
To me, application architecture has one primary question to answer: Where does this functionality belong? An application I’m working on is going to have features, each feature consisting of several pieces of interacting functionality. And I want to have a clear view of where each piece of functionality should go, to make sure the components stay comprehensible. The first part of this series described an application as a group of interconnected entities. Now we will look at which entities to create and when.
There exist a number of MV* architectures, MVC, MVP, MVVM, … What these have in common is that the M (model) and V (view) have very clear and limited responsibilities and then everything else apparently goes into the * part. Display formatting of information, accessing the backend over the network, navigating through the application, you name it, the * handles it. And that’s just not enough for me.
Architecture with No Pronounceable Acronym
Over the years, I have come up with an architecture that works for me. The way that things are split into components makes sense, and I always know how to split up a feature and where each piece of needed functionality goes. I have not tried to force it to form any specific acronym, so it’s really just my architecture, with components created where they make sense.
I also like to separate the connections between components into two different kinds: A dependency means that a component has a reference to another component. And data flow means that a component passes data to another component. Sometimes data flow follows a dependency, when data is passed in to a component whose functionality is invoked. And other times data flow goes in the inverse direction, when a component observes another component’s state.
The diagram shows the useful architectural concepts that I have identified, which I call roles. The data flow between them is shown with arrows pointing in the direction of where the data flows. I have found that mostly, unidirectional data flow works well and makes things easier to understand, since it is always known from where changes can be triggered. Dependencies in the diagram go from top to bottom: something higher up can depend on anything lower down, but not vice versa.
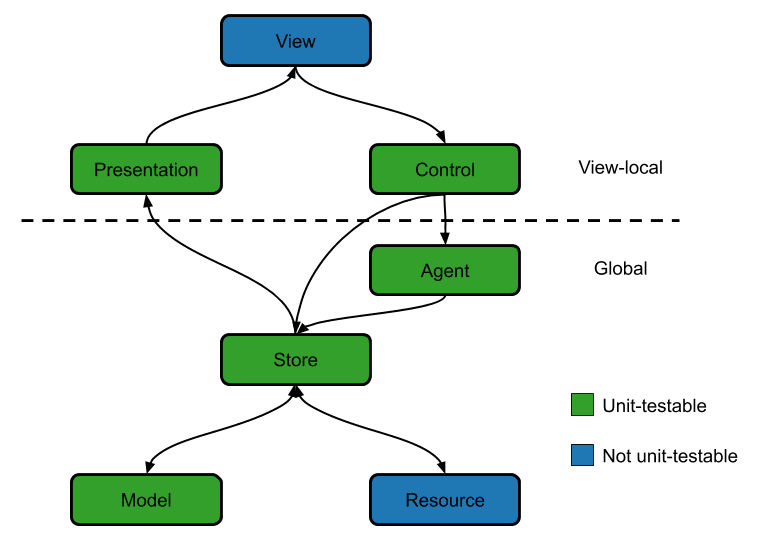
Overview of Roles
It is of course necessary to have good definitions of the roles, to serve the goal of knowing where each piece of functionality belongs. View and Resource are the roles that interact with the outside world. A View is whatever draws the user interface on the screen and recognizes user interactions. A single screen often contains multiple Views, usually arranged hierarchically in containment relationships. A Resource is anything interacting with the external world outside of the user interface, from communicating with a backend to file I/O and even to timers.
Presentation and Control are both related to the user interface. In the diagram they are marked as view-local, whereas other roles are global. This means that usually each View has its own components to perform these roles, and they are not typically shared between different Views. The reason for splitting these roles is to make the data flow clearer (and unidirectional): Presentation is only concerned with how data is displayed on screen, so the data flow is unidirectional from Store through Presentation to View. And in the other direction, Control only receives user interaction triggers from the View and triggers actions in Store or Agent.
The division between Model and Store comes from how state is represented according to the previous post in this series. Models are values, and Stores are entities whose state consists of Model objects. All base state in the application is state of a Store. The Store can acquire this state either from data that flows into it from above, or by fetching it from a Resource, such as a backend or database. The data that flows out of a Store are the Model objects that comprise its state.
The Agent role is perhaps the most unusual and also the rarest. The idea behind Agent is that other roles are purely reactive; they do something only in response to data flowing into them, whereas an Agent is allowed to be active, to initiate an action (in a way, the View can also be seen as active, since user actions are definitely not initiated as a direct response to data flow, but user activity is not modelled here). For instance, a periodic synchronization of data with a backend would be an Agent activity, and separating the periodic triggering of the action by the Agent from the actual communication performed by the Store makes the whole system easier to comprehend.
Roles instead of Components
The key point in the diagram is that these are not architectural components, they are roles. The difference being, a component may assume multiple roles. When a Model object is shown in the user interface by simply displaying some of its properties as they are, I don’t bother to create a completely new Model Presentation component but simply let the View directly use the Model object that it acquires from a Store. But when the needed presentation becomes more complex, as it often does, the established separation of roles brings easily to mind the solution of creating a new component for the Presentation role.
I place great importance on being able to unit-test as much of an application as possible, and that in part has guided the architecture. The two roles marked as not unit-testable in the diagram are always separate components to facilitate this. For Resources, a test double is always used. Sometimes the double is a stub when the Resource interaction in the test is simple, sometimes a fake to allow more precise control over its behavior. Views are not considered in unit tests at all. All the logic determining what to show is in a Presentation, and all action code is in a Control, so there is no unit-testable logic in a View, only the actual displaying on screen and mapping user interactions to Control triggers.
Other Architectures
The architecture described here owes a lot to my experiences building mobile applications, and especially to using the popular architectures and trying to fill their “deficiencies”. For instance, the view-local part of the architecture comes quite directly from MVVM, where the View Model fulfils the roles of Presentation and Control. Experience with MVVM has taught me that these two roles are typically very distinct in a View Model, and for me separating them as concepts makes the whole architecture clearer.
Traditionally, the whole functionality contained in the Model, Store, and Resource roles would be contained in the Model part in an MV* architecture. The previous post on values and entities establishes why I like the Model-Store separation, and it is also partly inspired by the Model-View-Controller-Store architecture. The separation of Store and Resource is purely to help with unit testing. By separating the part that in a real application requires interaction with the external world into a thin stubbable layer allows unit tests to cover a lot more of the application than if all the Resource use was contained inside the Store.
Navigation is one of the most difficult architectural problems in mobile application development. It is always very simple at the beginning, and can be handled by the Views using the platform native navigation patterns. But too often the navigation patterns of an application become more complex, and they typically do this a bit at a time, never allowing the moment where it’s clear that the navigation needs to be rethought. The VIPER architecture is the only one I know that explicitly includes navigation, but even there it appears to be only a way to separate the too-simple platform-provided navigation into its own components. The kinds of complex navigation that I have encountered require a more global approach, usually requiring a single component that is responsible for the navigation needs of the whole application.
Scenarios
I began with the purpose of the architecture being to determine where each piece of functionality belongs. Thus, the validation of an architecture is performed by observing how well this purpose is fulfilled in development situations. The following two examples show how the functionality in an application screen would be split, and how the role-based thinking allows the implemented architecture to remain simple when applicable and to evolve into something more complex when needed.
The component architecture of a very basic screen could look like the User Info Screen example shown below. This is a component diagram, with the roles that each component fulfils shown on the top-right corner of the component. The User Store holds the User model object. The screen shows directly the information in this model object without any additional presentation logic, so the User object can act also in the Presentation role.

