
Asynchronous transcription can be applied in various contexts. For developers looking to implement a robust, scalable, and efficient transcription solution, the Google Cloud Platform (GCP) offers an ideal environment. In this article, we’ll explore an asynchronous video-to-text transcription solution built with GCP using an event-driven and serverless architecture.
Potential Applications
The provided solution is particularly well-suited for long video-to-text transcriptions, efficiently handling videos that are more than an hour long. This makes it ideal for a wide array of applications across various sectors. Here are some examples:
- State Institutions or local authorities: Transcribing meetings, hearings, and other official recordings to ensure transparency and accessibility.
- Company Meetings: Creating accurate records of internal meetings, conferences, and training sessions to enhance communication.
- Educational Institutions: Transcribing lectures, seminars, and workshops to aid in learning and research.
For shorter videos, the Gemini Pro API can handle the entire video-to-text transcription process, offering a streamlined and efficient solution for quicker, smaller-scale transcription needs.
Solution Overview
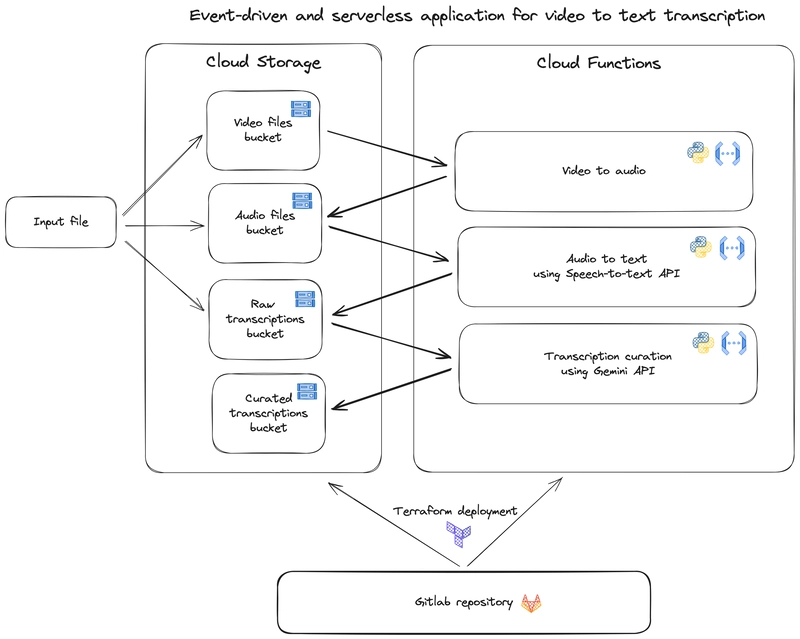
Our solution comprises three event-driven Cloud Functions, each triggered by specific events in different Cloud Storage buckets using an Eventarc trigger. Event-driven Cloud Functions are deployed pieces of code on GCP, invoked in response to an event in the cloud environment. In our case, we want our functions to be invoked when a file is upload in a specific Cloud Storage bucket. Eventarc is a standardized solution to manage events on GCP. Eventarc triggers route these events between resources. In this particular case, each Eventarc trigger listen to new objects in a specific Cloud Storage bucket, and then triggers the associated Cloud Function. The event data is passed to the function.
More information about Cloud Functions
More information about Eventarc triggers.
The four buckets used in our architecture are:
- Video Files Bucket: Where users upload their video files.
- Audio Files Bucket: Stores the extracted audio files.
- Raw Transcriptions Bucket: Contains the initial transcriptions generated by the Chirp speech-to-text model.
- Curated Transcriptions Bucket: Stores the curated transcriptions, enhanced by Gemini.
The application architecture is designed to be modular and scalable. Here’s a step-by-step breakdown of the workflow:
-
Video Upload and Audio Extraction
When a user uploads a video file to the
video-filesbucket, thevideo-to-audioCloud Function is triggered. This function usesffmpegto extract the audio from the video file and save it in theaudio-filesbucket.
import os
import subprocess
from google.cloud import storage
import functions_framework
import logging
logger = logging.getLogger(__name__)
@functions_framework.cloud_event
def convert_video_to_audio(cloud_event):
"""Video to audio event-triggered cloud function."""
