Author: Jacob Marks (Machine Learning Engineer at Voxel51)
Apply transformer models directly to your computer vision datasets
Transformer models may have begun with language modeling, but over the past few years, the vision transformer (ViT) has become a crucial tool in the computer vision toolbox. Whether you're working on traditional vision tasks like image classification or semantic segmentation, or more du jour zero-shot tasks, transformer models are either competitive with, or are themselves setting the state of the art. Hugging Face's transformers library makes it incredibly easy to load, apply, and manipulate these models.
Now, with the integration between Hugging Face transformers and the open source FiftyOnelibrary for data curation and visualization, it is easier than ever to integrate Transformer models directly into your computer vision workflows.
In this post, we'll show you how to seamlessly connect your visual data and transformer models.
Setup
For this walkthrough, you'll need Hugging Face's transformers library, Voxel51's fiftyone library, and torch and torchvision installed:
pip install -U torch torchvision transformers fiftyone
What is FiftyOne?
FiftyOne is the leading open source library for curation and visualization of computer vision data. The core data structure in FiftyOne is the fiftyone.Dataset, which logically represents the metadata, labels, and any other information associated with media files like images, videos, and point clouds.
You can load datasets directly from the FiftyOne Dataset Zoo), or load in your own data — there's built-in support for loading from directories, glob patterns, or common formats like COCO.
For this walkthrough, we'll be using the Quickstart dataset, which is a subset of the COCO 2017 validation split:
import fiftyone as fo
import fiftyone.zoo as foz
dataset = foz.load_zoo_dataset("quickstart")
## just keep the ground truth labels
dataset.delete_sample_field("predictions")
💡 To get started work with videos, try out the Quickstart Video dataset
Once you have a FiftyOne.Dataset, you can filter it with pandas-like syntax.
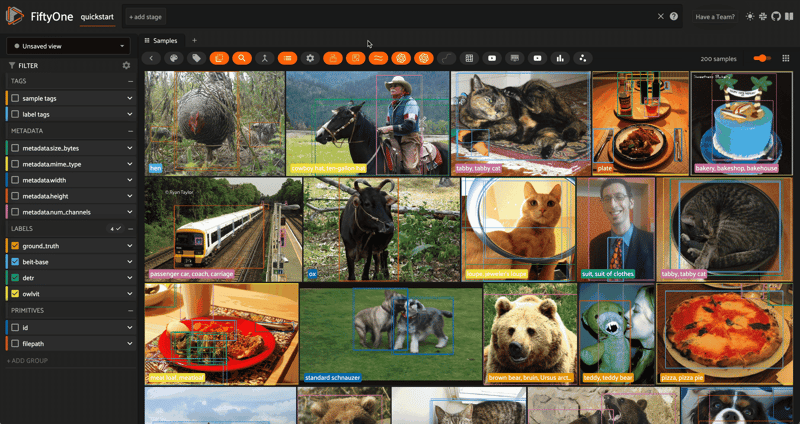
You can also visualize and visually inspect your data in the FiftyOne App:
session = fo.launch_app(dataset)
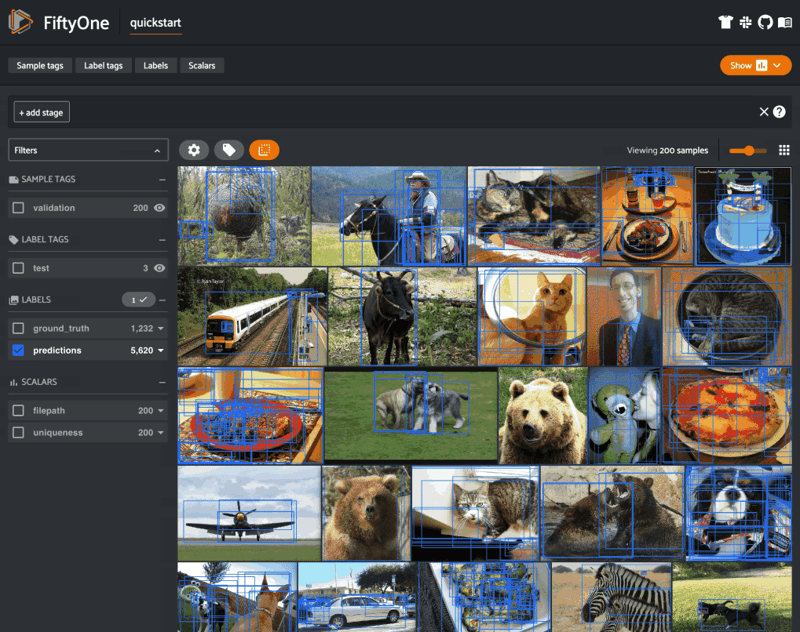
Why use FiftyOne? FiftyOne is built from the ground up for computer vision. It puts all of your labels, features, and associated information in one place, so you can compare apples to apples, stay organized, and treat your data as a living, breathing object!
