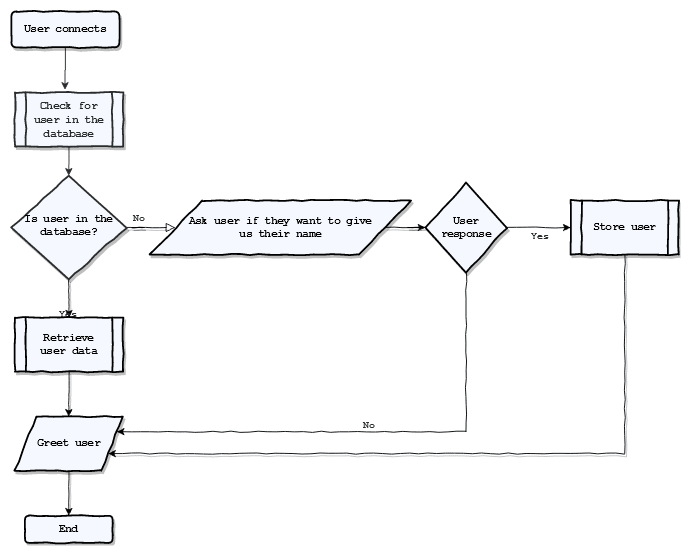
From the flowchart's decision and process blocks, we can easily determine, not only the number of actions needed but also which actions are dynamic and which are static.
The static actions would be:
- Ask the user if they want to give us their name; this question needs to be broken down into two, we'll see why in a moment.
- The action that takes place after the user response decision block.
The only dynamic action will be the greet action since we need to check if the user is already in the database to build the appropriate greeting message.
Creating the initial schema
Ok, now that we determined how many actions we need; let's create the actual schema that will describe our bot. In this post, we'll be writing only the static actions; while the dynamic will be written in the next post. First of all, you need to know that there are two ways of developing an Autopilot bot: first one it's through the Twilio Dashboard, and the second one it's by editing the bot's JSON schema directly. In this little project, we'll be using the latter.
Setting up the schema
There are a bunch of templates ready for us to use; we'll be using the HelloWorld template since the other ones don't quite fit our use case. So go to that link and download the schema.json file inside Assistants/HelloWorld.
Let's open up the file with our favorite editor, first of all: we'll change our bot's name. Something like almighty-bot will do, so let's go and change the uniqueName and friendlyName keys:
{
"friendlyName" : "The almighty bot",
"logQueries" : true, // This activates logging messages to the Twilio Dashboard
"uniqueName" : "almighty-bot"
// The other stuff
}
Now, we'll see that the schema has only four tasks; two of which are fallback actions in case of error. Let's write the static actions we defined above:
Asking for the name
For asking information, we use the collect action. This action takes a name, an array of questions that will be made in the order they are defined, and an on_success callback; which can be an HTTP endpoint or another task.
Remember I said that this action needs to be broken down into two? Well, imagine that our bot asks the users for their name and the user responds with a negative answer, what do we do? As stated above, we cannot perform any logic in static actions; so we need to call an endpoint with our user's response (that is if they want to give us their name or not) and proceed accordingly; just like the flowchart above.
So, let'a add our very first task; inside the schema's actions array add:
{
"uniqueName":"can-have-name",
"actions":{
"actions":[
{
"collect":{
"on_complete":{
"redirect":{
"method":"POST",
"uri":"our_super_yet_to_be_endpoint/can-have-name"
}
},
"name":"ask-for-name",
"questions":[
{
"type":"Twilio.YES_NO",
"question":"Do you want to tell me your name?",
"name":"can_have_name"
}
]
}
}
]
},
"fields":[
{
"uniqueName":"can_have_name",
"fieldType":"Twilio.YES_NO"
}
],
"samples":[
{
"language":"en-US",
"taggedText":"{can_have_name}"
}
]
}
Ok, so, what kind of wizardry did we just do? First of all, the task needs a unique (machine-friendly) name. After that, we write the actions the task will perform. In this case, we are doing a collect. Our collect task has:
- A name:
ask-for-name - An
on_completekey, the action that'll be performed when thecollectends. In this case, we are instructing the bot to do an HTTP call. - An array of questions, a question must have:
- A type.
- The actual question's text.
- A name, this is the key we'll use to parse the answers in our API; so put a programming language friendly name.
Notice that the type is Twilio.YES_NO; Autopilot already has a bunch of pre-defined types for the most common questions you'll need. These types are already trained to do natural language recognition; so we'll use it whenever we can.
Finally, notice the fields and samples keys. Like I stated above, fields are pre-defined, well, fields, that act like variable names and samples are the inputs that will trigger this particular task. All collect actions must have at least one sample (Twilio recommends at least 6) but, since we're expecting only a yes or no, we'll only add one sample, which sample? Well, since we're just expecting a yes or no, let's create a field with that type and add it to the samples enclosing the field's name with curly braces. Yes, I know this part with the samples and fields it's not clear at the moment; but bear with me, it'll be clear with the next task.
Now, let's add the actual question for asking the name:
{
"uniqueName":"store-user",
"actions":{
"actions":[
{
"collect":{
"on_complete":{
"redirect":{
"method":"POST",
"uri":"our_super_yet_to_be_endpoint/store-user"
}
},
"name":"collect-name",
"questions":[
{
"type":"Twilio.FIRST_NAME",
"question":"Great! What's your name?",
"name":"first_name"
}
]
}
}
]
},
"fields":[
{
"uniqueName":"first_name",
"fieldType":"Twilio.FIRST_NAME"
}
],
"samples":[
{
"language":"en-US",
"taggedText":"I'm {first_name}"
},
{
"language":"en-US",
"taggedText":"{first_name} it's what I'm called"
},
{
"language":"en-US",
"taggedText":"{first_name} is my name"
},
{
"language":"en-US",
"taggedText":"people call me {first_name}"
},
{
"language":"en-US",
"taggedText":"people know me as {first_name}"
},
{
"language":"en-US",
"taggedText":"{first_name}"
},
{
"language":"en-US",
"taggedText":"my name is {first_name}"
},
{
"language":"en-US",
"taggedText":"i'm {first_name}"
}
]
}
Now, what's going on here it's pretty much the same we did on the previous task: the only changes are the type of the question (now we tell Autopilot to try to recognize first names), the fields and samples and the URI of the endpoint. Remember that about fields being like variable names? So, imagine that the answers you're waiting for it's in the middle of a broader sentence, like: "I'd like to make an appointment at 3 o'clock" or "My name is John"; that's where the fields come in: by defining a field, we can write samples and tell Autopilot on which part of the sample we expect our answer to be. If we take a look at the samples above, we'll see the field name ({first_name}) we defined in the part of the sentence we expect our answer to be; the more samples the better. So now, If our user texts something like "My name is John"; that will trigger the "my name is {first_name}" sample and Autopilot will parse it as the answer of the current active question.
The final action
This is the action that'll take place after the user has (or not) give us their name. For the sake of simplicity we'll thow a placeholder:
{
"uniqueName":"placeholder",
"actions":{
"actions":[
{
"say":"Almighty bot under construction"
}
]
},
"fields":[],
"samples":[]
}
Here, we're introducing the say it (you guessed it again) simply sends a text to the user.
Wrapping up
That's all for this post! Not a lot of writing code I know, we'll be writing the API that wires all this up in the next post; so stay tuned😉
PS: I know, I need to work on post-titling skills

Top comments (0)