
CONTENTS
- Introduction: What is overfitting
- Why overfitting happens in neural networks
- Techniques to preventing overfitting: L2 Regularization
- Techniques to preventing overfitting: Dropout Regularization
- Other things that can help: Batch normalization.
- Other things that can help: Diversify your dataset Summary and Conclusion
Introduction
When you're using deep learning, sometimes your neural network can do really well on the data you're training it with, but not as well when you test it or use it in real life. This can be really frustrating because it's not always easy to fix. In this article, we'll talk about what overfitting is in neural networks and what you can do to fix it when it happens in your model.
What Overfitting is
Overfitting is when your neural network is doing really well on the data you're training it with, but not as well when you test it or use it in real life. It happens when the neural network has learned patterns that only appear in the data you're training it with, but not in the actual problem you're trying to solve. These patterns are like noise, and they're not helpful for your final solution.

In the above image, notice how the model does really well on the data that was used to train it but performs poorly on the evaluation data. We could say in simple terms, that the model has gotten used to the training data.
It's kind of like how students can get so caught up in practicing past questions for an exam, that they can't answer any question that didn't fall into past questions training set.
Why overfitting happens
- Complex network structure
The simplest and most obvious reason why overfitting occurs is the complexity of our network. The more layers we add, the more our neural network tries to derive insights from our data.
- Insufficient data
Another reason why overfitting happens is when you're trying to learn from not enough data or data that all looks the same, or when you're running too many "epochs" (repeated training cycles) with a big network on not enough data. For example, let's say you're training a neural network to recognize the difference between a cat and a dog. If all the dogs in your training set are bulldogs, it might have trouble recognizing a chihuahua.
Another problem that can happen when you have little or similar data is that your network will stop learning too soon and will only find patterns that exist in that specific data set and not in the problem you're trying to solve.
- Poorly Synthesized data
A technique to fix the problem of "homogeneous" data is called data synthesis. This means creating new data by combining different sources. For example, if you're training a neural network to recognize a specific word (like "Hey Siri") but you want it to also work well in a noisy environment, you can make new data by combining sounds of that specific word with sounds of different noisy places. This will make the network better at recognizing the word in different environments.
Using data synthesis can be helpful in making sure your data is diverse and not too similar, but it can also cause problems if not done correctly. One way it can lead to overfitting is if the network starts to learn the noise that was used to create the new data. In other words, if the network starts to focus on the wrong things instead of the main feature you're trying to train it on.
Techniques for preventing Overfitting
- L2 regularization
L2 regularization is an idea borrowed from classical machine learning and regression. It works by adding a regularization term to the loss function. This term is the Frobenius/Matrix Norm of the weights of the neural network
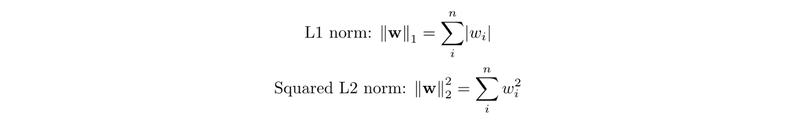
The lambda value is a number that can be adjusted to change how much regularization is used to prevent overfitting. Regularization is a technique that helps the network not to focus too much on the noise in the data. If the lambda value is zero, then regularization is not applied at all. If the lambda value is very high, then regularization becomes too strong, and the network will not learn enough from the data, which is called underfitting.
So the intuition is that the higher the value of lambda, the stronger the effect L2 regularization has on our network
- Dropout Regularization
The main Idea behind Dropout Regularization is randomly temporarily shutting off a small percentage of units within layers of our neural network to reduce the chances of our neural network depending on strong signals from any of these units.
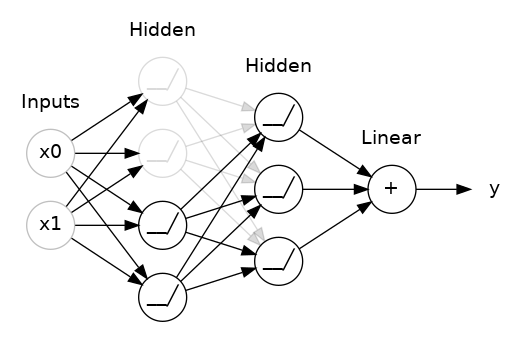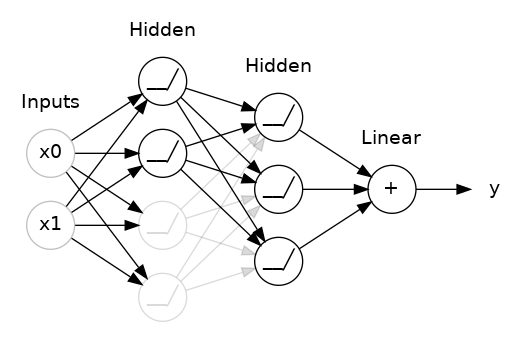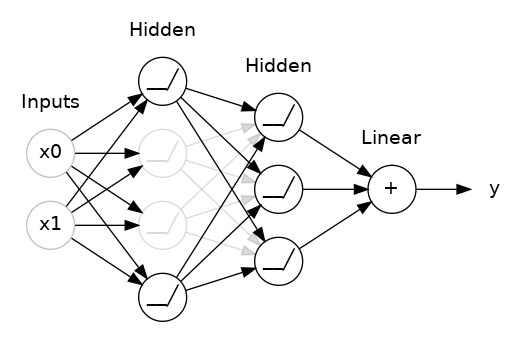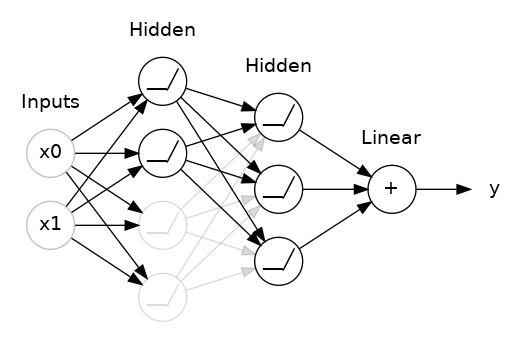
We should however be careful not to shut off a large portion of our network layers because it can cause our network to underfit our data.
Other things that can help
- Batch Normalization
Batch Normalization has this regularization effect that can help prevent overfitting.
The first benefit it gives is that it helps to set all your features to be on the same scale (i.e having the same standard deviation), helping your Neural Network to converge faster and better. Your neural network would also be less likely to depend on features that are on a higher scale than others.
- Diversify your Data
One simple way to fix overfitting is to add more diverse data to your dataset. However, this might not always be possible or easy. By having more varied data, your model will learn to recognize features that appear throughout the dataset instead of just in a small part of it.
- Transfer Learning
This is a way of addressing the issue of overfitting caused by not having enough data. By using a neural network that has been trained with a lot of data, you can use it to solve similar problems and make it better. Often, all you need to do is retrain the input and output layers of the network.
Thanks for Reading!
Thanks for reading this article! I would love to hear your thoughts, questions, or any other feedback you may have. Don't hesitate to share your thoughts in the comments section.

Top comments (0)