
SQL, which in full is Structured Query Language is one of the most important tools that a data scientist should be well versed with.
There are several variations of SQL and they include PostgreSQL, MySQL, Microsoft SQL Server, and Standard SQL. Here are some of the benefits data scientists enjoy when they have a good knowledge of SQL:
Data retrieval and filtering: SQL gives data scientists the power to retrieve and filter data from databases using powerful query language features. This makes it easy to extract specific data that is needed for analysis.
Data manipulation: data scientists can manipulate data by creating tables, adding and modifying data in the tables and deleting data from the tables and even entire databases if need be. This is useful when preparing data for analysis and also when performing data cleaning.
Data aggregation and summary: SQL also provides powerful aggregation and summary functions that make it easy to calculate summary statistics like counts, averages, and sums. This is helpful to data scientists when they are analyzing large datasets and when performing exploratory data analysis.
Joining data: Most of the time data will exist in multiple tables or data sources, and SQL allows data scientists to join these tables together to have a single view of the data. This is useful when analyzing data from multiple sources or when performing complex data analysis.
Integration with other tools: Many data analysis tools like Power BI which is a visualization tool and programming languages like Python and R can interact with SQL databases and this is a plus for a data scientist.
As a summary of the above points, SQL is an important tool for data scientists because it provides a powerful and flexible way for them to work with large or small datasets. SQL helps you extract, manipulate, and analyze data more efficiently and effectively.
You should be familiar with several SQL commands as a data scientist so that you can seamlessly work with datasets in SQL. Below are eight of the most important commands a data scientist should know and I have used PostgreSQL to visualize the first five of these commands to show how they are written:
SELECT: To obtain data from a database, use this command. It enables you to define the columns you want to retrieve as well as any data filtering requirements.
The command displayed below selects all values of the columns in the table called customer.
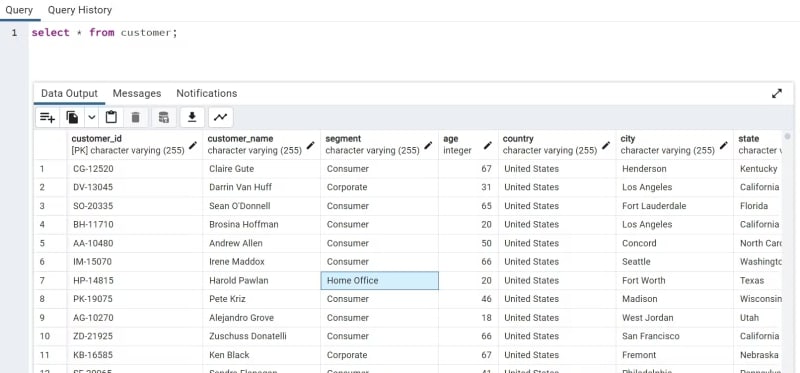
WHERE: Using this command, the material can be filtered according to predetermined standards. The WHERE command, for instance, can be used to only return entries with a certain column value.
The command displayed below will display the names of all customers whose age is below 20 years.
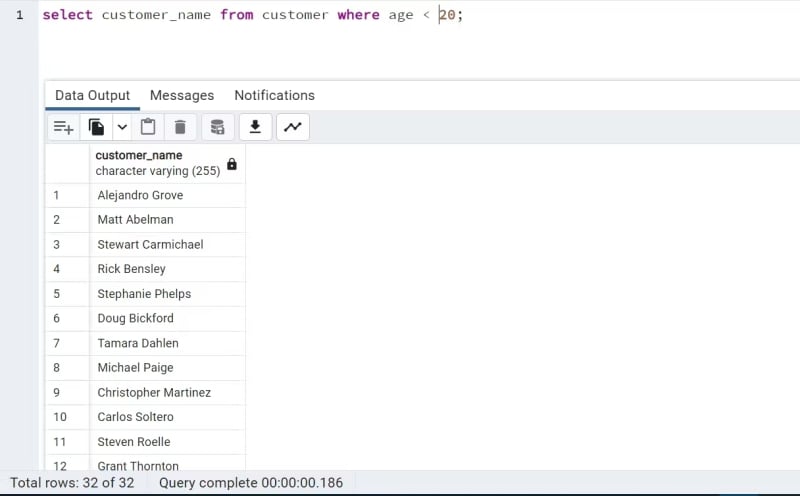
BETWEEN: This command is used to obtain values in a certain specified range.
