
1. Practice for Queries
1.1. Use lean queries for GET operations
Mongoose documents are much heavier than vanilla Javascript objects.
const user = await User.findById(userId);
Change tracking
Casting and validation
Getters and setters
Virtuals (including "id")
save() function
If you execute query and send result without modification, you should use lean().
const user = await User.findById(userId).lean();
1.2. Use .select() to filter specific properties
You don't need the entire document which your query returns.
const user = await User.findById(userId).select({ name: 1, email: 1 });
This also helps sensitive fields being returned to frontend side.
You can also define selections in the schema definitions.
const userSchema = new mongoose.schema({
firstName: {
type: String,
},
email: {
type: String,
select: true,
},
verficationToken: {
type: String,
select: false,
},
password: {
type: String,
select: false,
},
});
// Select explicitly
const { userId } = req.body;
const user = await
User.findById(userId).select('+email');
1.3. Minimise DB Queries (Avoid .populate)
Avoid this
const customers = await Customer.find()
.populate({
path: 'contract',
populate: {
path: 'customer',
model: Customer
}
});
const result = customers.filter(customer => customer.contract.number === contractId);
const customers = await Customer.find()
.populate({
path: 'contract',
select: 'number',
populate: {
path: 'customer',
model: Customer,
select: 'firstName lastName'
}
});
Need to select only essential fields as many as possible
Better to use .aggrecate() pipeline
1.4. Hooks and validators
Mongoose validators
const userSchema = new Schema({
provisionAcqFeePercent: {
type: Number,
default: null,
min: [10, 'Percentage too small'],
max: 100
},
});
Mongoose hooks (prehook, posthook etc)
userSchema.pre('save', function capitalizeNames(next) {
this.firstName = capitalize(this.firstName);
this.lastName = capitalize(this.lastName);
next();
});
These functions wouldn't trigger validators and
hooks
User.create();
User.findOneAndUpdate();
User.findByIdAndUpdate();
User.remove();
User.findOneAndRemove();
User.findByIdAndRemove();
1.5. Proper use of virtuals
Person and Blog has 1:M relationship (one to many)
const blogSchema = ({
title: String,
tags: [{
type: String
}],
author: {
type: Schema.Types.ObjectId,
ref: 'Person'
}
});
const personSchema = ({
name: String,
blogs: [{
type: Schema.Types.ObjectId,
ref: 'Blog'
}]
});
It's easy to fetch author of each blog, but...
If you want to find out all blogs written by a person?
const personSchema = ({
name: String
});
personSchema.virtual('blogs', {
ref: 'Blog',
localField: '_id',
foreignField: 'author'
});
const blogs = await Person.findById(personId).populate('blogs');
1.6. Create custom indexes
Custom index
eventSchema.index({ 'type': 1 });
eventSchema.index({ 'data.object._id': 1 });
eventSchema.index({ 'data.object.parent': 1 });
eventSchema.index({ 'data.object.customer': 1 });
eventSchema.index({ 'data.object.contract': 1 });
eventSchema.index({ 'data.object.partner': 1 });
eventSchema.index({ 'data.object.to._id': 1 });
Compound index
event Schema.index({ type: 1, status: 1 });
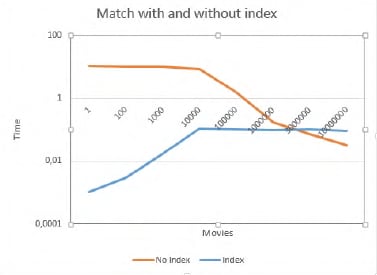
1.7. Field selection for PATCH & PUT
PUT request assumes all fields are submitted from frontend
user.findById(req.params.id, (err, user) => {
user.name = req.body.name;
user.age = req.body.age;
user.country = req.body.country;
user.save((saveErr, updatedUser) => {
res.send({ data: updatedUser });
});
});
POST request would pass only fields that wants to update
user.findById(req.params.id, (err, user) => {
// Update user with the available fields
// This assumes the field name is the same in the form and the database.
user.set(req.body);
user.save((saveErr, updatedUser) => {
res.send({ data: updatedUser });
});
);
2. Practices in MongoDB schema design
2.1. Embedding vs Referencing
Embeding
{
"first_name": "Paul",
"surname": "Miller",
"cell": "447557505611",
"city": "London",
"location": [45.123, 47.232],
"profession": ["banking", "finance", "trader"],
"cars": [
{
"model": "Bentley",
"year": 1973
},
{
"model": "Rolls Royce",
"year": 1965
}
]
}
Referencing
{
"first_name": "Paul",
"surname": "Miller",
"cell": "447557505611",
"city": "London",
"location": [45.123, 47.232],
"profession": ["banking", "finance", "trader"],
"cars": [
{
type: Schema.Types.ObjectId,
ref: 'Car'
}
],
}
2.2. Modeling One-to-few, One-to-Many
Modeling One-to-few
Favor embedding unless there is a compelling reason not to.
