
In Part 1 of this article, I built and compared two classifiers to detect trolls on Twitter. You can check it out.
Now, time has come to look more deeply into the datasets to find some patterns using exploratory data analysis and topic modelling.
EDA
To do just that, I first created a word cloud of the most common words, which you can see below.

So, “butthis” and “bestUSAtoday” are the most frequently used words, which seemingly makes no sense. However, butthis.com is actually one of the most famous websites within the Twitter account bestUSAtoday considered to be related to the IRA agency. The account itself was suspended by Twitter for violation of the Twitter Rules. Moreover, the butthis.com domain no longer exists as well, so I could only look at the screenshots of the site and, from what I saw, all its content was political. This word was mentioned 350 times in 2288 tweets, which makes this external resource popular among trolls.
Other most common words were ”isis” (ISIS, i.e. Islamic State of Iraq and the Levant), ”police”, ”potus” (President of the United States), ”news” and words related to the main competitors of the 2016 US Presidential Elections Hillary Clinton and Donald Trump.
Topic modelling
The next step, topic modelling, showed me the most common topics in the tweets under study. For this purpose, I used LDA, which requires a bag-of-words representation of the tweets as its input.
As part of this research, I compared Gensim LDA with Scikit Learn LDA, and it turned out that Scikit Learn does not provide a convenient coherence calculation model, which could allow me to quickly obtain the coherence measure given a certain number of topics. That’s why I chose Gensim LDA as the model with a broader range of the required features.
Speaking of the coherence measure, it shows the level of correlation between words in a topic. The higher the coherence is the more sense in a topic we will observe. In my experiments, I was looking for the so-called coherence k-value, which represents the peak of the rapid growth of coherence, and found out that the optimal number of the topics would be 7.
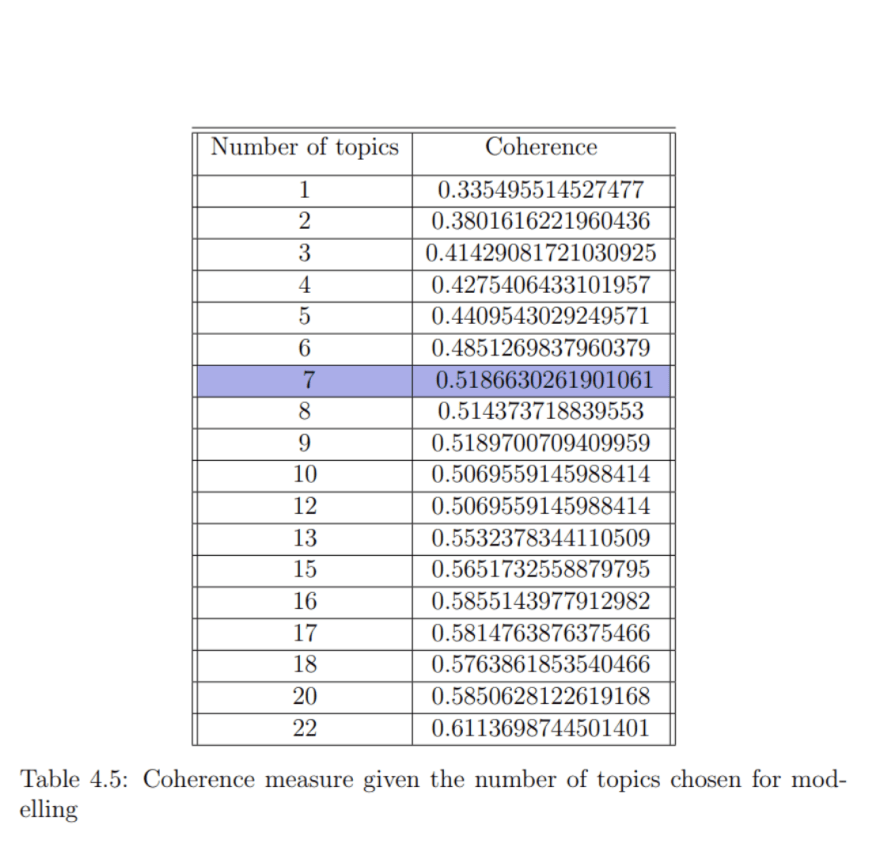
*As for the results of the topic modelling: *

Topic: 0 is about the above-mentioned troll resources ”bestUSAtoday”, butthis.com and other online resources, such as Newsmax.com or TheHuffingtonPost.com, which are private online news and opinion websites in the US. Topic: 5 concerns Donald Trump with words like ”Iran”, ”deal”, ”irandeal”,”potus”, ”irannucleardeal” or ”trump2016”. This topic covers the year of the nuclear deal between Iran and a group of six countries led by POTUS Donald Trump. Another interesting Topic: 4 is dedicated to refugees and migration and includes such words as “attacks”, “could” or “kill”. In addition, there is Topic: 2, which is about the immigration caused by the Syrian war in the Middle East and about how candidates for the position of the President were going to deal with it. Topic: 6 is fully dedicated to the 2016 elections and the sources of propaganda.
Conclusions and further work
So, two classifiers with very high overall accuracy, precision, recall and F-1 score have been built and tested on several features. The experimental results have shown that the tweet text as a feature gives better accuracy than hashtags. The models were trained on large amounts of data and, thus, can be used as a correct solution for detecting attempts at mass influencing. The exploratory analysis and topic modelling allowed me to delve deeper into the actual goals of the trolling. All this makes it possible to conclude that the ability to affect internal affairs of another state exists but, probably, depends on the amount of the troll army used and how they are used.
This study in two parts is initial and can be furthered with deep learning and analysis of visual components (such as images and videos attached to the tweets). To continue with the research, I’m going to build a classifier that will take into account such aspects as the user name, the user picture, kind of account activities (number of retweets and likes), number of tweets per unit of time and some deeper parameters like the type of followers or the sentiment of the tweets.
The only concern related to more advanced analysis and deep learning is that troll accounts will soon be automated and converted into bot accounts. This means that we will soon need to extract features of bots instead of trolls. This might be quite a complicated thing because bots usually have many similar features, but not all of them represent trolls.

Top comments (0)