YugabyteDB is composed of two layers: PostgreSQL, for the YSQL API, plugged on top of DocDB, the distributed storage and transaction. DocDB is also accessed by other APIs, like the Cassandra-like YCQL. And then the namespaces are different. In DocDB, tables or indexes are identified with a table_id. DocDB doesn't hold a full dictionary, but the table_name and keyspace_name attributes are also recorded. This is what you will see in DocDB statistics, lotgs, or console, like the Web GUI from the http://master:7000 endpoint:
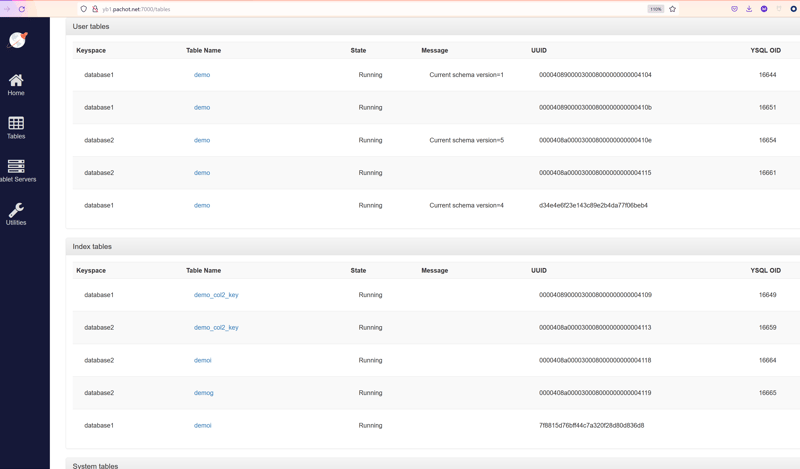
One table and one index have a table_id that look like a random Version 4 UUID: d34e4e6f23e143c89e2b4da77f06beb4 for table demo and 7f8815d76bff44c7a320f28d80d836d8 for index demoi in keyspace database1.
I've created them from YCQL, the Cassandra compatible interface, with:
create keyspace database1;
use database1;
create table demo(col1 int primary key, col2 int)
with transactions = { 'enabled' : true };
create index demoi on demo (col2);
But the others show version 3 UUID (according to the 13th digit), and have duplicate keyspace and table name. The clue is in the YSQL OID column: this is the PostgreSQL OID.
Those tables where created from YSQL, the PostgreSQL compatible API, with:
create database database1;
create database database2;
\c database1;
create schema schema1;
create schema schema2;
create table schema1.demo (col1 int primary key, col2 int unique, col3 int, col4 int[]);
create table schema2.demo as select * from schema1.demo;
\c database2;
create schema schema1;
create schema schema2;
create table schema1.demo (col1 int primary key, col2 int unique, col3 int, col4 int[]);
create table schema2.demo as select * from schema1.demo;
create index demoi on schema1.demo(col3);
create index demog on schema1.demo using gin(col4);
SQL is can have complex schemas and is more agile. Within a cluster we have:
- multiple databases (
database1anddatabase2) here in addition to the system ones). They map to thekeyspacein DocDB - multiple schemas (
schema1,schema2) which are different in each database even if I used the same name to confuse you (or rather to show what can happen). The schema name is not known at DocDB level - tables and indexes in schemas (user created, or public). This is displayed as table name in DocDB, but is not unique even within a keyspace because there can be different schemas, and APIs (I've used the same table name in YSQL and YCQL to confuse you even more ;)
- Tables have a unique owner, which is not known at DocDB level
This has one consequence, you cannot identify a table with the keyspace_name,table_name pairs. You need the table_id.
In my example, if I click on the first line demo it goes to the table details with http://master:7000/table?id=00004089000030008000000000004104. It shows PGSQL_TABLE_TYPE as its type. This means PostgreSQL table type, identified with the PostgreSQL OID, the YSQL OID. If I click on the last line, I go to http://master:7000/table?id=7f8815d76bff44c7a320f28d80d836d8 which shows YQL_TABLE_TYPE. This means that it was created by the YCQL API. And this table is actually an index - all are LSM-Trees in Yugabyte, the log structure being best suited to replication.
As usual in IT, the naming may be confusing because there is an history behind it, even for a new database like YugabyteDB. YugabyteDB started with the distributed storage, DocDB, storing tables in keyspaces. Those are the same terms as used in Cassandra. Then the first API was the YugabyteDB Query Language (YQL). But then came a more sophisticated one, the SQL API, so that YQL became YCQL (C for Cloud but you can hear Cassandra in it). And The SQL API was YSQL. But who knows, one day, we may have a MySQL compatible API, so internally we must know where the table comes from (the OID has a meaning for PostgreSQL only) and this is the PGSQL table type.
You know this quote attributed to Phil Karlton: "There are only two hard things in Computer Science: cache invalidation and naming things". The Current schema version=2 in the screenshot above is about cache invalidation (the dictionary is in the master, cached by the tserver sessions, so each DDL increases the version number). The naming difficulty is because of the flexible two-layer architecture of YugabyteDB. Each layer may have its own vocabulary. Don't panic, the Developer Advocates are there to help, as I did in a previous post about the "partitioning" - term that has a meaning in DocDB (from the Cassandra sharding vocabulary) and in YSQL (from the PostgreSQL declarative partitioning).