Transformers Integration Overview
With the integration between fiftyone and Hugging Face transformers, you can apply Transformer models directly to your data — either the entire dataset, or whatever filtered subset you choose — without writing any custom code.
For inference, the integration supports:
- Image Classification: any of the models listed in the Transformers image classification task guide, including BeiT, BiT, DeiT, DINOv2, ViT, and more
- Object Detection: any of the models listed in the Transformers object detection task guide, including DETA, DETR, Table Transformer, YOLOS, and more
- Semantic Segmentation: DPT, MaskFormer, Mask2Former, and Segformer
- Monocular Depth Estimation: DPT, GLPN, and Depth Anything
- Zero-Shot Image Classification: any Transformer model which exposes both text and image features (get_text_features() and get_image_features()), such as ALIGN, AltCLIP, CLIP, etc, or supports image-text matching (XYZForImageAndTextRetrieval), such as BridgeTower.
- Zero-Shot Object Detection: OWL-ViT and OWLv2
Additionally, the integration supports using direct computation of embeddings, and direct utilization of Transformer models for any downstream applications that leverage embeddings, such as dimensionality reduced visualization and semantic/similarity search.
For embedding computation/utilization, all Image Classification and Object Detection models that expose the last_hidden_state attribute, and all Zero-Shot Image Classification/Object Detection models that expose image features via get_image_features()are supported.
For semantic similarity search, only Zero-Shot Classification/Detection models that expose text and image features are supported.
Inference with Transformer Models
In FiftyOne, sample collections (fiftyone.Dataset and fiftyone.DatasetView instances) have an apply_model() method, which takes a model as input. This model can be any model from the FiftyOne Model Zoo, any fiftyone.Model instance, or a Hugging Face transformers model!
Traditional Image Inference Tasks
For Image Classification, you can load a Transformers model via the Transformers library, with the specific architectural constructor, or via AutoModelForImageClassification, using from_pretrained() to specify the checkpoint. For BeiT, for instance.
## option 1
from transformers import BeitForImageClassification
