
Après s’être intéressé à la haute disponibilité de notre infrastructure, au menu aujourd'hui : la configuration de la montée en charge automatique sur nos pods et nos nodes.
Rappel sur le scaling
Il y a deux possibilités de scale.

Scaling Vertical
Si un traitement dans un pod necessite plus de ressources mémoire ou vCPU que ce que vous avez prévu mais que ce traitement ne peux être réparti sur plusieurs instances, vous devrez allouer plus de ressources à votre pod. On parle alors de scaling vertical.
Scaling horizontal
Cette méthode permet de multiplier le nombre d'instance d'une application si l'instance est trop sollicitée afin de repartir la charges.
Aujourd'hui nous allons nous concentrer sur le scaling horizontal et la façon de l'automatiser.
L’autoscaling sur les pods
Le scaling consiste à augmenter ou diminuer le nombre d’instances d’une application. Cela permet par exemple de résister à un pic de charge si votre service est fortement sollicité par moments et très peu le reste du temps. On peut configurer grâce à Kubernetes l’upscale et le downscale pour s’adapter en temps réel aux besoins de nos utilisateurs.
Montée en charge manuelle
Avant de rentrer dans le vif du sujet, petite précision sur le scaling : la commande kubectl scale vous permet de modifier instantanément le nombre d’instances dont vous souhaitez disposer pour exécuter votre application.
kubectl scale --replicas=5 deployment/myApp
Montée en charge automatique
Préparation du cluster
Je provisionne un AKS avec le monitoring activé, comme expliqué ici et je vais utiliser un container registry pour déployer mon app comme expliqué dans ce tuto.
Déploiement de mon application
Voici le yaml que j’ai écrit pour mon application :
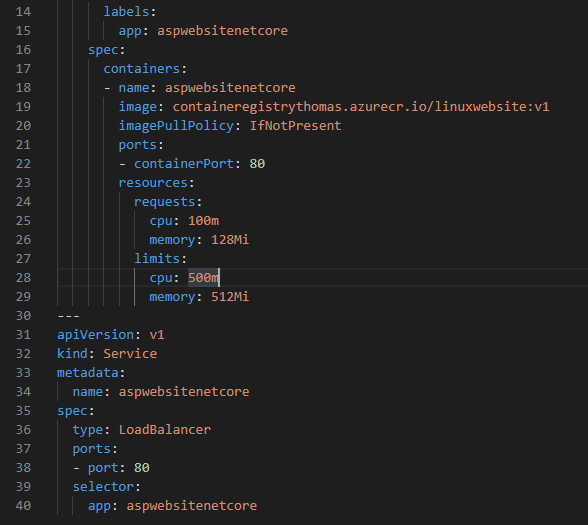
L’élément qui va nous intéresser aujourd’hui est “ressources” avec la définition des propriétés requests et limits.
Requests, c’est ce que le pod est garanti d’avoir à sa disposition pour fonctionner. Ici mon container aura donc 100m de CPU et 15Mi de RAM.
Limits en revanche c’est une sécurité sur la consommation de ressources du container. Il ne pourra pas utiliser plus de 500m de CPU et 512Mi de RAM.
Si le pod consomme trop de ressources :
- CPU : un mécanisme de throttling permet de limiter la charge CPU
- RAM : le pod est détruit
Les valeurs de CPU sont définies en milli-cores. Si vous avez besoin de deux VCPU il faudra indiquer 2000m. La notation “2” sera équivalente.
Déployons mon application avec un :
Kubectl apply –f .\deploytoaks.yaml
Ajoutons de l’HPA
La commande kubectl autoscale crée un objet HorizontalPodAutoscaler (HPA) qui cible une ressource spécifiée et la fait évoluer si nécessaire. Le HPA ajuste périodiquement le nombre d’instances dupliquées en fonction de la consommation CPU ou RAM.
En cas de modification de la charge, cet objet augmente ou réduit le nombre d’instances de l’application.
Ici, je vais demander un HPA sur mon application aspwebsitenetcore. Je lui indique de scaler entre 2 et 10 réplicas. L’upscale se fera si le pourcentage CPU consommé dépasse les 10% de ce qui est alloué, ici c’est donc 10% de consommé sur les 500millicores de CPU.
kubectl autoscale deployment aspwebsitenetcore --max 10 --min 2 --cpu-percent 10