const blogSchema = ({
title: "String,"
tags: [{
type: String
}],
author: {
type: Schema.Types.ObjectId,
ref: 'Person'
}
});
One-to-Many
if you need to access an object itself, you need to use reference
{
"name": "left-handed smoke shifter",
"manufacturer": "Acme Corp",
"catalog_number": "1234",
"parts": ["ObjectID('AAAA')", "ObjectID('BBBB')",
"ObjectID('CCCC')"]
}
Parts
{
"_id" : "ObjectID('AAAA')",
"partno" : "123-aff-456",
"name" : "#4 grommet",
"qty": "94",
"cost": "0.94",
"price":" 3.99"
}
Use a reference array in ONE side in the one-to-many relationship.
2.3. One-to-squilion vs Many-to-Many
One-to-squilion
if there are too many references, don't use an array of ObjectIDs
Hosts
{
"_id": ObjectID("AAAB"),
"name": "goofy.example.com",
"ipaddr": "127.66.66.66"
}
Logs
{
"time": ISODate("2014-03-28T09:42:41.382Z"),
"message": "cpu is on fire!",
"host": ObjectID("AAAB")
}
Use a reference in MANY side in the one-to-squilion relationship.
Many-to-Many
Use bidirectional reference in many-to-many relation
Users
{
"_id": ObjectID("AAF1"),
"name": "Kate Monster",
"tasks": [ObjectID("ADF9"), ObjectID("AE02"),
ObjectID("AE73")]
}
Tasks
{
"_id": ObjectID("ADF9"),
"description": "Write blog post about MongoDB schema",
"due_date": ISODate("2014-04-01"),
"owners": [ObjectID("AAF1"), ObjectID("BB3G")]
}
3. MongoDB vs MySQL
3.1. Differences
MYSQL
| datastructure | It stores each individual record as a table cell with rows and columns |
| schema | MySQL requires a schema de nition for the tables in the database |
| languages | Supports Structured Query Language (SQL) |
| foreign key | Supports the usage of Foreign keys |
| replication | Supports master-slave replication and master-master replication |
| join operation | SQL Database can be scaled vertically |
| performance | Supports Join operation |
| risks | Optimized for high performance joins across multiple tables |
MONGODB
| datastructure | It stores unrelated data in JSON like documents |
| schema | MongoDB doesn’t require any prior schema |
| languages | Supports JSON Query Language to work with data |
| foreign key | Doesn’t support the usage of Foreign keys |
| replication | Supports sharding and replication |
| join operation | MongoDB database can be scaled both vertically and horizontally |
| performance | Doesn’t support Join operation |
| risks | Optimized for write performance |
3.2. Select, Update and Insert performance
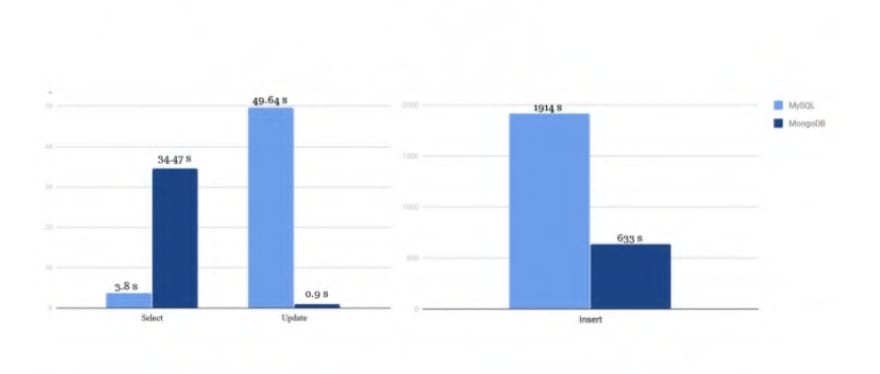
3.3. Is MongoDB faster than MySQL?
Since MongoDB's document model stores related data together, it is often faster to retrieve a single document from MongoDB than to JOIN data across multiple tables in MySQL.
3.4. Summary
Applications, like an accounting system that requires multi-row transactions, would be better suited for a structured and relational database. MySQL is an excellent choice if you have structured data and need a traditional relational database.
MongoDB is well-suited for real-time analytics, content management, the Internet of Things, mobile, and other types of applications. It is an ideal choice if you have unstructured and/or structured data with rapid growth potential.
Thanks for reading!





Top comments (0)