model = BeitForImageClassification.from_pretrained(
"microsoft/beit-base-patch16-224"
)
## option 2
from transformers import AutoModelForImageClassification
model = AutoModelForImageClassification.from_pretrained(
"microsoft/beit-base-patch16-224"
Once the model has been loaded, you can apply the model directly to your dataset, specifying the name of the field in which to store the classification labels via the label_field argument:
dataset.apply_model(model, label_field="beit-base", batch_size=16)
session = fo.launch_app(dataset)
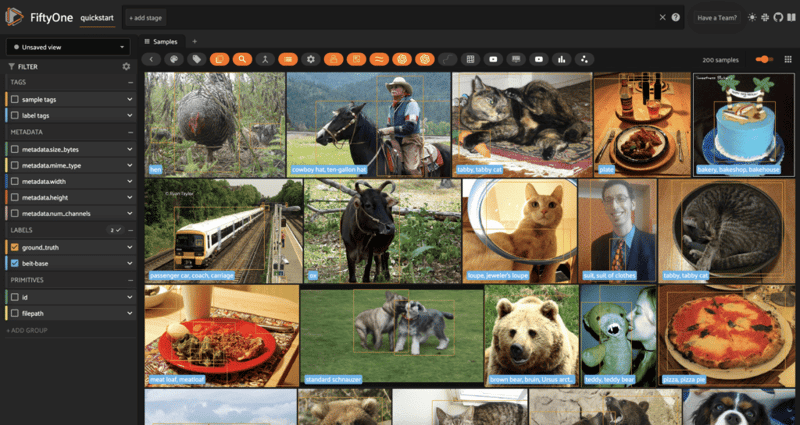
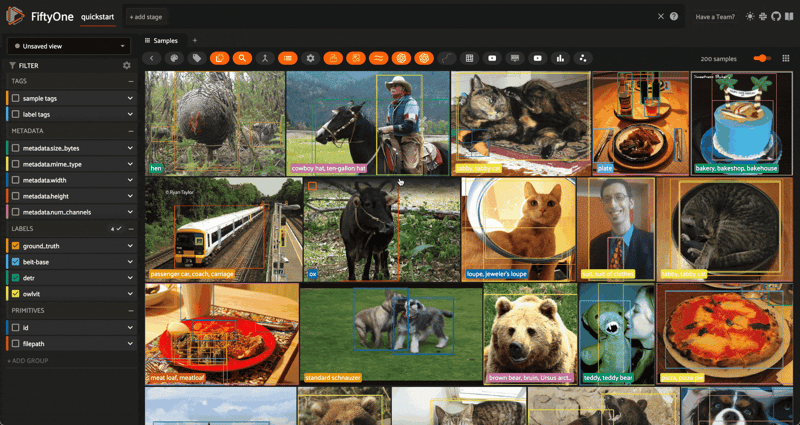
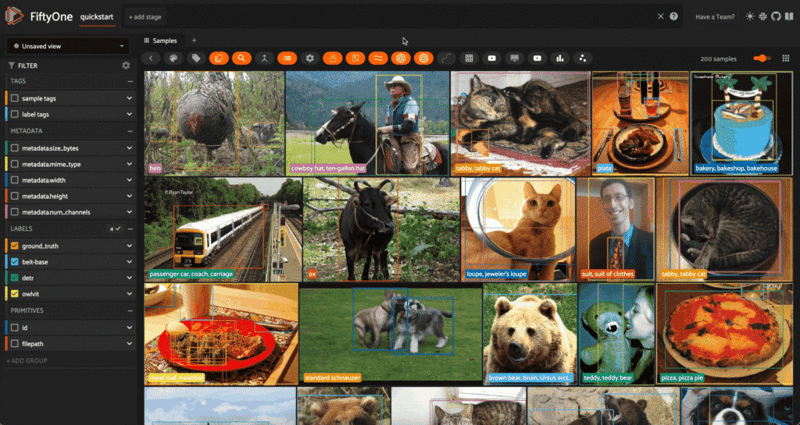
Object Detection, Semantic Segmentation, and Depth Estimation tasks work in analogous fashion; for Object Detection, instantiate a model with the AutoModelForObjectDetection or the specific architectural constructor, and apply with the same syntax:
from transformers import DetrForObjectDetection
model = DetrForObjectDetection.from_pretrained("facebook/detr-resnet-50")
dataset.apply_model(model, label_field="detr")
session = fo.launch_app(dataset)
For Semantic Segmentation, you can load and apply models that have ForInstanceSegmentation or ForUniversalSegmentation in the constructors, so long as the image processor for the model has a post_process_semantic_segmentations()method.
And for Monocular Depth Estimation, you can load and apply models that have ForDepthEstimation in their constructors. To use DPT, for instance:
from transformers import DPTForDepthEstimation
model = DPTForDepthEstimation.from_pretrained("Intel/dpt-large")
dataset.apply_model(model, label_field="dpt_large")
session = fo.launch_app(dataset)
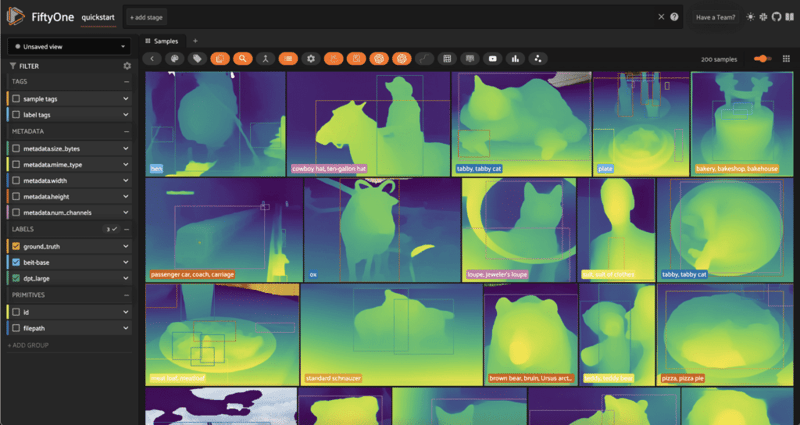
💡 Once you have generated predictions, you can filter by label class and prediction confidence in the app, and by arbitrary properties in Python. For instance, to filter for bounding boxes that take up less than 1/4 of the image:
from fiftyone import ViewField as F
bbox_filter = F("bounding_box")[2] * F("bounding_box")[3] < 0.25
small_bbox_view = dataset.filter_labels("detr", bbox_filter, only_matches=True)
session = fo.launch_app(small_bbox_view)
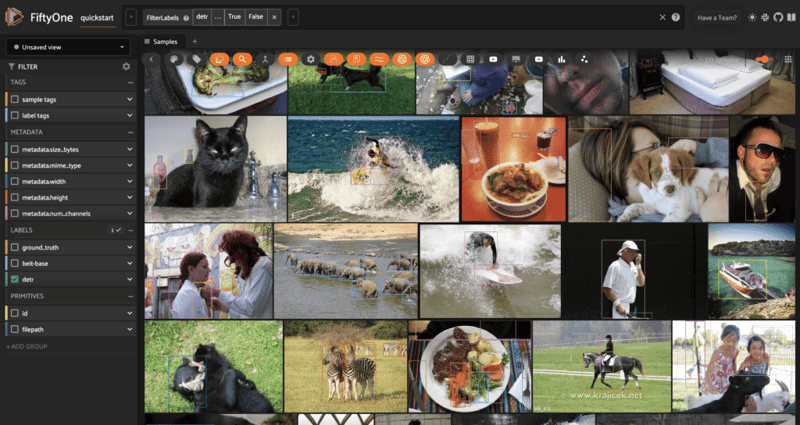
💡 You can numerically evaluate predictions for any of these tasks with FiftyOne's Evaluation API.
