
In my last blog post, I explained the motivation to continuously extract data from relational databases on-premises and introduced Change Data Capture (CDC) and AWS Database Migration Service (DMS) as tools to do this while minimizing the impact on the database.
In this blog post, I show how to implement a solution to get data changes into a data stream. Data streams are a powerful tool to build near real-time analytics and other use cases, such as building applications that react to state changes. For example, you may want to trigger a process when a customer updates their consent to receive marketing information or updates their email address.
In this solution, I will use AWS DMS to continuously replicate data from a SQL Server database into an Amazon Kinesis data stream. In this data stream, each record will contain the row that was changed (updated, inserted, or deleted) in the source database with all the current and previous values for each field.
Below, you can find a diagram that represents the architecture of the solution for a database on-premises and the architecture I used on my lab environment to prepare this blog post.
Because you need network connectivity between AWS DMS and your source database, I have, simply for illustrative purposes, placed a site-to-site VPN connection between the on-premises local network and a VPC in AWS. Note that there are several alternatives to establish connectivity between on-premises networks and AWS. In my lab setup, I am running the source database in a VPC, so I just need to run my AWS DMS replication instance in the same VPC or, better yet, in another VPC with connectivity to the former one (using, for example, VPC peering).
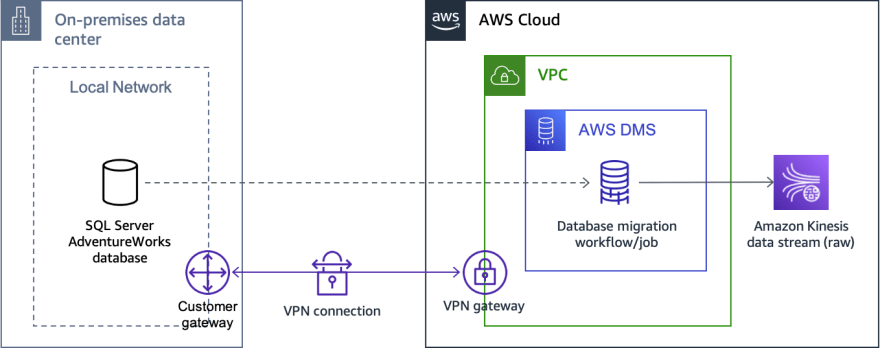 Figure 1 - Architecture for the solution with a database on-premises
Figure 1 - Architecture for the solution with a database on-premises
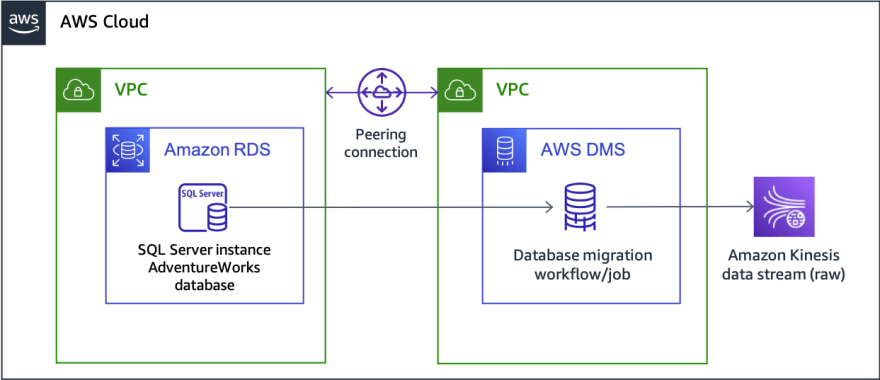 Figure 2 - Architecture for the lab environment
Figure 2 - Architecture for the lab environment
Sample database
For this exercise, as a sample database, I will use a usual suspect in the SQL Server world, the AdventureWorks sample database. More precisely, I’ll use the 2019 OLTP (Online Transaction Processing) version, as I want to simulate an OLTP workload and I want will be using SQL Server 2019 running on Amazon RDS.
I will not dive into the details about how to deploy such an environment, but if you want to replicate it, take into account that in order to restore a database from a native SQL Server backup (like the one you'd download from the Microsoft AdventureWorks web site), you need to perform the steps described in the How do I perform native backups of an Amazon RDS DB instance that's running SQL Server? article.