data = cloud_event.data
bucket_name = data['bucket']
video_file_name = data['name']
destination_bucket_name = os.environ.get("AUDIO_FILES_BUCKET_NAME")
if not video_file_name.endswith(('.mp4', '.mov', '.avi', '.mkv')):
logger.info(f"File {video_file_name} is not a supported video format.")
return
storage_client = storage.Client()
bucket = storage_client.bucket(bucket_name)
blob = bucket.blob(video_file_name)
tmp_video_file = f"/tmp/{video_file_name}"
blob.download_to_filename(tmp_video_file)
audio_file_name = os.path.splitext(video_file_name)[0] + '.mp3'
tmp_audio_file = f"/tmp/{audio_file_name}"
command = f"ffmpeg -i {tmp_video_file} -vn -acodec libmp3lame -q:a 2 {tmp_audio_file}"
subprocess.call(command, shell=True)
destination_bucket = storage_client.bucket(destination_bucket_name)
destination_blob = destination_bucket.blob(audio_file_name)
destination_blob.upload_from_filename(tmp_audio_file)
os.remove(tmp_video_file)
os.remove(tmp_audio_file)
logger.info(f"Converted {video_file_name} to {audio_file_name} and uploaded to {destination_bucket_name}.")
-
Audio to Text Transcription
The upload of the audio file to the
audio-filesbucket triggers theaudio-to-textCloud Function. This function uses Chirp, a highly accurate speech-to-text model, and the Speech-to-Text API, to transcribe the audio and stores the raw transcription in theraw-transcriptionsbucket.
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
from google.cloud import storage
import functions_framework
from typing import Dict
import logging
import time
import os
from . import chirp_model_long
logger = logging.getLogger(__file__)
def transcribe_batch_gcs(
project_id: str,
gcs_uri: str,
region: str = "us-central1"
) -> cloud_speech.BatchRecognizeResults:
"""Transcribes audio from a Google Cloud Storage URI.
Parameters
----------
project_id: The Google Cloud project ID.
gcs_uri: The Google Cloud Storage URI.
Returns
-------
The RecognizeResponse.
"""
client = SpeechClient(
client_options=ClientOptions(
api_endpoint=f"{region}-speech.googleapis.com",
)
)
config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["fr-FR"],
model="chirp",
)
file_metadata = cloud_speech.BatchRecognizeFileMetadata(uri=gcs_uri)
request = cloud_speech.BatchRecognizeRequest(
recognizer=f"projects/{project_id}/locations/{region}/recognizers/_",
config=config,
files=[file_metadata],
recognition_output_config=cloud_speech.RecognitionOutputConfig(
inline_response_config=cloud_speech.InlineOutputConfig(),
),
processing_strategy=cloud_speech.BatchRecognizeRequest.ProcessingStrategy.DYNAMIC_BATCHING
)
operation = client.batch_recognize(request=request)
logger.info("Waiting for operation to complete...")
response = operation.result(timeout=1000)
transcript = ""
for result in response.results[gcs_uri].transcript.results:
if len(result.alternatives) > 0:
logger.info(f"Transcript: {result.alternatives[0].transcript}")
transcript += f" \n{result.alternatives[0].transcript}"
logger.debug(f"Transcript: {transcript}")
return transcript
@functions_framework.cloud_event
def speech_to_text_transcription(cloud_event):
"""Audio file transcription via Speech-to-text API call."""
data: Dict = cloud_event.data
event_id = cloud_event["id"]
event_type = cloud_event["type"]
input_bucket = data["bucket"]
audio_file_name = data["name"]
destination_bucket_name = os.environ.get("RAW_TRANSCRIPTIONS_BUCKET_NAME")
logger.info(f"Event ID: {event_id}")
logger.info(f"Event type: {event_type}")
logger.info(f"Bucket: {input_bucket}")
logger.info(f"File: {audio_file_name}")
storage_client = storage.Client()
start = time.time()
transcript = transcribe_batch_gcs(
project_id=os.environ.get("PROJECT_ID"),
gcs_uri=f"gs://{input_bucket}/{audio_file_name}"
)
stop = time.time()
raw_transcription_file_name = os.path.splitext(audio_file_name)[0] + '_raw.txt'
destination_bucket = storage_client.bucket(destination_bucket_name)
destination_blob = destination_bucket.blob(raw_transcription_file_name)
destination_blob.upload_from_string(transcript, content_type='text/plain; charset=utf-8')
logger.debug(transcript)
logger.info(f"JOB DONE IN {round(stop - start, 2)} SECONDS.")
