
Web scraping is the process of automatically extracting data and collecting information from the web.
It could be described as a way of replacing the time-consuming, often tedious exercise of manually copy-pasting website information into a document with a method that is quick, scalable and automated. Web scraping enables you to collect larger amounts of data from one or various websites faster.
It’s possible to do web scraping with many programming languages.
However, one of the most popular approaches is to use Python and the Beautiful Soup library
How does it work?
When we scrape the web, we write code that sends a request to the server that’s hosting the page we specified. The server will return the source code — HTML, mostly — for the page (or pages) we requested.
So far, we're essentially doing the same thing a web browser does — sending a server request with a specific URL and asking the server to return the code for that page.
But unlike a web browser, our web scraping code won't interpret the page's source code and display the page visually. Instead, we'll write some custom code that filters through the page's source code looking for specific elements we’ve specified, and extracting whatever content we’ve instructed it to extract.
Is it Legal?
Unfortunately, there’s not a cut-and-dry answer here. Many websites don’t offer any clear guidance one way or the other. Some websites explicitly allow web scraping. Others explicitly forbid it.
Before scraping any website, we should look for a terms and conditions page to see if there are explicit rules about scraping.
We can also check the robots.txt file for any website to see which pages are permitted to be scraped and which pages disallow scraping. Ex: https://www.facebook.com/robots.txt. Here, Facebook clearly specifies which pages are allowed to be accessed and which pages are not.
Libraries
requests
The first thing we’ll need to do to scrape a web page is to download the page. We can download pages using the Python requests library.
The requests library will make a GET request to a web server, which will download the HTML contents of a given web page for us.
BeautifulSoup
We can use the BeautifulSoup library to parse the web page, and extract the text.
We first have to import the library, and create an instance of the BeautifulSoup class to parse the web page.
Then, We can print out the HTML content of the page using various BeautifulSoup methods.
Example
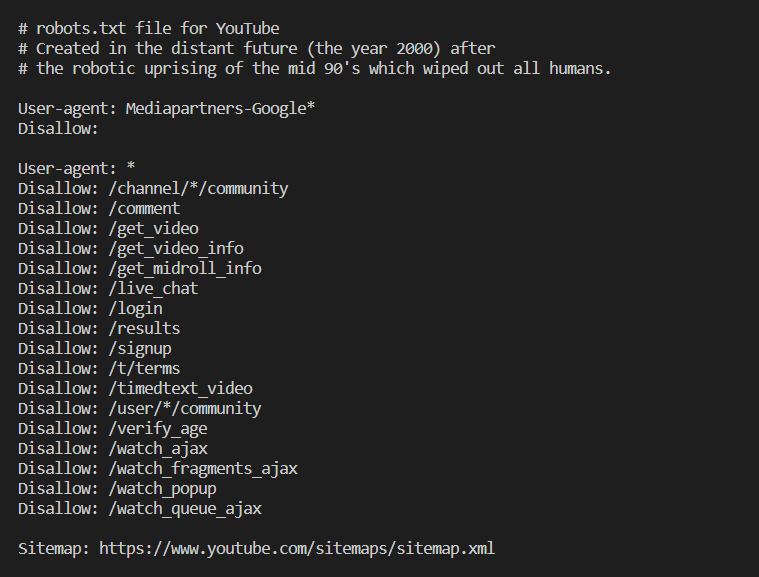
Let's scrape the content from YouTube's robot.txt file.
First, we have to import requests library and send a GET request to download data from the desired location.
import requests
request = requests.get('https://www.youtube.com/robots.txt')
Now, we have to import BeautifulSoup to parse the web page and print all the data that we have access to.
from bs4 import BeautifulSoup
data = BeautifulSoup(request.text, 'html.parser')
print(data.get_text())
Now, we can read the output and find out which pages YouTube allows to be scraped and which it does not
Output:





Top comments (0)