Preparing the database
The sample database contains five schemas and a total of 68 tables (not counting administrative tables and the ‘dbo’ schema). For this exercise, I’m going to use three tables in the ‘Production’ schema: ‘ProductInventory’, ‘ProductReview’, and ‘TransactionHistory’.
To enable continuous replication, you need to configure the database. You can find prerequisites and detailed instructions in Using a Microsoft SQL Server database as a source for AWS DMS. In my case, because I’m using AWS RDS, so I do the following:
-
Execute this query in SQL Server to enable CDC on the database:
exec msdb.dbo.rds_cdc_enable_db 'AdventureWorks2019' -
Execute these queries in SQL Server to enable CDC on each table:
USE [AdventureWorks2019] exec sys.sp_cdc_enable_table @source_schema = N'Production', @source_name = N'ProductInventory', @role_name = NULL, @supports_net_changes = 1 GO USE AdventureWorks2019 exec sys.sp_cdc_enable_table @source_schema = N'Production', @source_name = N'ProductReview', @role_name = NULL, @supports_net_changes = 1 GO USE AdventureWorks2019 exec sys.sp_cdc_enable_table @source_schema = N'Production', @source_name = N'TransactionHistory', @role_name = NULL, @supports_net_changes = 1 GO -
Run these queries to configure and enable the retention time (in seconds) for the changes in the transaction log. The documentation recommends 86399 seconds (one day), but you need to consider your need and the implications of having, potentially, to store that data in your local disks.
USE AdventureWorks2019 EXEC sys.sp_cdc_change_job @job_type = 'capture', @pollinginterval = 86399 EXEC sp_cdc_stop_job 'capture' EXEC sp_cdc_start_job 'capture'
If you are curious about the effect of these commands, you can browse the SQL Server system tables and check that now there are a few tables under a schema named ‘cdc’.
Prerequisites for AWS DMS
There are a few things that you need in your environment to successfully run a migration task in AWS DMS.
You can find more detailed instructions about how to set up some resources in the Prerequisites section of the AWS DMS Documentation.
- An IAM principal that has permissions to use AWS DMS, create the IAM roles in the next point, and full access to Kinesis data streams.
- Two IAM roles to use DMS from the AWS CLI. You can create them following https://docs.aws.amazon.com/dms/latest/userguide/CHAP_Security.html#CHAP_Security.APIRole
- A VPC with:
- At least two subnets that have a route (and allow traffic) to your database server.
- If your subnet is private, you will need either a NAT Gateway or VPC endpoints for Amazon Kinesis and AWS Secrets Manager, so the migration task can reach their corresponding endpoints.
- A Security Group that allows outbound traffic to your database server on the right port (1433 by default for SQL Server).
Setting up AWS DMS
AWS DMS requires the following components to run a replication task:
- Source and target endpoints, each with associated IAM roles to access the necessary AWS resources (if any).
- A replication instance running in a VPC that can connect to those endpoints.
Configuring the source endpoint
Storing connection details in AWS Secrets Manager
You need to configure the endpoint with the details needed to connect to your source database. You will typically need some user name and password for that, which is sensitive information. AWS DMS supports storing that sensitive data in AWS Secrets Manager. Since this is a best practice, first create a secret in AWS Secrets Manager containing the following key/value pairs:
{
"host": "<ip-address-or-url-of-your-database-server>",
"port": 1433,
"username": "<your-username>",
"password": "<your-password>"
}
- Save the previous JSON object replacing the values between angle-brackets (<>) with your own in a file named sourcedb-creds.json.
-
Run the following command using the AWS CLI and take note of the ARN of the secret you just created.
aws secretsmanager create-secret \ --name sourcedb-credentials \ --description "Credentials for the source SQL Server database" \ --secret-string file://sourcedb-creds.json Delete the previous file to avoid having your password stored in plain text around.
Note: if you don’t provide an explicit AWS Key Management Service (KMS) key, AWS Secrets Manager will use the default KMS Key to encrypt this secret. This key’s alias is “aws/secretsmanager”, which is what you will later use to grant AWS DMS access to it .
