
Virtual DOM in React make us able to define the view declaratively. We write what the view is and what is it’s content.
There is no need to instruct interpreter where it should update particular html tag or what should be added/deleted to the specific node. Our job ends up on view declaration, the engine is responsible for the underlying mechanism of DOM manipulation.

The issue is, in order to declare view in React and then run render phase (in which we check what has changed etc.) the engine needs to build entire Virtual DOM. It runs diffing algorithm to compare the previous tree with the new one. This process is called reconciliation. The old Virtual DOM persists just to be compared with the new one after each render, which might run on every state change.

In this way Virtual DOM stores the canonical representation of the DOM in memory. This of course is fast. Exceptionally faster than solution designed by jQuery or AngularJS. That is the obvious reason why React dominated these technologies, not to mention the strong community around React. Right, it’s fast but it also has some drawbacks. The creation of the Virtual DOM trees happens in runtime. Created objects obviously consume additional memory. It might happen with every state change. On every atomic change. The engine needs to do the same job again and again.
So the question may come to your mind - Can we eliminate this repeated process? It turns out that the answer is (maybe not surprisingly) yes. The well-known Virtual DOM it’s not the goal by itself. If only there was a better idea to improve performance then Virtual DOM is no longer needed. Apparently, there is a better approach to achieve the same and consume less. It’s called Incremental DOM. We can find it’s implementation in Angular engine (from the v9) - Ivy. Another example is Svelte which uses it under the hood of its compiler. In basic terms, this approach gets rid of artificial DOM objects (which is the foundation of Virtual DOM). Rather tools that implement Incremental DOM are compiled based on the context of the particular view.
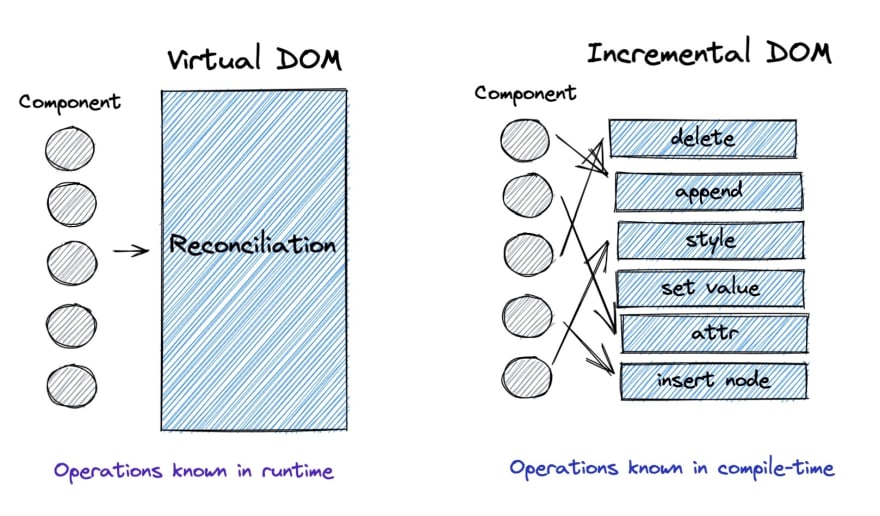
Compiler analyses what is the template of the view and how the app changes its state. Based on that data it indirectly makes updates to the view. The mechanism tracks which variable impacts re-rendering of which HTML tag. Instead of creating an entirely new object which represents the current state of DOM listening on each user event or state change that propagates DOM manipulation in runtime the compiler generates a sequence of instructions (creating a div, adding attributes, deleting particular node) and adds it to the final bundle. Incremental DOM is thus tree shakable - we know in advance what will be needed in runtime This code is mounted in a place where the change of the state happens. In the process, no additional memory is consumed which has implications for memory-constrained devices.
Now you may ask - So which approach would be the best for my app? - The answer is what you may expect from these kinds of questions - It depends ;) Ultimately it depends on which device your dear users uses your app (memory constraints are largely impacted by the hardware of the device) and on which browser (rendering speed is largely impacted by the browser’s rendering engine).
As always use the right weapon for the right enemy. Don’t assume that one or the other is the best in any case.





Top comments (1)
Safe tree and protect environment
dua to make wish come true