TimescaleDB 2.18 introduces transition table support for hypertables, a long-requested and upvoted feature (issue from 2019!) that enhances trigger functionality by allowing bulk access to affected rows during INSERT, UPDATE, or DELETE operations.
This sidesteps the inefficiencies of row-by-row trigger processing, making operations that aggregate metadata about devices or batches significantly more efficient: we’ve seen a 7x performance improvement for statement-level triggers with transition tables.
Like the support for PostgreSQL indexes in our columnstore, this feature brings TimescaleDB closer to standard PostgreSQL behavior, making integration into existing workflows smoother. More importantly, it unlocks new, previously impractical bulk processing capabilities due to performance constraints.
How Transition Tables Work in PostgreSQL
Transition tables were introduced in PostgreSQL 10 to give AFTER triggers access to all affected rows in a single operation. Normally, when a trigger fires, it operates on each row one at a time—meaning that if a statement inserts, updates, or deletes multiple rows, the trigger function must run once per row, which is very inefficient.
With transition tables, PostgreSQL allows trigger functions to see all modified rows at once in a temporary table-like structure. This means a trigger can process changes in bulk rather than row-by-row. As you can guess, it’s a lot faster!
These transition tables are available in AFTER INSERT, AFTER UPDATE, and AFTER DELETE triggers. They are referenced using the REFERENCING NEW TABLE AS or REFERENCING OLD TABLE AS clauses, which let the trigger function treat the affected rows like a normal table inside the function.
Until TimescaleDB 2.18, hypertables lacked support for this feature, which meant that bulk processing of changes had to be handled outside of trigger logic or row by row with a statement-level trigger.
Why Transition Tables Took Us So Long
I’m a developer advocate, not a developer, but I came up against the need for transition tables often enough that I brushed up my C skills and attacked the issue. At first, I assumed there was a deep technical reason why TimescaleDB didn't support transition tables. But as I dug into the code and started working on the initial pull request, it became clear that it wasn’t a technical limitation—it was probably just left out of the original implementation to reduce scope.
Hypertables add complexity compared to regular PostgreSQL tables because of chunking and our time-series planner optimizations. Handling transition tables across all these cases took a lot of testing, but fundamentally, it wasn’t impossible—it just hadn’t been prioritized yet.
I opened the initial PR, but, like many open-source contributions, it took some extra polish to get it production-ready. Mats later picked it up and refined the implementation, making sure it was solid and well-integrated into TimescaleDB. Huge shoutout to Mats for seeing it through to completion!
Use Cases for Transition Tables
Now that we have transition tables, they unlock a bunch of cool use cases for hypertables. Here are a few examples:
- Tracking first and last appearances of an entity : Keep a metadata table that records when an entity (e.g., a generator or sensor) first and last appears in the dataset. You could even track the total number of records associated with it and any other metadata your application needs (even the full last state). This can then be used for ultra-fast lookups.
- Batch validation and anomaly detection : Flag bad data—like missing values or extreme readings—for further analysis.
- Batch tracking: Track the size, timing, and metadata (minimum and maximum timestamps) for each batch insert.
Tracking device metadata
One of the best use cases for transition tables is tracking per-ID metadata, like when a device or sensor first and last appears in the dataset. While this data is available in the main table, maintaining a separate metadata table can speed up finding records in the hypertable, especially when you have many hypertable chunks and all devices aren’t constantly reporting.
The following SQL can be used to set this up.