Creating a role for AWS DMS to access the secret
To access that secret, AWS DMS needs an IAM role that grants access to it and to the KMS key that AWS Secrets Manager used to encrypt it. In this section you are going to create an IAM policy that grants minimal permissions to those resources and an IAM role that uses that policy.
-
Using your favorite editor, create a text file and name it read-sourcedb-secret-policy.json; paste the following text substituting the values between angle brackets (<>) for your your own and save it.
{ "Version": "2012-10-17", "Statement": [ { "Sid": "AllowGetSecretValue", "Effect": "Allow", "Action": "secretsmanager:GetSecretValue", "Resource": "<your-secret-arn>" }, { "Effect": "Allow", "Action": [ "kms:Decrypt", "kms:DescribeKey" ], "Resource": "arn:aws:kms:<your-region>:<your-account-id>:alias/aws/secretsmanager" } ] } -
Create the IAM policy running this AWS CLI command.
aws iam create-policy \ --policy-name read-sourcedb-secret \ --policy-document file://read-sourcedb-secret-policy.json \ --description 'Policy that allows reading the sourcedb secret in AWS Secrets Manager' -
Now you can create the IAM role. Every IAM role requires a trust policy that determines which principal(s) will be able to assume it. In this case, that principal will be the AWS DMS service. Create a new text file, paste the following content and save it as dms-trust-policy.json.
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "dms.<your-region>.amazonaws.com" }, "Action": "sts:AssumeRole" } ] }
Creating the endpoint
Now you can create the endpoint.
-
Create a text file, paste the following content replacing the values between angle brackets (<>) with your own, and save it as sql-server-settings.json
{ "DatabaseName": "AdventureWorks2019", "SecretsManagerAccessRoleArn": "arn:aws:iam::<your-account-id>:role/dms-secretsmanager-role", "SecretsManagerSecretId": "arn:aws:secretsmanager:<your-region>:<your-account-id>:secret:<your-secret-id>" } -
Run the following AWS CLI command:
Note: if you are using a VPC endpoint to access AWS Secrets Manager and don’t enable private DNS hostnames in it, you will need to add the parameter
--extra-connection-attributes secretsManagerEndpointOverride=[vpce-09d9c3f89fxxxxxxx-abcd0ef1.secretsmanager.<your-region>.vpce.amazonaws.com](http://vpce-09d9c3f89fxxxxxxx-abcd0ef1.secretsmanager.<your-region>.vpce.amazonaws.com/)to the command. Replace the value with the endpoint DNS of your VPC endpoint, which you can find under the endpoint details in the VPC console.
aws dms create-endpoint \ --endpoint-identifier source-sqlserver \ --endpoint-type source \ --engine-name sqlserver \ --microsoft-sql-server-settings file://sql-server-settings.json
Take note of the ARN of this endpoint, you will need it when creating the replication task.
Creating the AWS DMS replication instance
To connect to the source database, the replication instance needs a subnet group. This group is a configuration that tells AWS DMS where to deploy Elastic Network Interfaces (ENI) so it can access resources in a VPC (e.g.: a VPC endpoint, an RDS instance, a VPN gateway, etc.). AWS DMS requires at least two subnets for a subnet group.
-
Get the identifiers of two subnets within your VPC, you can find them using the AWS Management Console or using the AWS CLI with this command:
aws ec2 describe-subnets --query "Subnets[?VpcId=='<your-vpc-id>'].SubnetId" -
Create the subnet group using the following AWS CLI command:
aws dms create-replication-subnet-group \ --replication-subnet-group-identifier mssql-replication-subnet-group \ --replication-subnet-group-description "Subnet group for the SQL Server replication instance" \ --subnet-ids "<subnet-id-1>" "<subnet-id-2>" -
Create the replication instance using the following AWS CLI command and take note of the instance ARN.
aws dms create-replication-instance \ --replication-instance-identifier mssql-replication-instance \ --allocated-storage 50 \ --replication-instance-class dms.t3.small \ --replication-subnet-group-identifier mssql-replication-subnet-group \ --no-multi-az \ --no-publicly-accessible
Note that I have set the storage to 50 GB, used a dms.t3.small instance, and used the -—no-multi-az flag. Depending on your needs, you may want to change these settings or additional ones (see the CreateReplicationInstance API documentation). You can find more guidance in Choosing the right AWS DMS replication instance for your migration.
