
This post was originally written on DevOpStar. Check it out here
Amazon Textract is a newly GA OCR (Optical character recognition) service that was originally announced at re:Invent late 2018. The basic functionality available currently are the extraction of text in three of the following categories.
- Raw text
- Forms
- Tables
If you want to play around with the service before we deep dive into it, I recommend checking out the demo.
Overview
Textract in itself isn't anything unique, and its real value lies in it sitting in AWS where we can harness some of the surrounding services to make it a more useful service.
The problem I wanted to solve related to the non for profit my partner Yhana started; WA Animals, and one of the problems she faced regularly which was never having enough time to go through the endless emails and process animal adoption paperwork.
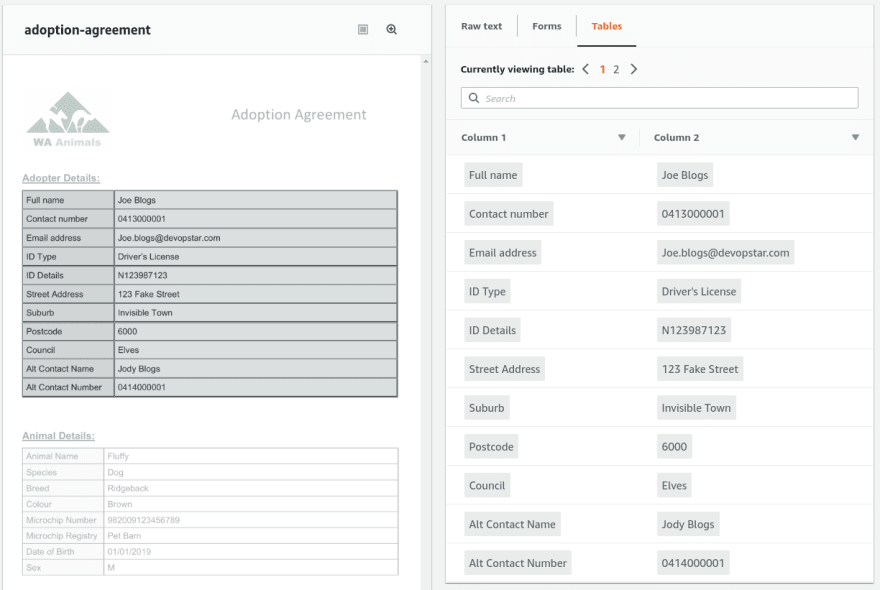
Initial testing found that Textract was more then capable of extracting the table field from our adoption form template, so I felt confident that I was going to be able to achieve a working solution by the end of this.
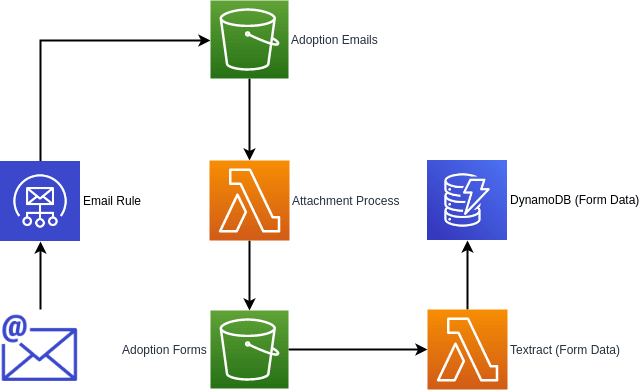
Architecture
The proposed design for the form processor will be entirely Serverless and an overview of what it looks like can be seen below.
The process flow:
- New Email comes into the inbox of WA Animals
- Email rule places it into an Adoption email S3 bucket
- Event fires an Attachment processing Lambda which strips out the attachment (converting it to a Textract friendly format if required) and places it into an Adoption forms S3 bucket
- Emails are removed from the bucket after processing
- Event fires the Textract processing Lambda which pulls out table data from the form
- Table data is put into a DynamoDB instance
Implementation
A couple prerequisites that need to be fulfilled before we're able to trigger on Email rules.
SES Domain Verification
In order to trigger on incoming emails you'll need to have a domain setup in SES along with an email address to receive incoming mail for.

