
Motivação
No último artigo da série, discutimos diversos desafios enfrentados por iniciantes na área, que vão desde crenças autolimitantes até a procrastinação, frequentemente justificada pela espera do momento ideal para iniciar uma carreira como engenheiro de machine learning. Agora, para aqueles que acabaram de chegar aqui por acaso, recomendo iniciar sua jornada lendo este artigo para se familiarizarem com o projecto.
Hoje, nossa jornada começa a ganhar impulso, e a partir de agora, vamos pôr a mão na massa. No final, completaremos o projeto funcional para enriquecer o portfólio de projetos paralelos. Para aceder o notebook do projeto, clique neste link. Minha recomendação é que abra seu próprio notebook e programe em paralelo comigo.
pre-requisito
Para quem deseja pôr a mão na massa comigo, há três opções disponíveis:
- Utilize o Google Colab.
- Utilize o Kaggle (minha recomendação).
- Instale o Anaconda em seu computador
Entendendo CRISP-DM na prática
Segundo a wikipedia CRISP-DM é a abreviação de Cross Industry Standard Process for Data Mining, que pode ser traduzido como Processo Padrão Inter-Indústrias para Mineração de Dados. Ele descreve abordagens comumente usadas por especialistas em mineração de dados para atacar problemas.O CRISP-DM consiste em seis fases sequenciais, a saber:
- Compreensão do negócio (Business understanding) – O que o negócio precisa?
- Compreensão dos dados (Data understanding) – Que dados temos/precisamos? Estão limpos?
- Preparação dos dados (Data preparation) – Como organizamos os dados para modelagem?
- Modelagem (Modeling) – Quais técnicas de modelagem devemos aplicar?
- Avaliação (Evaluation) – Qual modelo atende melhor aos objetivos do negócio?
- Implantação (Deployment) – Como os interessados acessam os resultados?
Neste artigo veremos as fases 1, 2 e o 3 do CRISP-DM. Estás pronto para começar?
1. Compreensão do negócio
É fundamental compreender os objetivos e requisitos do negócio, pois isso permite a subsequente transformação desses objetivos em metas de mineração de dados. No notebook do projeto, durante a primeira fase do CRISP-DM, detalhamos minuciosamente os objetivos da fictícia empresa Vitari Imobiliárias. Ao final desta etapa, convertemos esses requisitos em metas específicas de mineração de dados, delineando o projeto da empresa para a construção de um modelo preditivo de aprendizado de máquina. Veja o print abaixo.

Minha sugestão é que você crie sua própria empresa fictícia e pratique cada fase do CRISP-DM, acompanhando-me com seu notebook aberto. Isso proporcionará uma experiência prática e enriquecedora.
2. Compreensão dos dados
Todo modelo de aprendizado de máquina é orientado a dados. No nosso caso, estamos abordando um problema no setor imobiliário, com foco no desenvolvimento de um modelo de aprendizado de máquina que prevê os preços de casas no estado da Califórnia, nos Estados Unidos. Para o efeito usamos o dataset da statlib, e quanto as ferramentas usamos o pandas para carregar os dados. Veja no print abaixo
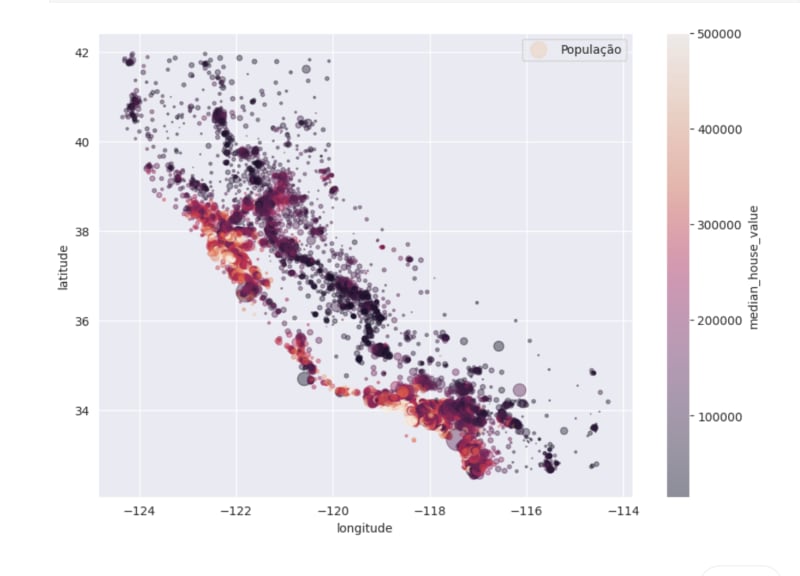
Nesta fase do projeto, utilizamos os conceitos de análise de dados para criar gráficos fundamentais que auxiliam na compreensão e interpretação dos atributos do conjunto de dados. No final desse processo, por meio dos gráficos construídos, constatamos uma forte associação entre os preços dos imóveis e sua localização, destacando-se especialmente a proximidade ao mar e a densidade populacional.
3. Preparação dos dados
Esta é a fase do projeto em que o engenheiro de machine learning dedica mais de 80% do seu tempo, coletando os dados necessários, explorando-os para compreender sua qualidade, conteúdo e estrutura, e identificando possíveis problemas. No nosso caso, aqui estão os pontos que abordamos nesta fase:
- Seleção de Características Relevantes: Identificamos as variáveis explicativas e a variável resposta cruciais para o nosso modelo.
- Limpeza e Pré-processamento dos Dados: Realizamos a imputação de dados faltantes e aplicamos a codificação de rótulos (Label Encoding) em variáveis categóricas.
- Transformação dos Dados para Formato Adequado aos Algoritmos de ML: Após separar e tratar os dados numéricos e categóricos, reintegramos ambos para formar um conjunto unificado, facilitando a criação das variáveis explicativas
Proximo passo
Para evitar que o artigo se torne extenso, encerraremos por hoje. Não deixe de acompanhar o código fonte do projeto para ver os conceitos do CRISP-DM na prática. No próximo artigo, abordaremos as partes 4 e 5 do CRISP-DM, e a parte 6 será discutida em um artigo separado já que vamos falar de implantação do nosso modelo de apredizando de máquina.
Conclusão
Hoje, iniciamos a exploração do CRISP-DM, reconhecendo-o como uma ferramenta fundamental para profissionais da área de dados. Essa metodologia desempenha um papel crucial na padronização do processo de mineração de dados, fornecendo uma estrutura robusta para orientar cada etapa do projeto.
Com o objetivo de pôr o CRISP-DM em prática, começamos a desenvolver um projeto (um modelo de aprendizado de máquina para prever preços de imóveis) que será progressivamente desenvolvido até a conclusão, abrangendo todas as fases. Este projeto representará uma oportunidade valiosa para aplicar os conceitos aprendidos, enfrentar desafios reais e aprimorar as habilidades práticas em mineração de dados. Estamos ansiosos para acompanhar esse desenvolvimento até a fase de depuração, consolidando assim o entendimento e a aplicação efetiva do CRISP-DM. Cuidem-se e até a próxima!

Top comments (0)