Zero-Shot Inference Tasks
For zero-shot tasks, it is recommended to load the Hugging Face transformers model from the FiftyOne Model Zoo. Transformer models for Zero-Shot Image Classification can be loaded with the load_zoo_model() method, specifying the model type (first argument) as "zero-shot-classification-transformer-torch", and then passing in the name_or_path=<hf-name-or-path>. You can pass the list of classes in at model initialization time, or set the model's classes later.
import fiftyone.zoo as foz
model_type = "zero-shot-classification-transformer-torch"
name_or_path = "BAAI/AltCLIP" ## <- load AltCLIP
classes = ["cat", "dog", "bird", "fish", "turtle"] ## can override at any time
model = foz.load_zoo_model(
model_type,
name_or_path=name_or_path,
classes=classes
)
You can then apply the model for image classification just as you did in the traditional image classification setting with apply_model().
Zero-Shot Object Detection works the same way, but with model type "zero-shot-detection-transformer-torch":
import fiftyone.zoo as foz
model_type = "zero-shot-detection-transformer-torch"
name_or_path = "google/owlvit-base-patch32" ## <- Owl-ViT
## load model
model = foz.load_zoo_model(model_type, name_or_path=name_or_path)
## can set classes at any time
model.classes = ["cat", "dog", "bird", "cow", "horse", "chicken"]
## apply to first 20 samples
view = dataset[:20]
view.apply_model(model, label_field="owlvit")
session = fo.launch_app(view)
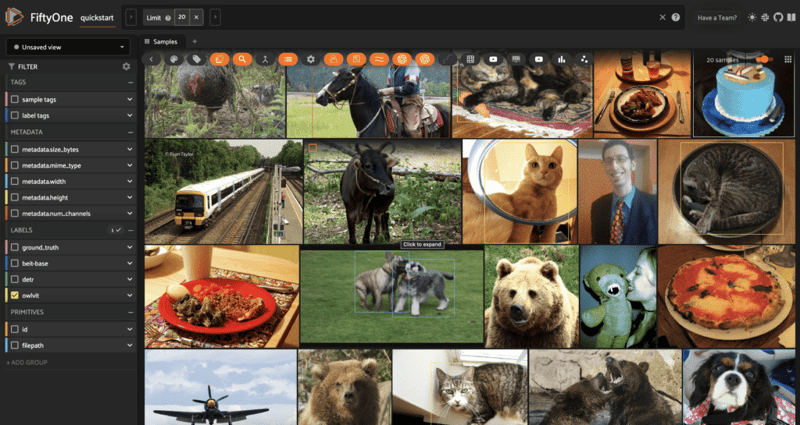
Video Inference Tasks
One of the coolest parts of this integration is that the flexibility intrinsic to FiftyOne's datasets and to Hugging Face's Transformer models is preserved. Without any additional work, you can apply any of the models from the image tasks above to (the frames in) a video dataset, and it will just work!
