
Hi Devs!
Welcome to the second post of Upwork Series! First of all, I really appreciate your support and kindness in my posts and YouTube channel. Thank you for motivating me to create more cool content about Python.
If you are new here let me quickly introduce you my brand new YouTube channel - Reverse Python. The main difference of this channel is - I am not teaching you boring stuff such as "JS tutorial for beginners" or "Python tutorials" this stuff is really old and not useful anymore. Instead, I am showing you real-world applications which will improve your portfolio and your future career. Believe me, you won't be disappointed!
Also check web application of Reverse Python
Anyway, enough talking, let's build this new Upwork project!
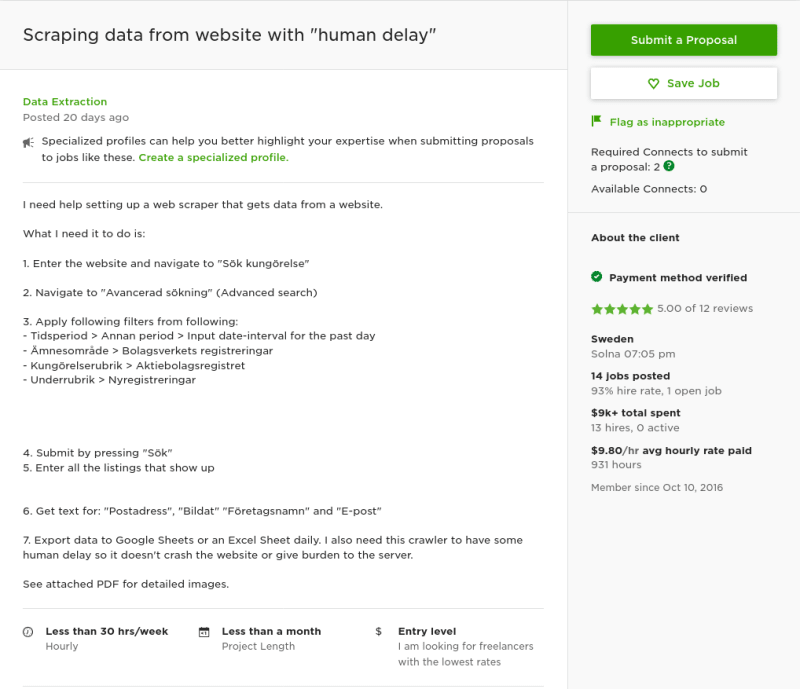
Scraping data from website with human delay
As you see our new task is to scrape some data from a website. Unfortunately, this is not normal website, so we are going to face with another messed up HTML structure.
Step 1: Understanding the task
So, our task is to navigate the target page, crawl the data and export it to excel sheet. Our automation must be with human delay to avoid detection and any other server errors.
The client provided PDF attachment under the job posting which describes the steps clearly. Here is the description of task:
I need help setting up a web scraper that gets data from a website. What I need it to do is:
- Enter the website and navigate to "Sök kungörelse"
- Navigate to "Avancerad sökning" (Advanced search)
- Apply following filters from following:
- Tidsperiod > Annan period > Input date-interval for the past day - Ämnesområde > Bolagsverkets registreringar - Kungörelserubrik > Aktiebolagsregistret - Underrubrik > Nyregistreringar- Submit by pressing "Sök"
- Enter all the listings that show up
- Get text for: "Postadress", "Bildat" "Företagsnamn" and "E-post"
- Export data to Google Sheets or an Excel Sheet daily. I also need this crawler to have some human delay so it doesn't crash the website or give burden to the server.
Our final destination will to crawl the data for "Postadress", "Bildat" "Företagsnamn" and "E-post".
Step 2: Creating our environment and installing dependencies
Now, we know what client wants from us, so let's create our virtual environment then inspect elements that we are going to crawl.
To create virtualenv run the following command in your terminal:
virtualenv env
. env/bin/activate
and install these libraries:
pip install selenium xlwt
As you know Selenium is a web automation tool and we are going to use it to navigate target pages and get data from there. xlwt is a library to generate spreadsheet files compatible with Microsoft Excel and the package itself is pure Python with no dependencies on modules or packages outside the standard Python distribution.
I know some of you will tell me to use pandas but let's just keep xlwt for this project.
Step 3: Navigating and Crawling Data
It is important to configure web driver correctly to be able to run automation. If you want to use Chrome as a web driver then you should install chromedriver. However, if you want to choose Firefox then you should install geckodriver.
Let's start by creating a class to easily handle URLs and call functions so you don't have to create web drivers in each function every time.
from selenium import webdriver
class Bolagsverket:
def __init__(self):
# set your driver path here
self.bot = webdriver.Firefox(executable_path='/path/to/geckodriver')
To see the project URL click here
Now, we are creating new function named navigate_and_crawl :
import time
def navigate_and_crawl(self):
bot = self.bot
bot.get('https://poit.bolagsverket.se/poit/PublikPoitIn.do')
time.sleep(5)
As you see I put sleep() function right after navigating to URL to act like human delay.
Enter the website and navigate to "Sök kungörelse"