Finally, I haven’t specified any security group, so the instance will use the default security group in the VPC. If you haven’t changed that security group, it will contain an inbound rule that allows all traffic coming from the same security group, and all outbound traffic anywhere.
Now, wait until the instance is status Available (you can check this in the AWS DMS console) and test the connection.
 Figure 3: Testing the endpoint
Figure 3: Testing the endpoint
Configuring the target endpoint
The target endpoint requires a Kinesis data stream and a role that allows DMS to access that Kinesis data stream.
Creating the Amazon Kinesis data stream
In this post, I am using a Kinesis data in provisioned mode with one shard as I am not expecting any spiky load. Depending on your own scenario, you might want to use on-demand mode or more shards in provisioned mode.
To create the data stream, run the following AWS CLI command.
aws kinesis create-stream \
--stream-name mssql-cdc \
--shard-count 1 \
--stream-mode-details StreamMode=PROVISIONED
Granting access from AWS DMS to the Kinesis data stream
AWS DMS needs to be explicitly given access to the data stream you just created. For this, you need to create an IAM policy and attach it to a new role that can be assumed by the AWS DMS service.
-
Create a new text file named write-to-stream-policy.json, paste the following content, and save it.
{ "Version": "2012-10-17", "Statement": [ { "Sid": "AllowWritingToStream", "Effect": "Allow", "Action": [ "kinesis:DescribeStream", "kinesis:PutRecord", "kinesis:PutRecords" ], "Resource": "arn:aws:kinesis:<your-region>:<your-account-id>:stream/mssql-cdc" } ] } -
Create the IAM policy using this AWS CLI command.
aws iam create-policy \ --policy-name write-to-cdc-stream \ --policy-document file://write-to-stream-policy.json \ --description 'Policy that allows writing to the mssql-cdc Kinesis data stream' -
Create the IAM role that AWS DMS will assume running the following AWS CLI command. Note that this role uses the same trust policy as the IAM role used for the source endpoint.
aws iam create-role \ --path / \ --role-name dms-kinesis-role \ --assume-role-policy-document file://dms-trust-policy.json \ --description 'Role for DMS to access Amazon Kinesis' -
Attach the policy to the newly created role by running this command.
aws iam attach-role-policy \ --role-name dms-kinesis-role \ --policy-arn arn:aws:iam::<your-account-id>:policy/write-to-cdc-stream
Creating the target endpoint
Now, you have everything set up to create the target endpoint. For that, run this command.
aws dms create-endpoint \
--endpoint-identifier target-kinesis \
--endpoint-type target \
--engine-name kinesis \
--kinesis-settings \
StreamArn=arn:aws:kinesis:<your-region>:<your-account-id>:stream/mssql-cdc,\
ServiceAccessRoleArn=arn:aws:iam::<your-account-id>:role/dms-kinesis-role,\
MessageFormat=JSON
As with the source endpoint, test the connectivity to make sure there are no issues. If there are issues, make sure that the subnets associated with the replication instance have access to Amazon Kinesis. Some hints if you are using private subnets and find problems
- Check there is a VPC endpoint for Kinesis with ENIs deployed on those subnets.
- Check that the VPC endpoint has enabled private DNS hostnames in it. If not, you will need to add the parameter
--extra-connection-attributeswith the private DNS hostname of the VPC endpoint to the command to create the endpoint. - Alternatively, you can use a NAT gateway or another type of proxy to access the Internet.
Setting up the replication task
At this point, you have everything ready to create and launch a replication task.
A replication task needs to have a table mapping, so it knows which tables and columns from the data source to read and how to write them to the target. You can also define a series of (optional) task settings you can use to customize its behavior. With those settings you can configure multiple aspects, such as logging, data validation, time travel, or data filtering. You can find a list of the available settings in the Specifying task settings for AWS Database Migration Service tasks documentation.
In this example, you are going to configure a task that does continuous replication of two source tables in the SQL Server database into the Kinesis data stream. In the output, each record will include the updated and previous values for each row affected (when relevant, as for deletes and inserts this does not apply).
Depending on the database operation Each record in the stream will represent and updated row from the database with a JSON dictionary that includes three items: “data”, “before”, and “metadata”.