Précision : La commande kubectl get hpa me permet d’afficher mes différents scaling mis en place sur mon cluster k8s.
Je constate qu’après la mise en place de mon HPA, j’ai désormais deux pods d’opérationnel ! Les appels vers mon site web seront automatiquement répartis vers ces deux pods via le loadbalancer de Kubernetes.

Si je rééxecute un get hpa, je visualise dans la colonne targets ou se situent mes conteneurs par rapport à la limite qu’on leur a fixée :

Stress Test
Maintenant, je vais stresser un peu mon application et simuler un fort trafic sur mon site. En toute logique, l’autoscaling configuré pour mon cluster AKS doit intervenir et mon nombre de pods devraient se dupliquer. Pour ce faire je vais utiliser Vegeta !

L'installation et l'utilisation de l'outil est super simple.
Pour le télécharger, rendez vous ici
La commande me permet de lancer une "attaque" pendant 5 minutes à raison de 5 appels seconde.
echo GET http://40.121.84.148 | vegeta.exe attack -duration=5m -rate=5 -output=stress-results.bin
J'ai spécifié un output qui me permettra ensuite de générer un rapport comme ceci afin de constater la latence induite par mon test de charge.
vegeta.exe plot -title=Results stress-results.bin > stress-results-plot.html


Assez rapidement, des événements m’informent du scale up :

J’ai maintenant 5 pods d’actif :

Puis 6 :

Quand je stoppe le load, je vais constater l’inverse et voir progressivement mon nombre de pods diminuer :

Jusqu’à revenir à ma situation initiale :


Pour déterminer à quel moment scale up ou down, Kubernetes utilise un algorithme présenté ici.
Un autoscale déployé via un YAML
Et oui, il est possible de configurer un scaling via une description yaml comme celle-ci :

Je précise toujours sur quel déploiement je veux positionner mon scaling, un nombre de pod min et max et une condition ici représentée par “targetAverageValue” sur la consommation mémoire de mes conteneurs. Ici la montée en charge sera toujours entre 2 et 10 pods et le scale se fera si on dépasse les 32Mi de mémoire.
KEDA
Il est possible de configurer un autoscaling sur des métriques autres que la charge CPU et RAM. Pour se faire je vous invite à vous intéresser à KEDA.
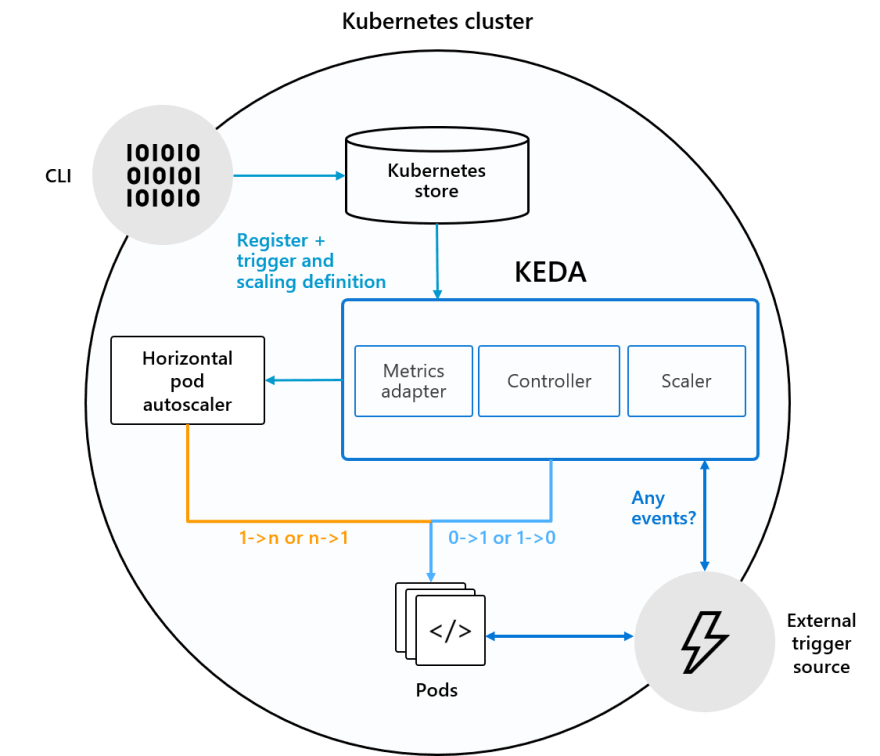
Cet outil permet par exemple de configurer un autoscale sur :
- Le nombre de message dans une queue Azure Service Bus ou RabbitMQ
- Le nombre de fichiers dans Azure Storage
- Des métriques customs exposées via Prometheus
- et bien d'autres sources !
La liste complète ici !
Après la gestion du scaling des pods, voyons comment configurer une montée en charge sur les nodes.
Autoscaling de nodes
AKS nous offre la possibilité d’allouer et de désallouer automatiquement des nodes Kubernetes pour l’hébergement de nos applications : c’est grâce à l’autoscaler de cluster.