Let's inspect this element

def navigate_and_crawl(self):
bot = self.bot
bot.get('https://poit.bolagsverket.se/poit/PublikPoitIn.do')
time.sleep(5)
bot.find_element_by_id('nav1-2').click()
time.sleep(5)
Simply, clicking the link after finding it with id.
Navigate to "Avancerad sökning" (Advanced search)
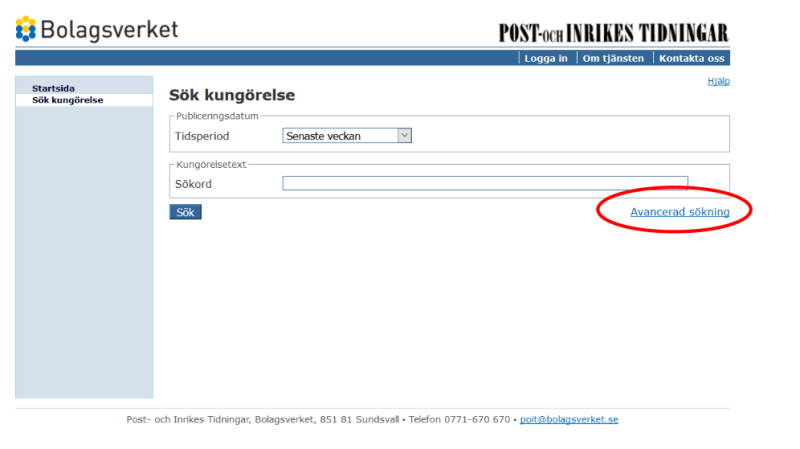
Now we need to click to "Advanced search" link.

As you see there is a one anchor tag in the form so we don't need to find element with specific id or class, just tag names will enough to click the link.
def navigate_and_crawl(self):
bot = self.bot
bot.get('https://poit.bolagsverket.se/poit/PublikPoitIn.do')
time.sleep(5)
bot.find_element_by_id('nav1-2').click()
time.sleep(5)
bot.find_element_by_tag_name('form').find_element_by_tag_name('a').click()
time.sleep(5)
I am hearing again some smart guys telling me to use xpath. It is totally fine, I am just trying to be more simple to show details.
Applying filters and Searching
- Tidsperiod > Annan period > Input date-interval for the past day
- Ämnesområde > Bolagsverkets registreringar
- Kungörelserubrik > Aktiebolagsregistret
- Underrubrik > Nyregistreringar

We should set date-interval for the past day but currently there is no data for the past day, so I will set the date as shown image above. But I will also show you how to set interval for past day, maybe when you check there will be data.
Before the code, let's take a look elements.
- Tidsperiod > Annan period > Input date-interval for the past day

Alright Devs! Now, I am going to show you one of the best solutions to click the drop down option.
search_form = bot.find_element_by_tag_name('form')
search_form.find_element_by_xpath(f"//select[@id='tidsperiod']/option[text()='Annan period']").click()
After selecting "Annan period" the date fields will appear which means we have to implement explicit waits to make WebDriver wait until these date fields show up.

import datetime
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
def navigate_and_crawl(self):
bot = self.bot
bot.get('https://poit.bolagsverket.se/poit/PublikPoitIn.do')
time.sleep(5)
bot.find_element_by_id('nav1-2').click()
time.sleep(5)
bot.find_element_by_tag_name('form').find_element_by_tag_name('a').click()
time.sleep(5)
search_form = bot.find_element_by_tag_name('form')
search_form.find_element_by_xpath(f"//select[@id='tidsperiod']/option[text()='Annan period']").click()
wait = WebDriverWait(bot, 10)
input_from = wait.until(EC.element_to_be_clickable((By.XPATH, "//input[@id='from']")))
#input_from.send_keys(str(datetime.date.today()-datetime.timedelta(1)))
input_from.send_keys('2019-09-23')
input_to = wait.until(EC.element_to_be_clickable((By.XPATH, "//input[@id='tom']")))
#input_to.send_keys(str(datetime.date.today()))
input_to.send_keys('2019-09-24')
time.sleep(3)
Actually, the form is refreshing every time when you select something from drop downs. That means we have to use waits when clicking elements.
Ämnesområde > Bolagsverkets registreringar
Kungörelserubrik > Aktiebolagsregistret
Underrubrik > Nyregistreringar
We are applying same method which we used to select "Annan period". But this time adding waits as well.
Once all values selected click the search button under the form.
amnesomrade = wait.until(EC.element_to_be_clickable((By.XPATH, "//select[@id='amnesomrade']")))
amnesomrade.find_element_by_xpath(f"//select[@id='amnesomrade']/option[text()='Bolagsverkets registreringar']").click()
time.sleep(2)
kungorelserubrik = wait.until(EC.element_to_be_clickable((By.XPATH, "//select[@id='kungorelserubrik']")))
kungorelserubrik.find_element_by_xpath(f"//select[@id='kungorelserubrik']/option[text()='Aktiebolagsregistret']").click()
time.sleep(2)
underrubrik = wait.until(EC.element_to_be_clickable((By.XPATH, "//select[@id='underrubrik']")))
underrubrik.find_element_by_xpath(f"//select[@id='underrubrik']/option[text()='Nyregistreringar']").click()
time.sleep(2)
# Search Button
button_sok = wait.until(EC.element_to_be_clickable((By.XPATH, "//input[@id='SokKungorelse']")))
button_sok.click()
time.sleep(5)
Iterate through list and crawl data
Once you searched, you will see the results as shown image below:

The automation must continuously click the result from the list, crawl the data in clicked page, go back again to results and then click next result until all ages are finished.
As client mentioned, we have to save the data in excel sheets for each page.
Let's start by finding number of all pages and number of results for each page
If you look first red circle in picture above you can see number of last page which means we have 18 pages in total.

# find number of pages and extract the string after "av"
number_of_pages = bot.find_element_by_xpath('//div[@class="gotopagediv"]/em[@class="gotopagebuttons"]').text.split("av",1)[1]
# remove any empty spaces
number_of_pages.strip().replace(" ", "")
# all results or links for each page
number_of_results = bot.find_elements_by_xpath('//table/tbody/tr')
and now are going to iterate through the pages and results to click the each link or result in the list.
Additionally, we must create the new excel sheet for each page. Remember, we have to crawl "Post Address", "Bildat", "Företagsnamn"and "Email"
wb = Workbook()
for page in range(int(number_of_pages)):
# Create new sheet for each page
sheet = wb.add_sheet('Sheet ' + str(page))
style = xlwt.easyxf('font: bold 1')
sheet.write(0, 0, 'Post Address', style)
sheet.write(0, 1, 'Bildat', style)
sheet.write(0, 2, 'Företagsnamn', style)
sheet.write(0, 3, 'Email', style)
# Click each link in results
for i in range(1, len(number_of_results) + 1):
result = bot.find_elements_by_xpath('//table/tbody/tr')[i]
link = result.find_element_by_tag_name('a')
bot.execute_script("arguments[0].click();", link)
time.sleep(2)
As you see, we are converting number_of_pages to integer because we extracted it as a string before. The reason I am using JavaScript here is to make sure that links clicked, because sometimes Selenium's click() function fails in iteration.
Now, time to crawl the data inside these links.

When we inspect the elements:

There is no any special class or id to extract these particular fields. In this kind of cases, I am using RegEx to extract the data from the strings.
I am showing you the full code block for this part so it will make sense.
wb = Workbook()
for page in range(int(number_of_pages)):
sheet = wb.add_sheet('Sheet ' + str(page), cell_overwrite_ok=True)
style = xlwt.easyxf('font: bold 1')
sheet.write(0, 0, 'Post Address', style)
sheet.write(0, 1, 'Bildat', style)
sheet.write(0, 2, 'Företagsnamn', style)
sheet.write(0, 3, 'Email', style)
for i in range(len(number_of_results)):
result = bot.find_elements_by_xpath('//table/tbody/tr')[i]
link = result.find_element_by_tag_name('a')
bot.execute_script("arguments[0].click();", link)
time.sleep(2)
information = [bot.find_element_by_class_name('kungtext').text]
try:
postaddress = re.search('Postadress:(.*),', information[0])
sheet.write(i + 1, 0, str(postaddress.group(1)))
bildat = re.search('Bildat:(.*)\n', information[0])
sheet.write(i + 1, 1, str(bildat.group(1)))
foretagsnamn = re.search('Företagsnamn:(.*)\n', information[0])
sheet.write(i + 1, 2, str(foretagsnamn .group(1)))
email = re.search('E-post:(.*)\n', information[0])
sheet.write(i + 1, 3, str(email.group(1)))
print(postaddress.group(1),bildat.group(1),foretagsnamn.group(1),email.group(1))
except AttributeError as e:
print('error => Email is null')
sheet.write(i + 1, 3, 'null')
pass
bot.back()
time.sleep(5)
wb.save('emails.xls')
print('Going to next page')
button_next= wait.until(EC.element_to_be_clickable((By.XPATH, "//input[@id='movenextTop']")))
button_next.click()
time.sleep(5)
Regex will extract the value between "Field Name" and "\n" newline in the paragraph. In some results email field is missing so I added try except to detect it and automatically set the field "null".
i + 1 is preventing overwrite the column names in excel cells. I highly recommend to check my YouTube channel for more detailed explanation.
When the data successfully crawled for a single page program is saving the data into sheet and moving to the next page.
Full Code
import time
import datetime
import re
import xlwt
from xlwt import Workbook
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
class Bolagsverket:
def __init__(self):
self.bot = webdriver.Firefox(executable_path='/home/coderasha/Desktop/geckodriver')
def navigate_and_crawl(self):
bot = self.bot
bot.get('https://poit.bolagsverket.se/poit/PublikPoitIn.do')
time.sleep(5)
bot.find_element_by_id('nav1-2').click()
time.sleep(5)
bot.find_element_by_tag_name('form').find_element_by_tag_name('a').click()
time.sleep(5)
search_form = bot.find_element_by_tag_name('form')
search_form.find_element_by_xpath("//select[@id='tidsperiod']/option[text()='Annan period']").click()
wait = WebDriverWait(bot, 10)
input_from = wait.until(EC.element_to_be_clickable((By.XPATH, "//input[@id='from']")))
input_from.send_keys('2019-09-23')
# input_from.send_keys(str(datetime.date.today()-datetime.timedelta(1)))
input_to = wait.until(EC.element_to_be_clickable((By.XPATH, "//input[@id='tom']")))
input_to.send_keys('2019-09-24')
# input_to.send_keys(str(datetime.date.today()))
time.sleep(5)
amnesomrade = wait.until(EC.element_to_be_clickable((By.XPATH, "//select[@id='amnesomrade']")))
amnesomrade.find_element_by_xpath("//select[@id='amnesomrade']/option[text()='Bolagsverkets registreringar']").click()
time.sleep(5)
kungorelserubrik = wait.until(EC.element_to_be_clickable((By.XPATH, "//select[@id='kungorelserubrik']")))
kungorelserubrik.find_element_by_xpath("//select[@id='kungorelserubrik']/option[text()='Aktiebolagsregistret']").click()
time.sleep(5)
underrubrik = wait.until(EC.element_to_be_clickable((By.XPATH, "//select[@id='underrubrik']")))
underrubrik.find_element_by_xpath("//select[@id='underrubrik']/option[text()='Nyregistreringar']").click()
# Search Button
button_sok = wait.until(EC.element_to_be_clickable((By.XPATH, "//input[@id='SokKungorelse']")))
button_sok.click()
time.sleep(5)
number_of_pages = bot.find_element_by_xpath("//div[@class='gotopagediv']/em[@class='gotopagebuttons']").text.split("av", 1)[1]
number_of_pages.strip().replace(" ","")
number_of_results = bot.find_elements_by_xpath('//table/tbody/tr')
wb = Workbook()
for page in range(int(number_of_pages)):
sheet = wb.add_sheet('Sheet' + str(page))
style = xlwt.easyxf('font: bold 1')
sheet.write(0, 0, 'Post Address', style)
sheet.write(0, 1, 'Bildat', style)
sheet.write(0, 2, 'Foretagsnamn', style)
sheet.write(0, 3, 'Email', style)
for i in range(len(number_of_results)):
result = bot.find_elements_by_xpath("//table/tbody/tr")[i]
link = result.find_element_by_tag_name('a')
bot.execute_script('arguments[0].click();', link)
time.sleep(5)
information = [bot.find_element_by_class_name('kungtext').text]
try:
postaddress = re.search('Postadress:(.*),', information[0])
sheet.write(i + 1, 0, str(postaddress.group(1)))
bildat = re.search('Bildat:(.*)\n', information[0])
sheet.write(i + 1, 1, str(bildat.group(1)))
foretagsnamn = re.search('Företagsnamn:(.*)\n', information[0])
sheet.write(i + 1, 2, str(foretagsnamn.group(1)))
email = re.search('E-post:(.*)\n', information[0])
sheet.write(i + 1, 3, str(email.group(1)))
print(postaddress.group(1), bildat.group(1), foretagsnamn.group(1), email.group(1))
except AttributeError as e:
print('Email is null')
sheet.write(i + 1, 3, 'null')
pass
bot.back()
time.sleep(5)
wb.save('emails.xls')
print('Going to next page ...')
button_next = wait.until(EC.element_to_be_clickable((By.XPATH, "//input/[@id='movenextTop']")))
button_next.click()
time.sleep(5)
bot = Bolagsverket()
bot.navigate_and_crawl()
Mission Accomplished!
You can watch the video tutorial of this project in myYouTube Channel
I hope you enjoyed and learned something from this post. Job is still open so you can send proposal to client from Upwork. Please check Reverse Python for more cool content like this. Stay Connected!





Top comments (1)
Respect! 🔥