The command below has displayed the name, city and postal code of customers who are between the age of 20 and 40 years.
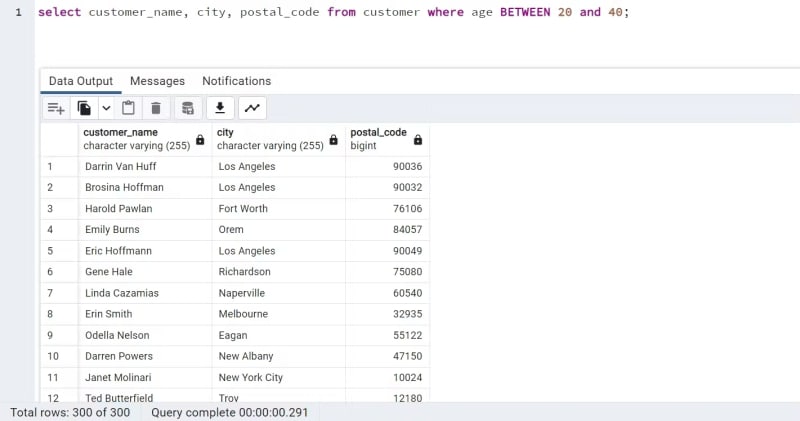
LIMIT: This command is used to restrict how many entries a query returns. For instance, you could retrieve only the best 10 records using the LIMIT command.
The command below is similar to the one in number (3) above but this time instead of displaying all values(rows), there is a limit of only displaying 10 values.

ORDER BY: This command is used to order the information a query has produced. You have the option to select the column or columns by which you want to order the data, ascending or descending.
The command below displays the name, age and postal code of customers who reside in the state of California in the order of their age.
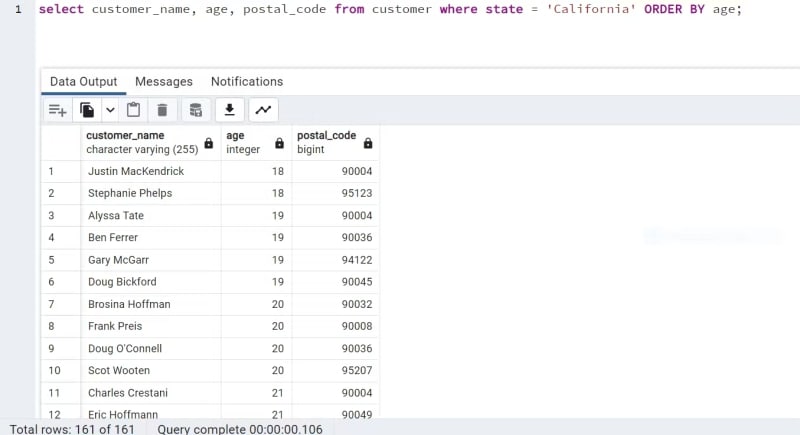
JOIN: Using a common column, this command combines data from two or more databases. There are various JOIN kinds, such as CROSS JOIN, OUTER JOIN, and INNER JOIN.
GROUP BY: This command is used to arrange data into groups according to a particular column or collection of columns. To determine aggregate data, such as the average or sum of a particular column, you could use the GROUP BY command.
HAVING: To filter groups based on overall data, use this command in conjunction with the GROUP BY command. For instance, you could use the HAVING command to only return groups where a particular column's average number exceeds a predetermined threshold.
These are just a few of the SQL commands that are commonly used by data scientists. Depending on your specific needs and the structure of your database, you may also need to use other commands, such as INSERT, UPDATE, and DELETE.
This is just an overview of what SQL can do and many resources provide in-depth resources on the same. My recommendation would be a site like w3schools which has well-curated SQL resources. After learning here, you can go to HackerRank and practice what you have learned with fun exercises.

Top comments (0)