About Chirp:
Chirp is a state-of-the-art speech-to-text model developed to provide highly accurate and fast transcription services. It supports a wide range of languages and dialects, making it a versatile choice for diverse transcription needs. It is available in the Speech-to-Text API.
More information about long audio to text transcription.
-
Transcription Curation
Finally, the
curate-transcriptionCloud Function is triggered by the new transcription file in theraw-transcriptionsbucket. This function sends the raw transcription to the Gemini API that usesgemini-promodel for curation and stores the refined transcription in thecurated-transcriptionsbucket.
import vertexai
from vertexai.generative_models import GenerativeModel
import functions_framework
from google.cloud import storage
import time
import logging
import os
from typing import Dict
logger = logging.getLogger(__file__)
@functions_framework.cloud_event
def transcription_correction(cloud_event):
"""Gemini API call to correct and enhance speech-to-text transcription."""
data: Dict = cloud_event.data
event_id = cloud_event["id"]
event_type = cloud_event["type"]
input_bucket = data["bucket"]
raw_transcription_filename = data["name"]
destination_bucket_name = os.environ.get("CURATED_TRANSCRIPTIONS_BUCKET_NAME")
logger.info(f"Event ID: {event_id}")
logger.info(f"Event type: {event_type}")
logger.info(f"Bucket: {input_bucket}")
logger.info(f"File: {raw_transcription_filename}")
storage_client = storage.Client()
input_bucket = storage_client.get_bucket(input_bucket)
input_blob = input_bucket.get_blob(raw_transcription_filename)
transcript = input_blob.download_as_string()
vertexai.init(project=os.environ.get("PROJECT_ID"), location="us-central1")
model = GenerativeModel(model_name="gemini-1.0-pro-002")
prompt = f"""
YOUR CUSTOM PROMPT GOES HERE.
PROVIDING CONTEXT AND GIVING INFORMATION ABOUT THE RESULT YOU EXPECT IS NECESSARY.
{transcript}
"""
n_tokens = model.count_tokens(prompt)
logger.info(f"JOB : SPEECH-TO-TEXT TRANSCRIPTION CORRECTION. \n{n_tokens.total_billable_characters} BILLABLE CHARACTERS")
logger.info(f"RESPONSE WILL PROCESS {n_tokens.total_tokens} TOKENS.")
start = time.time()
response = model.generate_content(prompt)
stop = time.time()
curated_filename = raw_transcription_filename.replace("_raw", "_curated")
destination_bucket = storage_client.bucket(destination_bucket_name)
destination_blob = destination_bucket.blob(curated_filename)
destination_blob.upload_from_string(response.text, content_type='text/plain; charset=utf-8')
logger.debug(response.text)
logger.info(f"JOB DONE IN {round(stop - start, 2)} SECONDS.")
The chosen architecture is modular and event-driven, which brings several advantages:
- Scalability: This application can handle short or long videos, up to 8 hours.
-
Flexibility: The separation of concerns allows for easy maintenance and upgrades. If the user uploads a video in the
video-filesbucket, the three cloud function will be triggered. But if the user upload an audio in theaudio-filesbucket, then only the two last cloud functions will be triggered. - Cost-Efficiency: Cloud Functions are serverless. Using Cloud Functions ensures that resources are only used when necessary, reducing costs.
Deployment with Terraform
To ensure our solution is not only powerful but also easily manageable and deployable, we use Terraform for infrastructure as code (IaC). Terraform allows us to define our cloud resources in declarative configuration files, providing several key benefits:
- Infrastructure configurations can be version-controlled using Git, following GitOps principles. This means changes to the infrastructure are tracked, reviewed, and can be rolled back if necessary.
- As our application grows, Terraform makes it easy to manage our infrastructure by simply updating the configuration files.
- Terraform makes the deployment of our application reliable and repeatable.
In this particular case, four cloud storage buckets and three cloud functions are needed. We use one terraform resource for the cloud functions and another for the buckets. This provides a flexible code, and makes it easier to integrate and manage new buckets or cloud functions. More information about terraform : Terraform documentation.
