Mapping data stored in a single row in a database to multiple objects in your object model is quite a common scenario. Dapper provides a specific feature to handle that and, if you are in the suitable use-case scenario, can help you to elegantly do the mapping with just a few lines of code.
Let’s say we have this object model:

and, just for the sake of making things look like more real world, let’s say that the database model is a little different:

How could we map the data returned by a query on such tables to our objects? If we would have had three tables also, once for each object — Users, Companies and Addresses — that could have been done using the Multiple Resultsets feature as discussed in the previous article, or even by just executing three separate queries.
We already know that such approach would have been sub-optimal (as a general rule) since the correct solution, from a database perspective would have been to join the three tables (be sure to read more about this in the “About Join” paragraph!)…but here we don’t even have this option because we just have company and address information in just one table (Companies), while in the object model such information are stored in two different objects (Company and Address).
Since we strive to have the best performance possible, we follow the advice that our friendly dba told us and we go for the join:
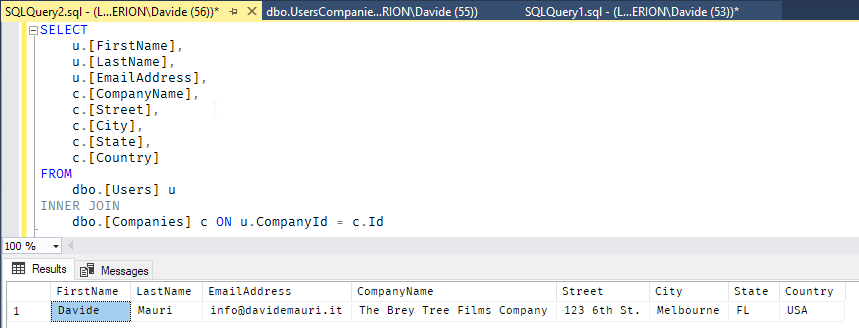
We now have to figure out how to map some data to one object, and some other data to others object. More specifically we want to map the data to the following model:

Dapper has a nice feature called Multiple Mapping that comes handy in this scenario. The Query method (and all the related variants, like QueryAsync, QueryFirst and so on) supports an overload that allows to specify how to split data across the objects. Here’s how it looks like:

That Query overload needs one type parameter for each object you want to map plus an additional one for the object it will return.
It may sounds a bit confusing at the beginning, but everything will become clear if you just think at it like if it was a Func delegate with "n" T parameters types and the last one, TResult, as the resulting parameter type.
Having that in mind is easy to see that the first three type parameters represent the types that will be instantiated, while the last one,User, represents the object that will be returned and that binds all the instantiated object together.
Now, what about the arguments passed to the Query overload?
The first argument is the query. In the sample the SELECT statement queries a view that encapsulates the query shown at the very beginning, that joins the two tables together.
The second argument is the mapping function. Not surprisingly it is really a Func delegate. Here the logic that binds the created object needs to specified. In our sample it is very simple since we just have to assign the Address object to company’s Address property and then assign Company to user’s Company property. Once this is done we return the highest object in the relationship chain, which is, of course, the User object.

The third argument is a comma-separated string that tells Dapper when the returned columns must be mapped to the next object. In our example the split string is set to:
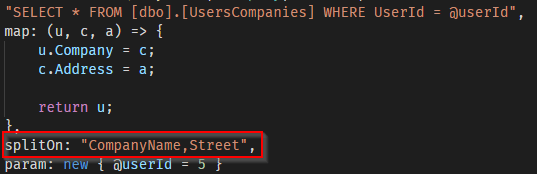
which means that until the CompanyName column is found, all the columns will be mapped to the first type parameter: User.
Once the CompanyName column is found, including itself, the mapping will be done against the next type parameter, which is Company.
As you may have guessed, then, once the Street column will be found, mapping will switch to populate the third object: Address.
Here’s a picture that easily describes how the mapping and the split logic works:

The fourth argument is the usual parameters object, needed by our query to filter the desired user.
Three Limitations
Now, that’s ok for 1:1 relationships, but what about 1:N? What if a company, instead of having just one address, could have more than one?
Unfortunately there is no way to solve such problem with the Multiple Mapping feature. Multiple Mapping is useful only if you have 1:1 relationships. There are some hacks and workaround on this if you search the web, but usually they compromise performance or simplicity (or both) to get the result.
Beside that, there is also another limitation we have to keep in mind: let’s say that we also need to return the ids of Users and Companies. So our new object model is like the following:

As you can see the Id property has the same name in the two objects. If we return the data using a join, we cannot have a resultset with two (or more columns) with the same name. Columns needs to be aliased so that the resultset will look like this:

But this means that Dapper won’t be able to map automatically UserId to User.Id and CompanyId to Company.Id.
There is a way to manually tell Dapper how to map columns to properties that will discuss soon so the problem will be easily solved, but that will make the code a little more complex than how it could have been.
As a last point, in addition to the limitations just described, we still have to manually define how the created objects are related together by writing the mapping function. Albeit really a simple task, is something we would happily avoid to write if possible, since it is just plumbing code.
Luckily if you are using SQL Server 2016 or above or Azure SQL there is a perfect solution that doesn’t have any of the mentioned limitations and that we’ll discuss in future articles that involve JSON usage. So stay tuned, because it will be very interesting.
About joins
Before closing the article, I think a little discussion on using joins vs not using joins is needed here, to make sure pros and cons are clearly exposed.
From a purely theoretical perspective, using joins to solve the described problems is surely the best solution.
From a more practical perspective, unfortunately, we need to take into account the fact the joins produces a lot of duplicate data. Let’s say that you have two objects “A” and “B”: for each item in “A” there are millions of rows in “B”. Once we join “A” and “B”, all the information we need for “A” will be returned for each related row in “B”, generating a huge resultset that we don’t really need. Is such case, then, avoiding the join in favor of two different and separate query is probably a better solution, performance wise.
So, depending on your scenario and data size, executing separate queries to get data for each object, or using a single query that joins the table are two options that must be evaluated, to find the correct balance between concurrency, consistency and performances.
Samples
Samples are available on GitHub:
Conclusion
With Multiple Mapping we can easily handle mapping of object between our database and our object model that supports 1:1 relationships between them.
It has some limitations but when you have the right scenario, it solves the problem is a very elegant and effective way. In the near future we’ll discuss how to solve all the described limitation using a powerful technique enabled by the JSON support in SQL Server 2016 (or above) and Azure SQL .
What’s Next
In the next article we’ll see all the SQL Server specific-feature that Dapper supports like Table-Valued Parameters, Spatial Data Types and HiearchyID. After that we’ll start to discuss the real advanced stuff: JSON support, Custom Mappers and Custom Handlers.

Top comments (0)