I had just passed the AWS SAA exam when I came across this challenge by Forrest Brazeal on r/AWSCertifications. I thought this was a perfect way to put into practice what I had just learnt and to further my AWS development and I highly recommend it for someone in my position.
You can see how it turned out here: https://www.sbargery.co.uk
The Journey Begins
The first thing I did was to split the challenge up into smaller tasks (divide and conquer). My first task was to build the basic infrastructure that would serve my website. Secondly, I would create a visitor counter and implement all the components that went along with that. Thirdly, I would utilise GitHub Actions for CI/CD integration of my Lambda functions. Lastly, I would develop my resume using HTML and CSS.
First Task - Building the Basic Infrastructure
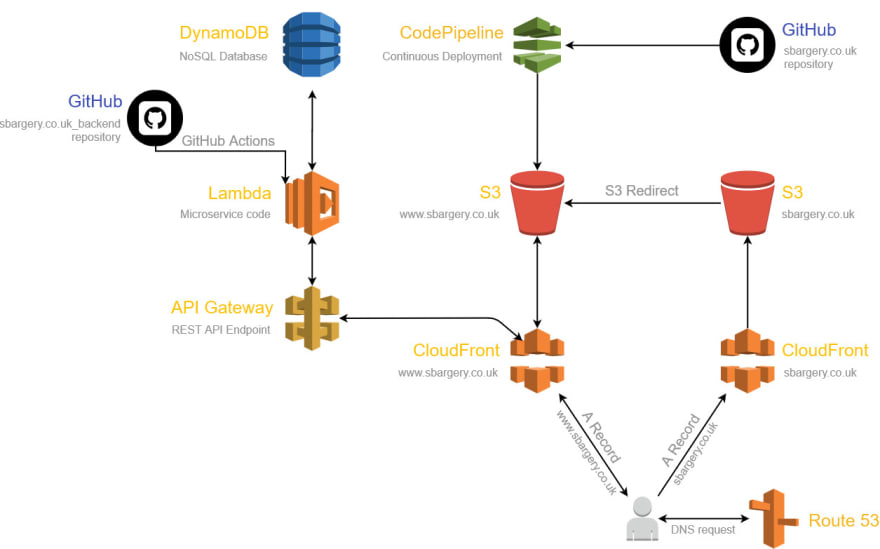
I utilised the following AWS services (which I will go into detail about below) to create a static website hosted on AWS using a serverless architecture:
- S3 - for hosting the actual content of the website
- CloudFront - for distributing the content from the S3 bucket (origin) and providing a secure connection (HTTPS)
- Route 53 - for routing the requests for sbargery.co.uk and www.sbargery.co.uk to the Cloudfront distributions
- ACM - for the SSL certificate
- CodePipeline - for CI/CD with my GitHub repository
S3 - Set up buckets
I actually created two S3 buckets, a non-www bucket (sbargery.co.uk) and a www bucket (www.sbargery.co.uk) and turned on Static Website Hosting for them both. I then used the Redirect requests option on the non-www bucket to redirect requests to the www bucket which held my static website files.
CloudFront - Set up CDN
I set up a CloudFront distribution for each S3 bucket so each website had its own CDN. During set up I also created an SSL certificate using AWS ACM and selected this in the CloudFront distribution settings.
Route53 - DNS registry
Here I created a Hosted Zone for my website and then inside this, created two Alias Record Sets, for the non-www and www domains which pointed to the corresponding CloudFront distributions.
Optional steps
After I set these three services up I then made my bucket only accessible from my CDN, disabling direct access to the S3 bucket endpoint. This prevents security issues and avoids content duplication in search engines. This involved blocking all public access and creating a Bucket Policy for my www bucket to allow CDN access.
One issue I had with this setup was when updating the website CloudFront would serve the cached version and not the one I had just pushed. This is due to the nature of how CloudFront works. I was able to overcome this by invalidating the updated files in CloudFront. This would the make CloudFront go and fetch the updated files from the origin (the S3 bucket).
CodePipeline - CI/CD
The last part of the first task was to set up CI/CD so I could easily update my website and it would pushed to GitHub and then update my files in my S3 bucket. This was fairly new to me so I'm glad I was given the opportunity to learn this concept. I used AWS's CodePipeline which, once setup with my website GitHub repository, receives a webhook from GitHub when a change is made to my repo. The webhook tells CodePipeline to initiate a pipeline execution. This allowed for a very smooth website update process.
Second Task - Creating a Visitor Counter
For the visitor counter I used the following AWS services:
- DynamoDB - to store visitors to the site
- Lambda - to read and write to the DynamoDB table using 2 functions written in Python
- API Gateway - to accept REST API requests from my site and communicate with the Lambda functions
I then used JavaScript to call the GET and POST API requests.
DynamoDB - Set up a database
For this second task I worked backwards creating a table in DynamoDB first. The table would hold the date and time of the visit, the IP address of the visitor and a universally unique identifier (UUID) for the primary key.
Lambda - Python functions
I created two Lambda functions written in Python. One to read the visitor count from the database and another to write a new record to the database. I'm fairly new to Python so it was fun to develop two small functions using the language.
API Gateway - REST API requests
This last step was probably the most frustrating, however, having completed it, it now feels like a big accomplishment. It was all down to CORS. I created an API in API Gateway that used the GET and POST methods and linked them to my corresponding Lambda functions. My Lambda functions worked, my database was operating well and the REST API endpoints were doing their thing. However, calling them from my website was another matter. After quite a few hours of researching, enabling CORS, adding and removing headers, editing the Gateway API request and response, I finally got it working. It's probably not as difficult as I made it out to be but as I'm quite new to this I needed to do a lot of googling to work out how it all functioned. Now I know how it works it should be easy to figure out in future. I guess that's just learning in general, right?
Third Task - CI/CD Integration
Although I had a already used CodePipeline for CI/CD with regards to my static website files, I wanted to try my hand at GitHub Actions for my Lambda functions.
I created a new GitHub repository for my Lambda functions so I could work on them locally and then deploy them automatically to AWS Lambda.
Once pushed to GitHub, using GitHub Actions and workflow .yml files, both functions are unit tested using pytest with their corresponding test_*.py files and are then deployed to AWS Lambda. As I mentioned earlier, I am a Python beginner, so this was brand new to me. Learning all about unit testing was very interesting and then seeing all the ticks appear as GitHub Actions worked through my workflow was pretty exciting.
One step I am yet to complete is Step 12 - Infrastructure as Code. However, I came across this tutorial which has given me a good understanding and a baseline from where I will continue and finish this step.
Fourth Task - Developing my Resume
The last thing I needed to do was develop my resume. I created a simple page using HTML and CSS for this. Something that I may implement in future is creating a json file which would contain all of my resume data that my page would then read from.
Conclusion
I am so glad I took on this challenge. I learnt so much in such a small space of time and had great fun doing it. This challenge involved a lot of googling that lead me down some late night rabbit holes which I really enjoyed when I found the light at the end of the tunnel.
A big thank you to Forrest Brazeal for creating this challenge. I am looking forward building on what I have already achieved and to any more challenges he may release in future.
All the way through this challenge I kept adding to my architectural diagram below, created with https://www.draw.io. I am very happy with the result.
Good luck to all that take on this challenge.





Top comments (0)