The “data” and “before” items will contain a key-value pair for column and value key for each column in the table, where “data” has the values in the updated row, and “before” has the values in the updated row prior to the database operation.
The “metadata” item will contain information about the operation, such as its timestamp, the operation type (update, delete, or insert), or the table and schema the operation was performed on. Note that when inserting or deleting a row, the “before” element will not be included in the dictionary.
Here’s a sample record for an update operation:
{
"data": {
"ProductReviewID": 3,
"ProductID": 937,
"ReviewerName": "Alice",
"ReviewDate": "2013-11-15T00:00:00Z",
"EmailAddress": "alice@example.com",
"Rating": 3,
"Comments": "Maybe it's just because I'm new to mountain biking, but I had a terrible time getting use\r\nto these pedals. In my first outing, I wiped out trying to release my foot. Any suggestions on\r\nways I can adjust the pedals, or is it just a learning curve thing?",
"ModifiedDate": "2013-11-15T00:00:00Z"
},
"before": {
"ProductReviewID": "3",
"ProductID": "937",
"ReviewerName": "Alice",
"ReviewDate": "2013-11-15T00:00:00Z",
"EmailAddress": "alice@example.com",
"Rating": "2",
"Comments": "Maybe it's just because I'm new to mountain biking, but I had a terrible time getting use\r\nto these pedals. In my first outing, I wiped out trying to release my foot. Any suggestions on\r\nways I can adjust the pedals, or is it just a learning curve thing?",
"ModifiedDate": "2013-11-15T00:00:00Z"
},
"metadata": {
"timestamp": "2022-02-02T11:52:59.913277Z",
"record-type": "data",
"operation": "update",
"partition-key-type": "schema-table",
"schema-name": "Production",
"table-name": "ProductReview",
"transaction-id": 128599
}
}
Table Mapping
Diving a bit deeper into table mapping, you need to select which tables from which schemas are going to be read from the data source. You have the option of using the ‘%’ as a wildcard for the name, or part of it, of the tables and schemas. You can also and apply some transformations prior to data being written at the target. You can do things like filtering values, adding/removing columns, renaming, adding suffixes, or changing data types (you can find a complete list of actions and capabilities in the Transformation rules and actions documentation). In this example, I’m not applying any transformation, only reading two tables from two different schemas.
You can define those mappings either in the AWS DMS console or by using a JSON file. In this guide, I’m using the latter.
Create a text file and paste the following JSON object. Save the file as table-mapping-rules.json.
{
"rules": [
{
"rule-type": "selection",
"rule-id": "1",
"rule-name": "products",
"object-locator": {
"schema-name": "Production",
"table-name": "Product"
},
"rule-action": "include",
"filters": []
},
{
"rule-type": "selection",
"rule-id": "2",
"rule-name": "transaction-history",
"object-locator": {
"schema-name": "Production",
"table-name": "TransactionHistory"
},
"rule-action": "include",
"filters": []
},
{
"rule-type": "selection",
"rule-id": "3",
"rule-name": "product-reviews",
"object-locator": {
"schema-name": "Production",
"table-name": "ProductReview"
},
"rule-action": "include",
"filters": []
}
]
}
Task settings
AWS DMS allows defining the behavior of a task very granularly, although in this case I’m only going to define rules for logging into Amazon CloudWatch Logs and a behavior to include the “before” values of a row that has been updated.
Create a text file, paste the following JSON object, and save it as task-settings.json.