Création du cluster
Demandons un cluster de test :
az group create --name rg-aks --location eastus
az aks create --resource-group rg-aks --name myAKS --node-count 1 --generate-ssh-keys
Autoscale manuel
Comme vu ici AKS fonctionne avec un système de node pool. Un pool est un regroupement de nœuds dans mon cluster, chaque nœud étant une machine virtuelle Azure.
Pour scaler manuellement mes nodes il faut cibler un pool :
az aks scale --resource-group rg-aks --name myAKS --node-count 3 --nodepool-name #NodePoolName#
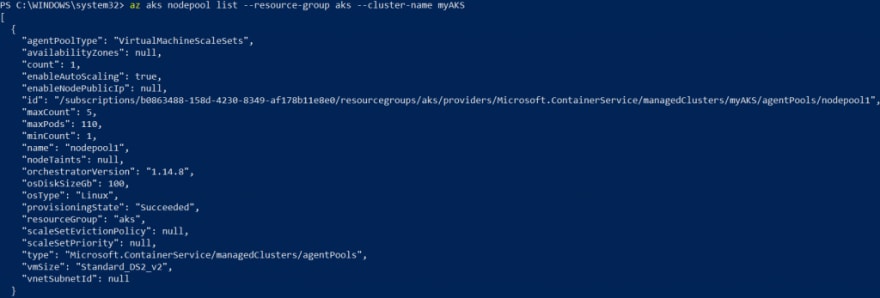
Pour obtenir un descriptif du/des pool(s), utilisez cette commande. On y voit le nom du pool à utiliser dans la commande ci-dessus.
az aks nodepool list --resource-group rg-aks --cluster-name myAKS
Il y a maintenant 3 nœuds, donc 3 VM pouvant héberger des pods, dans notre cluster.
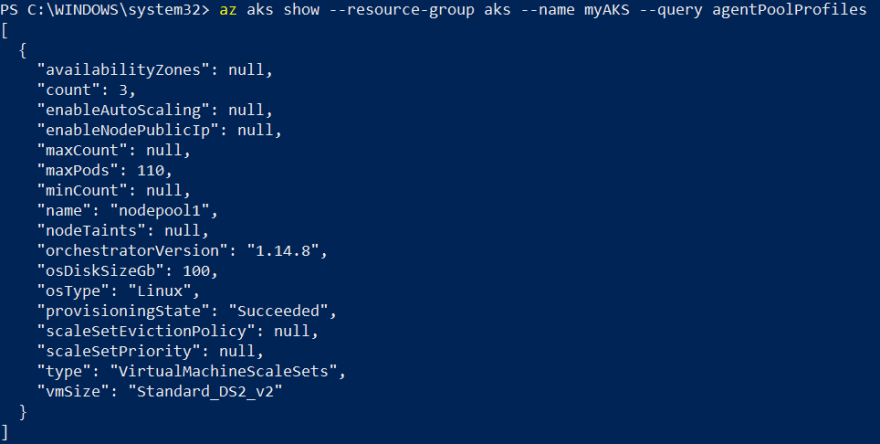
Autoscale automatique
Nous avons parlé précédemment des “ressources” avec la définition des propriétés requests et limits.
L’autoscaler AKS augmente ou diminue automatiquement la taille du pool de nœuds, en analysant la demande de ressources des pods.
• Si les pods ne peuvent pas être démarrés, car il n’y a pas assez de puissance cpu/ram sur les nœuds du pool, l’autoscaler de cluster en ajoute, jusqu’à atteindre la taille maximale du pool de nœuds.
• Si les nœuds sont sous-utilisés et que tous les pods peuvent être déployés en utilisant moins de noeuds, l’autoscaler de cluster déplace les pods puis supprime des nœuds, jusqu’à atteindre la taille minimale du pool.
Pour la mise en œuvre je dois provisionner un AKS avec le support de l’autoscale sur les nodes, il faut alors spécifier une taille minimale et maximale pour le pool de nœuds.
az aks create --resource-group rg-aks --name myAKSWithAutoscale --node-count 1 --vm-set-type VirtualMachineScaleSets --enable-cluster-autoscaler --min-count 1 --max-count 3
Par ailleurs, il est possible de configurer plus finement le fonctionnement du scaling via des paramètres supplémentaires.
Par exemple :
--scan-interval : permet de fixer la fréquence d'évaluation du cluster pour un éventuel scale. Ce paramètre permettra de temporiser suite à au scaling avant de provisionner ou supprimer à nouveau une VM. La liste complète des paramètres est disponible ici