The screen allows editing the user information. In this case no special interaction logic is needed, so the User Store can act in the Control role for the View. Finally, the User Store is responsible for local and remote persistence of the user information, and it uses two Resources for this, one for the local database and one to communicate with the backend.
A more complex screen, with more components and more separated roles, is provided by a chat application. The Chat Store is in a way the center point of the application, as it stores all the chats that the user participates in. The Model objects are the messages in the chat, but in this case, a separate Presentation component for messages is needed; for instance, the Model object is likely to store the precise timestamp of the message but the screen should display a more human-friendly representation.

Depending on how message sending is implemented, there might be a Message Sender component in the Control role that both requests the Chat Store to send a new message from the user and immediately calls the Presentation to update the screen for a better user experience. An alternative would be for the representation of a chat provided by the Chat Store to also provide sufficient information for any pending messages. In general, a separate Control component is useful when a user action requires data to flow into several different components, but it could also be used when the Control functionality is complex enough to warrant testing but is not considered to be the responsibility of a Store.
The chat application also provides an example of the Agent role. The Chat Updater is an independent component that could be triggered by a timer, or by external notifications, either one of which would be a Resource. When triggered, the Chat Updater will tell the Chat Store to update a specific chat or all the chats using the Resource for communicating with the chat backend.
Summary
To summarize the above: I split an application architecture in as many concepts as I feel are necessary. I don’t feel the need to force them into a cutesy acronym. I use components only when they actually have some necessary function instead of being just a pass-through layer for data, and that’s why I think in terms of roles instead of components. I find thinking in terms of data flow very useful, so data flow between components is an important part of the architecture. And finally, I’m not afraid to go against my principles when needed. Not everything fits into neat little boxes, and sometimes it’s better to just acknowledge that than to try to squeeze a square peg into a round hole. In the end, software architecture should provide guidance, not act as a straitjacket.




Top comments (0)