I mentioned that keyspace_name,table_name cannot identify a table. But you can use it, like: http://yb1.pachot.net:7000/table?keyspace_name=database1&table_name=demo and, even if there are YSQL tables with this attributes, this implicitly goes to the YCQL one, or show Table not found! if there's no YCQL ones. Because, in YCQL, keyspace_name,table_name identify a table (or index).
Now, you know that you can identify any table, YCQL or YQL, with its table_id (displayed in the UUID column) and, as you speak 0x currently, you may have recognized that the last 4 digits are actually the hexadecimal for the PostgreSQL OID (displayed in the YSQL OID column). There's also 3000 and 8000 in it as a magic number for YSQL. And the first digits are the OID of the database (which name is displayed in the keyspace column).
The layout is:
pg_database.oid pg_class.oid
vvvv vvvv
00000000-0000-3000-8000-000000000000
^ ^
UUID version 3 variant DCE 1.1, ISO/IEC 11578:1996
Saying it in English is not easy, but fortunately all is normalized and can be fetched from SQL:
select
'0000'||lpad(to_hex(datoid::int),4,'0')
||'0000'||'3000'||'8000'
||'0000'||lpad(to_hex(reloid::int),8,'0')
as uuid, datname, relname, relkind, amname, nspname from
(select oid reloid, relname, relnamespace, relkind, relowner, relam from pg_class) rel
natural left join (select nspname,oid relnamespace from pg_namespace) ns
natural left join (select amname,oid relam from pg_am) am
cross join (select datname,oid datoid from pg_database where datname=current_database()) dat
where nspname not in ('pg_catalog','information_schema')
order by relkind desc, 1
;
And you can recognize the same as in my screenshot, with the table or index name (internally called "relation" - relname in PostgreSQL, and typed with relkind), schema name (internally called "namespace" - nspname in PostgreSQL), database name (datname with its oid being in the table_id):
uuid | datname | relname | relkind | amname | nspname
----------------------------------+-----------+---------------+---------+--------+---------
0000408a00003000800000000000410e | database2 | demo | r | | schema1
0000408a000030008000000000004115 | database2 | demo | r | | schema2
0000408a000030008000000000004111 | database2 | demo_pkey | i | lsm | schema1
0000408a000030008000000000004113 | database2 | demo_col2_key | i | lsm | schema1
0000408a000030008000000000004118 | database2 | demoi | i | lsm | schema1
0000408a000030008000000000004119 | database2 | demog | i | ybgin | schema1
(6 rows)
I queried from database2 which is the reason you see only the tables and indexes that were in the keyspace database2 in the screenshot above.
The 2 Tables (relkind=r with oid 0x410e and 0x4115) and 3 Indexes (relkind=i with oid 0x4113 0x4118 0x4119 ) are there. The access method (amname) are lsm for LSM Tree indexes and ybgin for the YugabyteDB implementation of GIN indexes on top of LSM Trees.
But you see no access method for the tables, and one additional LSM Tree index demo_pkey. The reason is that tables in YugabyteDB are stored in their primary key index (as in MySQL InnoDB, SQL Server clustered indexes, or Oracle IOT) for fast access by the primary key. PostgreSQL dictionary is designed for heap tables where all indexes are secondary, including the one to enforce the primary key. This is why the physical name of the table, with the _pkey suffix, is an index (relkind='i' and amname='lsm'). The logical name, with relkind='r', is the one giving its oid to the table_id.
There are a few more subtleties. Colocated tables share the same storage:
create database database3 with colocated=true;
\c database3
create table demo1 (a int);
database3=# create table demo2 (a int) with (colocated=false);
create table demo0 (a int);
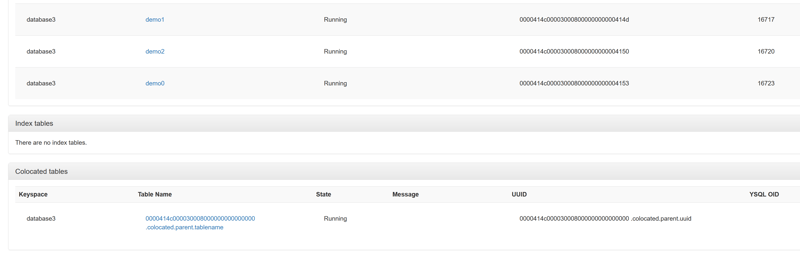
The tables, colocated or not are still visible with their UUID composed of the database OID and table OID:
uuuid | datname | relname | relkind | amname | nspname
----------------------------------+-----------+---------+---------+--------+---------
0000414c00003000800000000000414d | database3 | demo1 | r | | public
0000414c000030008000000000004150 | database3 | demo2 | r | | public
0000414c000030008000000000004153 | database3 | demo0 | r | | public
Note that without defining a primary key, an internal key is generated but we don't see the LSM index.
The colocated tablet hasa UUID as a table one, with zeors for the table OID part, and some additional tags: 0000414c000030008000000000000000.colocated.parent.uuid
You can click on demo1 or demo0 as different tables, but they will show the same table id as they are colocated.





Top comments (3)
Thank you for this important information.
I wanted to check about the same table name with different schemas.
Since oid is an unsigned 4-byte integer, it has a maximum of 8 digits when expressed in hexadecimal (0xFFFFFFFF)
It seems better to write it as follows.
Thanks a lot. I've fixed it in the post.
Thx. This is the missing link between pg OID and yugabyte uuid.