This is all the code it takes to apply YOLOS from the transformers library to a video dataset:
import fiftyone.zoo as foz
## load video dataset
video_dataset = foz.load_zoo_dataset("quickstart-video")
## load YOLOS model
from transformers import YolosForObjectDetection
model = YolosForObjectDetection.from_pretrained("hustvl/yolos-tiny")
## apply model
video_dataset.apply_model(model, label_field="yolovs", batch_size=16)
## visualize the results
session = fo.launch_app(video_dataset)
Embeddings with Transformers
Image and Patch Embeddings
In the same vein as how we could pass a Hugging Face transformers model directly into a FiftyOne sample collection's apply_model() method for inference, we can pass a transformers model directly into a sample collection's compute_embeddings() method. For instance, this would use a Beit model to compute embeddings for all images and store them in a field "beit_embeddings'' on the samples:
from transformers import BeitForImageClassification
model = BeitForImageClassification.from_pretrained(
"microsoft/beit-base-patch16-224"
)
dataset.compute_embeddings(model, embeddings_field="beit_embeddings", batch_size=16)
You can also use compute_patch_embeddings() to compute and store embeddings for each of the object patches in a certain label field on your dataset. For example, to compute embeddings for our ground truth object patches with CLIP:
from transformers import CLIPModel
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
dataset.compute_patch_embeddings(
model,
patches_field="ground_truth",
embeddings_field="clip_embeddings"
)
Visualizing Embeddings with Dimensionality Reduction
The way that Hugging Face Transformer models plug into FiftyOne datasets for embedding computations also makes them directly applicable for dataset-wide computations that utilize embeddings. One such application is dimensionality reduction. By embedding our images (or patches) and then reducing the embeddings down to 2D with t-SNE, UMAP, or PCA, we can visually inspect hidden structure in our data, and interact with our data in new ways.
In FiftyOne, dimensionality reduction is performed via the FiftyOne Brain's compute_visualization() method, which has built-in support for t-SNE, UMAP, and PCA.
Just pass any Hugging Face transformers model that exposes image embeddings — either via last_hidden_state or get_image_features() — into the method, along with:
- a
brain_keyspecifying where to save the results, and - the dimensionality reduction technique to use
import fiftyone.brain as fob
from transformers import AltCLIPModel
model = AltCLIPModel.from_pretrained("BAAI/AltCLIP")
fob.compute_visualization(
dataset,
model=model,
method="umap",
brain_key="altclip_umap_vis"
)
session = fo.launch_app(dataset)
Then you can visualize the dimensionally-reduced embeddings along with samples in the app.
This is a great way to compare embedding models and dimensionality reduction techniques!
Searching by Similarity
Another dataset-level application of embeddings is indexing unstructured or semi-structured data. In FiftyOne, this is accomplished via the FiftyOne Brain's compute_similarity() method — and Hugging Face transformers models directly plug into these workflows as well!
Just pass the transformers model directly into the compute_similarity() call, and you will be able to query your dataset to find similar images:
import fiftyone.brain as fob
## load model
from transformers import AutoModel
model = AutoModel.from_pretrained("google/siglip-base-patch16-224")
fob.compute_similarity(dataset, model=model, brain_key="siglip_sim")
session = fo.launch_app(dataset)
💡 You can also create a similarity index over object patches in the dataset by passing the name of the field containing the object patches in with the patches_field argument.
If you want to semantically search your images with natural language, you can leverage a multimodal Transformer model that exposes both image and text features. To enable natural language querying, pass in the model type for the model argument, along with the name_or_path for the model via model_kwargs:
import fiftyone.brain as fob
model_type = "zero-shot-classification-transformer-torch"
name_or_path = "openai/clip-vit-base-patch32" ## <- CLIP
model_kwargs = {"name_or_path": name_or_path}
fob.compute_similarity(
dataset,
model=model,
model_kwargs=model_kwargs,
brain_key="clip_sim"
)
session = fo.launch_app(dataset)
Then you can query with text in the app using the magnifying glass icon, or by passing a query text string into the dataset's sort_by_similarity() method in python:
kites_view = dataset.sort_by_similarity(
"kites flying in the sky",
k=25,
brain_key="clip_sim"
)
💡 For larger datasets, you can index the data using a purpose-built vector search engine — check out our native integrations with Pinecone, Qdrant, Milvus, LanceDB, MongoDB, and Redis!
Conclusion
Transformer models have become a mainstay for those of us working in computer vision or multimodal machine learning, and their impact only appears to be increasing. With the variety and versatility of Transformer models at an all-time high, seamlessly connecting these models with computer vision datasets is absolutely critical.
I hope this integration between FiftyOne and Hugging Face Transformers helps you reduce boilerplate, readily compare and contrast model checkpoints and architectures, and understand both your data and models better!




Top comments (0)