
Recently I got an opportunity to learn about database replication then I felt that every developer should know about database replication and I have planned to write series of articles to explain the database replication such as the need of database replication and master-slave concepts and how to set up database replication on different databases and Let's start.
What is the replication
Replication is keeping multiple copies of the database.
Why replication is important
There are many reasons. I have taken three important reasons for having multiple copies of the database they are,
- Availability
- Latency
- Scalability
Let's see each one of them in details
Availability
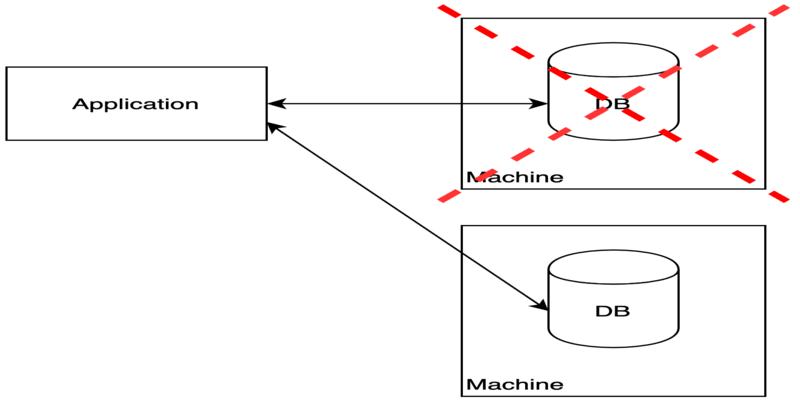
The first thing is availability, the application needs data from the database or application needs to write/persist data into the database so it fires a request to the database server then database respect to that request. This is how the application and database server communicates.
Let's say we have a single copy of the database and the database resides on a particular server goes down for some reason like something corrupt on that machine, then what happens to the request which goes to the database? The database cannot respond to the application requests and our application will go down so the application will not be available to serve the users. This is called single point of failure.
If we have multiple replicas of the database, also we have some mechanism to redirect all requests to another machine so even one machine goes down another will serve the requests. This is one of the most important reasons for having multiple replicas of the database.
Latency
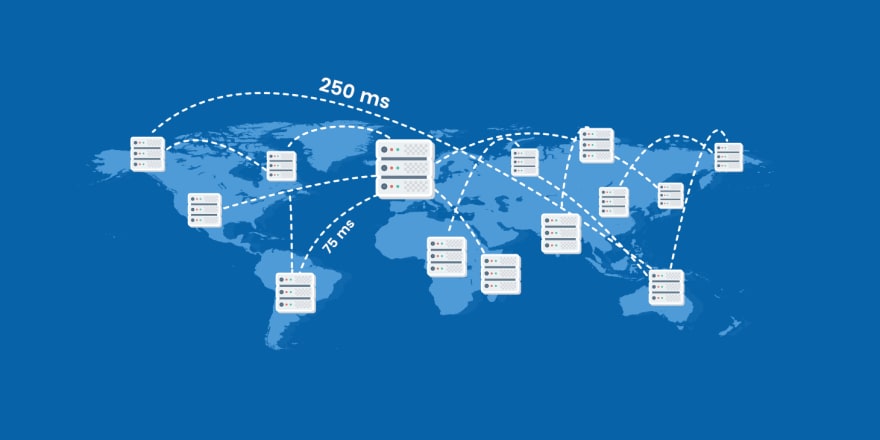
Assume our application is available in different geographical locations like the US, India, Australia and so on but our database resides in the server located in India. The person lives in the US who uses our application then all request network packets travel from the US to India to get data from the database and response packets will go back from India to the US. there is huge network latency is created because of the distance.
So if we keep a replica of our database in the US itself so whenever the user hits the request our application will go to the database which nearest to that particular geographical location. Our replication has reduced the latency caused by distance. Now you understand another important reason to have a replica of the database.
Scalability

Imaging our application is getting requests like millions per second and one single database cannot serve them all even it is managed to serve but it cannot give data in a fraction of seconds and users will feel the slowness of the application.
If we have multiple replicas of the database in different servers, we can balance the load into different servers using some load balancer and this is called load balancing. Now we have divided the requests to the different servers so the chances of overloading the servers are very less.
Another thing is that if we have multiple replicas we can do like one set of replicas takes care of write requests and others will serve read requests, in this way system is more scalable.
These are the most important reasons to have replication of the database. In the next articles, we will see Master-Slave replication architecture.
This article originally published on hashnode

Top comments (0)