On a maintenant un cluster avec une VM dans le node pool déclaré, scalable entre 1 et 3.
Modifier son autoscale
Si mon cluster contient un seul nodepool, je peux utiliser la commande :
az aks update --resource-group rg-aks --name myAKSWithAutoscale --update-cluster-autoscaler --min-count 1 --max-count 5

Si mon cluster utilise plusieurs nodepools, je dois utiliser l'instruction az aks nodepool update, comme ceci :
az aks nodepool update --resource-group rg-aks --cluster-name myAKSWithAutoscale --name nodepool1 --update-cluster-autoscaler --min-count 1 --max-count 5
Dernier cas d'usage, si notre cluster existe mais que l’autoscale n’a pas été configuré à la création il faut l’activer via une commande sur le pool cible avec l'argument --enable-cluster-autoscaler :
az aks nodepool update --resource-group rg-aks --cluster-name myAKSWithAutoscale --name nodepool1 --enable-cluster-autoscaler --min-count 1 --max-count 5
Nous avions précédemment demandé 3 nodes mais suite à notre configuration de l’autoscale, le nombre de nœud redescend progressivement à 1 puisqu’il n’y a pas de charge sur mes nœuds !
Nous avons donc vu ici un second niveau d’autoscaling, nous permettant de provisionner des nodes dynamiquement, afin de s’adapter à la demande en ressources des pods.
Conclusion
Après avoir abordé la haute disponibilité coté Infrastructure nous avons vu aujourd'hui comment rendre nos applicatifs résilient grâce à l'autoscaling. En effet l'un ne vas pas sans l'autre ! Configuré en premier lieu sur les pods il doit également être géré sur les nodes pour une meilleure élasticité face à la charge.
Merci à Louis-Guillaume Morand et Yves de Caqueray pour la relecture et leurs précieux conseils.
Thomas





Top comments (0)