Table schema
CREATE TABLE power_generation (
generator_id INTEGER,
timestamp TIMESTAMPTZ NOT NULL,
power_output_kw DOUBLE PRECISION,
voltage DOUBLE PRECISION,
current DOUBLE PRECISION,
frequency DOUBLE PRECISION,
temperature DOUBLE PRECISION
);
SELECT create_hypertable(
'power_generation',
'timestamp',
chunk_time_interval=> INTERVAL '1 hour',
create_default_indexes=>false
);
CREATE INDEX power_generation_generator_id_timestamp_idx
ON power_generation (generator_id, timestamp DESC);
Metadata table
CREATE TABLE generator_metadata (
generator_id INTEGER PRIMARY KEY,
first_seen TIMESTAMPTZ,
last_seen TIMESTAMPTZ
);
Trigger function
CREATE OR REPLACE FUNCTION update_generator_metadata()
RETURNS TRIGGER AS $$
BEGIN
INSERT INTO generator_metadata (generator_id, first_seen, last_seen)
SELECT generator_id, min(timestamp), max(timestamp)
FROM new_table n
GROUP BY generator_id
ON CONFLICT (generator_id) DO UPDATE
SET last_seen = GREATEST(generator_metadata.last_seen, EXCLUDED.last_seen),
first_seen = LEAST(generator_metadata.first_seen, EXCLUDED.first_seen);
RETURN NULL;
END;
$$ LANGUAGE plpgsql;
Trigger statement
CREATE TRIGGER generator_metadata_trigger
AFTER INSERT ON power_generation
REFERENCING NEW TABLE AS new_table
FOR EACH STATEMENT
EXECUTE FUNCTION update_generator_metadata();
This implementation ensures the metadata table automatically keeps accurate first_seen and last_seen timestamps for each generator_id.
It can be used to speed up real-time analytics, querying directly for the last record with this SQL:
SELECT *
FROM power_generation
WHERE generator_id = 1
AND timestamp = (SELECT last_record
FROM power_generation_metadata
WHERE generator_id = 1);
Performance Considerations
Adding a trigger to track generator metadata is useful, but what about performance? Running row-by-row updates in a trigger is notoriously slow, so let’s compare a row-level trigger, a statement-level trigger (using transition tables), and an import without any trigger.
I used the pgingester command, running it with the following settings:
pgingester -b 10000 binary-copy
--threads 1
-f ~/power_generation_10m.csv
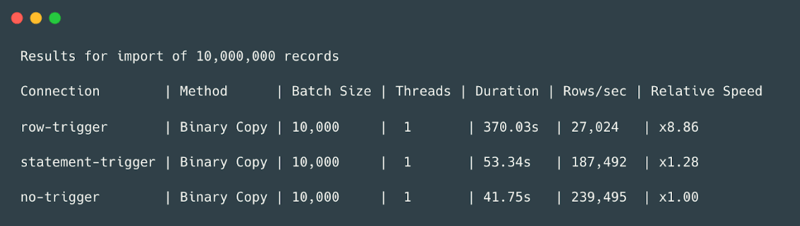
For an import of 10 million records using just a single thread, the results were clear:
- A row-level trigger processing each record individually took 370 seconds, achieving only 27,000 rows/sec. This was almost 9x slower than the baseline import.
- A statement-level trigger (using transition tables) processed the same data in 53 seconds, handling 187,000 rows/sec—a 1.28x slowdown compared to no trigger but still an order of magnitude faster than row-by-row processing.
- A baseline import with no trigger completed in 42 seconds at 239,000 rows/sec.
The takeaway? Row-by-row triggers are effectively unusable at scale, while transition tables offer a reasonable trade-off between functionality and performance.
Conclusion
Transition tables in TimescaleDB 2.18 are a huge step forward for efficient bulk processing in hypertables. They make maintaining ID and device metadata tables much more practical while keeping TimescaleDB more in sync with standard PostgreSQL behavior.
Yes, there’s some overhead compared to not using triggers at all, but statement-level triggers with transition tables are 7x faster than row-by-row processing. If you’ve been avoiding triggers because of performance concerns, this feature makes them viable again.
I’m excited to see how people use this feature—whether for real-time monitoring, metadata tracking, or something completely unexpected. Got a cool use case? Let us know!
If you want to try this performance boost for yourself and supercharge your real-time analytics workloads, the easiest way to get started is to create a free Timescale Cloud account. You can also install TimescaleDB on your machine.

Top comments (0)