{
"Logging": {
"EnableLogging": true,
"LogComponents": [
{
"Id": "TRANSFORMATION",
"Severity": "LOGGER_SEVERITY_DEFAULT"
},
{
"Id": "SOURCE_UNLOAD",
"Severity": "LOGGER_SEVERITY_DEFAULT"
},
{
"Id": "IO",
"Severity": "LOGGER_SEVERITY_DEFAULT"
},
{
"Id": "TARGET_LOAD",
"Severity": "LOGGER_SEVERITY_DEFAULT"
},
{
"Id": "PERFORMANCE",
"Severity": "LOGGER_SEVERITY_DEFAULT"
},
{
"Id": "SOURCE_CAPTURE",
"Severity": "LOGGER_SEVERITY_DEFAULT"
},
{
"Id": "SORTER",
"Severity": "LOGGER_SEVERITY_DEFAULT"
},
{
"Id": "REST_SERVER",
"Severity": "LOGGER_SEVERITY_DEFAULT"
},
{
"Id": "VALIDATOR_EXT",
"Severity": "LOGGER_SEVERITY_DEFAULT"
},
{
"Id": "TARGET_APPLY",
"Severity": "LOGGER_SEVERITY_DEFAULT"
},
{
"Id": "TASK_MANAGER",
"Severity": "LOGGER_SEVERITY_DEFAULT"
},
{
"Id": "TABLES_MANAGER",
"Severity": "LOGGER_SEVERITY_DEFAULT"
},
{
"Id": "METADATA_MANAGER",
"Severity": "LOGGER_SEVERITY_DEFAULT"
},
{
"Id": "FILE_FACTORY",
"Severity": "LOGGER_SEVERITY_DEFAULT"
},
{
"Id": "COMMON",
"Severity": "LOGGER_SEVERITY_DEFAULT"
},
{
"Id": "ADDONS",
"Severity": "LOGGER_SEVERITY_DEFAULT"
},
{
"Id": "DATA_STRUCTURE",
"Severity": "LOGGER_SEVERITY_DEFAULT"
},
{
"Id": "COMMUNICATION",
"Severity": "LOGGER_SEVERITY_DEFAULT"
},
{
"Id": "FILE_TRANSFER",
"Severity": "LOGGER_SEVERITY_DEFAULT"
}
]
},
"BeforeImageSettings": {
"EnableBeforeImage": true,
"FieldName": "before",
"ColumnFilter": "all"
}
}
Creating the replication task
Run the following AWS CLI commands to create and start the task respectively.
aws dms create-replication-task \
--replication-task-identifier mssql-to-kinesis-cdc
--source-endpoint-arn arn:aws:dms:<your-region>:<your-account-id>:endpoint:<your-source-endpoint-id> \
--target-endpoint-arn arn:aws:dms:<your-region>:<your-account-id>:endpoint:<your-target-endpoint-id> \
--replication-instance-arn arn:aws:dms:<your-region>:<your-account-id>:rep:<your-replication-instance-id> \
--migration-type cdc \
--table-mappings file://table-mapping-rules.json \
--replication-task-settings file://task-settings.json \
--resource-identifier mssql-to-kinesis-cdc
aws dms start-replication-task \
--replication-task-arn arn:aws:dms:<your-region>:<your-account-id>:task:<your-task-id> \
--start-replication-task-type start-replication
Note that, because this is a continuous replication task, you can decide at what point in time in the database you want to start the replication from and when to stop. You can also stop and resume the task.
After a few minutes, your task should be in the state “Replication ongoing“.
 Figure 4: Task state
Figure 4: Task state
Testing the solution
To test the solution, perform some update, insert or delete in one of the two source tables, for example, run the following SQL statement against your source database:
UPDATE AdventureWorks2019.Production.ProductReview
SET Rating = 5 WHERE ProductReviewID = 2
Wait for about a minute until the replication task has written into your Kinesis data stream and then read from the stream.
If you are running this tutorial from a Unix-type command processor such as bash, you can automate the acquisition of the shard iterator using a nested command, like this (scroll horizontally to see the entire command):
SHARD_ITERATOR=$(aws kinesis get-shard-iterator --shard-id shardId-000000000000 --shard-iterator-type TRIM_HORIZON --stream-name <your-stream-name> --query 'ShardIterator')
aws kinesis get-records --shard-iterator $SHARD_ITERATOR --query "Records[-1].Data" | sed 's/"//' | base64 --decode
If you are running this tutorial from a system that supports PowerShell, you can automate acquisition of the shard iterator using a command such as this (scroll horizontally to see the entire command):
aws kinesis get-records --shard-iterator ((aws kinesis get-shard-iterator --shard-id shardId-000000000000 --shard-iterator-type TRIM_HORIZON --stream-name Foo).split('"')[4])`
Conclusion
In this post, I have shown how to set up a replication task to stream changes in a relational databases into a data stream. In the next post, I will showcase how to process data from the stream in real time.





Top comments (0)