Having a Domain Identity setup should happen if you have email setup going to a domain hosted on AWS WorkMail. For more specific setups consult the Amazon SES documentation.
Project Setup
Code for this project is available at t04glovern/aws-textract-adoption-forms. I will go over the setup process I followed when developing it; however if you just want to get started, pull the repo down using the following.
git clone https://github.com/t04glovern/aws-textract-adoption-forms.git
If you are going to setup a Serverless application yourself from scratch, run the following.
## Project Setup
mkdir form-process
cd form-process
npm install -g serverless
serverless create --template aws-python3 --name form-process
Boto3 Requirements [Workaround]
Currently the boto3 client deployed to Lambda (as of the 1st of June 2019) doesn't include Textract. We'll need to force an update on the client using python requirements
serverless plugin install -n serverless-python-requirements
npm install
Create a requirements.txt file in the form-process folder and add the following to it
boto3>=1.9.111
Finally, open the serverless.yml file and confirm the following lines are present
plugins:
- serverless-python-requirements
custom:
pythonRequirements:
dockerizePip: non-linux
noDeploy: []
noDeploy tells the serverless-python-requirements plugin to include boto3 and not omit it. More information can be found here.
Serverless.yml
There's a couple small things I should mention about the configuration of the serverless.yml for the project that might not make sense if you are just looking at the code.
ReceiptRule
Currently the official use of SES Resource types in Serverless framework isn't properly supported. What I found was that the order of deployment for resources wouldn't be correctly processed. This led to Bucket Does not exit errors when trying to reference a bucket in the AWS::SES::ReceiptRule resource.
A similar problem would use to occur on AWS::S3::BucketPolicy resources as while back, but it appears to have been fixed now.
To get around this I had to ensure that the naming conventions I used on my bucket names conformed with the normalizedName format outlined in the Serverless documentation. For example If I wanted a bucket named waanimalsadoptionemails then I would need to ensure that the Bucket resource name in my serverless configuration was S3BucketWaanimalsadoptionemails (the casing is very important here).
iamRoleStatements
The IAM Role Statements that make up this template can appear to be a little confusing at first glance, however there is method to the madness in order to totally lock-down access to all the resources involved.
| Allow | textract:AnalyzeDocument | “*” |
|---|---|---|
| Allow | dynamodb:PutItem | AdoptionDynamoDBTable.Arn |
| Allow | s3:GetObject, s3:DeleteObject | arn:aws:s3:::waanimalsadoptionemails/* |
| Allow | s3:ListBucket | arn:aws:s3:::waanimalsadoptionemails |
| Allow | s3:GetObject, s3:PutObject | arn:aws:s3:::waanimalsadoptionforms/* |
| Allow | s3:ListBucket | arn:aws:s3:::waanimalsadoptionforms |
DynamoDB
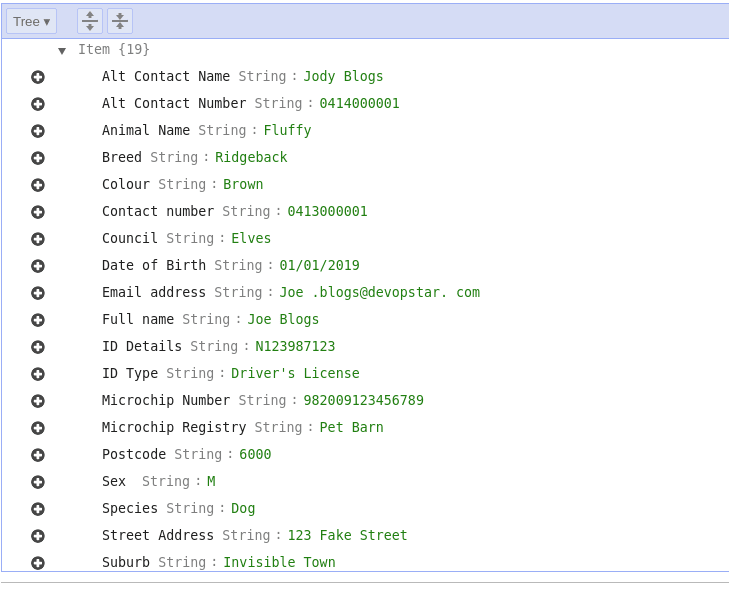
The creation of a DynamoDB table is included as the final resting place for the data extracted by Textract from documents. Part of creating a new table involves defining a Partition Key (a simple primary key in normal talk). If we take a look at the document we're trying to process It becomes clear that the best key to use would be the animals Microchip Number as it is always going to be unique. When defining the table, just ensure that key is specified
AdoptionDynamoDBTable:
Type: AWS::DynamoDB::Table
Properties:
AttributeDefinitions:
- AttributeName: Microchip Number
AttributeType: S
KeySchema:
- AttributeName: Microchip Number
KeyType: HASH
ProvisionedThroughput:
ReadCapacityUnits: 1
WriteCapacityUnits: 1
TableName: waanimalsadoptionforms
Textract Document Analysis
The actual code for the Table extraction was based heavily on the Exporting Tables into a CSV File example in the documentation. When performing an AnalyzeDocument a document is passed in by its S3 bucket location. The response syntax is quite complex to parse as it contains a lot of fields and data. The following function in textract/tableparser.py gives a good overview of the process
def get_table_dict_results(self):
# Analyze the document from S3
client = boto3.client(service_name='textract')
response = client.analyze_document(
Document={'S3Object': {
'Bucket': self.bucket, 'Name': self.document}},
FeatureTypes=["TABLES"])
# Get the text blocks
blocks = response['Blocks']
blocks_map = {}
# Strip out the table data from the rest of the info
table_blocks = []
for block in blocks:
blocks_map[block['Id']] = block
if block['BlockType'] == "TABLE":
table_blocks.append(block)
if len(table_blocks) <= 0:
return {}
cells = {}
for _, table in enumerate(table_blocks):
# Extract each entry in the table data and clean it.
cells = self.generate_table_dict(table, blocks_map, cells)
return cells
There are a couple other supporting classes in the final implementation that help abstract some of the DynamoDB and S3 file handling, however for the most part this logic is pretty straight forward. When the textract Lambda in our serverless function is called, the following code grabs a reference to the S3 object that triggered the event, and hands it off to Textract. The resulting data is put into DynamoDB.
def textract(event, context):
bucketName = event['Records'][0]['s3']['bucket']['name']
bucketKey = event['Records'][0]['s3']['object']['key']
# Textract process to dictionary of items
table_parser = TableParser(
bucketName,
bucketKey
)
table_dict = table_parser.get_table_dict_results()
if len(table_dict) > 0:
# Put dictionary into DynamoDB
db_utils = DbUtils()
db_utils.put(raw=table_dict)
return {
"item": table_dict,
"event": event
}
Serverless Deploy
When you're ready to deploy the serverless application, you can do so with the following commands
# Install dependencies
cd form-process
npm install
# Install serverless (if you haven't already)
npm install -g serverless
# Deploy
serverless deploy
Once deployed you should be able to check to confirm the Rule Set is in place in the SES console

Sending an example email with an adoption form in PDF or Image format will trigger the entire pipeline end to end.

The final result is a new entry in the DynamoDB instance with all the table data from the adoption form.
Summary
Overall I'm really happy with the functionality that Textract offers. It seems like the OCR is pretty on point and only occasionally trips up. Moving forward I believe this pipeline could be further improved by adding filters on the incoming documents based on some metadata from the email.
Right now we're processing all attachments, and there's no logic stopping it from ingesting attachments that aren't Adoption forms. The saving grace is that they have to include a Microchip Number field in order to land in DynamoDB.
To remove the stack once you're done, you can simply run the following (ensure the buckets are empty before running this).
serverless remove
Summary
Are you using Amazon Textract? I'm very interested in hearing about it! Success or failure, please reach out to me on Twitter @nathangloverAUS and start a discussion.





Top comments (1)
Processing animal adoption papers with Amazon Textract streamlines the paperwork by automatically extracting text, tables, and other data from scanned documents, making it easier to organize and manage adoption forms. This AI-driven tool reduces manual data entry, ensuring accuracy and efficiency in handling important details. Whether you're managing a small shelter or a large organization, Amazon Textract can significantly enhance your document processing workflow. For more information on animal care and adoption, visit goldenminiature.com/