# locals.tf
locals {
function_definitions = [
{
name = "convert_video_to_audio",
source_dir = "../services/video_to_audio_cloud_function"
input_bucket = var.video_files_bucket_name
},
{
name = "speech_to_text_transcription",
source_dir = "../services/transcript_cloud_function"
input_bucket = var.audio_files_bucket_name
},
{
name = "transcription_correction",
source_dir = "../services/gemini_cloud_function"
input_bucket = var.raw_transcriptions_bucket_name
}
]
}
From this locals.tf file, the user can add, configure or remove cloud functions very easily. The cloud_functions.tf file uses one terraform resource for all cloud functions, and loops over these function definitions.
# cloud_functions.tf
resource "random_id" "bucket_prefix" {
byte_length = 8
}
resource "google_storage_bucket" "source_code_bucket" {
name = "${random_id.bucket_prefix.hex}-source-code-bucket"
location = var.location
force_destroy = true
uniform_bucket_level_access = true
}
data "archive_file" "function_sources" {
for_each = { for def in local.function_definitions : def.name => def }
type = "zip"
output_path = "/tmp/${each.value.name}-source.zip"
source_dir = each.value.source_dir
}
resource "google_storage_bucket_object" "function_sources" {
for_each = data.archive_file.function_sources
name = "${basename(each.value.output_path)}-${each.value.output_md5}.zip"
bucket = google_storage_bucket.source_code_bucket.name
source = each.value.output_path
}
data "google_storage_project_service_account" "default" {}
resource "google_project_iam_member" "gcs_pubsub_publishing" {
project = var.deploy_project
role = "roles/pubsub.publisher"
member = "serviceAccount:${data.google_storage_project_service_account.default.email_address}"
}
resource "google_service_account" "account" {
account_id = "gcf-sa"
display_name = "Test Service Account - used for both the cloud function and eventarc trigger in the test"
}
resource "google_project_iam_member" "roles" {
for_each = {
"invoking" = "roles/run.invoker"
"event_receiving" = "roles/eventarc.eventReceiver"
"artifactregistry_reader" = "roles/artifactregistry.reader"
"storage_object_admin" = "roles/storage.objectUser"
"speech_client" = "roles/speech.client"
"insights_collector_service" = "roles/storage.insightsCollectorService"
"aiplatform_user" = "roles/aiplatform.user"
}
project = var.deploy_project
role = each.value
member = "serviceAccount:${google_service_account.account.email}"
depends_on = [google_project_iam_member.gcs_pubsub_publishing]
}
resource "google_cloudfunctions2_function" "functions" {
for_each = { for def in local.function_definitions : def.name => def }
depends_on = [
google_project_iam_member.roles["event_receiving"],
google_project_iam_member.roles["artifactregistry_reader"],
]
name = each.value.name
location = var.location
description = "Function to process ${each.value.name}"
build_config {
runtime = "python39"
entry_point = each.value.name
environment_variables = {
BUILD_CONFIG_TEST = "build_test"
}
source {
storage_source {
bucket = google_storage_bucket.source_code_bucket.name
object = google_storage_bucket_object.function_sources[each.key].name
}
}
}
service_config {
min_instance_count = 1
max_instance_count = 3
available_memory = "256M"
timeout_seconds = 60
available_cpu = 4
environment_variables = {
PROJECT_ID = var.deploy_project
AUDIO_FILES_BUCKET_NAME = var.audio_files_bucket_name
RAW_TRANSCRIPTIONS_BUCKET_NAME = var.raw_transcriptions_bucket_name
CURATED_TRANSCRIPTIONS_BUCKET_NAME = var.curated_transcriptions_bucket_name
}
ingress_settings = "ALLOW_INTERNAL_ONLY"
all_traffic_on_latest_revision = true
service_account_email = google_service_account.account.email
}
event_trigger {
trigger_region = var.location
event_type = "google.cloud.storage.object.v1.finalized"
retry_policy = "RETRY_POLICY_RETRY"
service_account_email = google_service_account.account.email
event_filters {
attribute = "bucket"
value = google_storage_bucket.video_transcription_bucket_set[each.value.input_bucket].name
}
}
}
Similarly the buckets.tf file uses only one terraform resource for all Cloud Storage buckets.
# buckets.tf
resource "google_storage_bucket" "video_transcription_bucket_set" {
for_each = toset([
var.video_files_bucket_name,
var.audio_files_bucket_name,
var.raw_transcriptions_bucket_name,
var.curated_transcriptions_bucket_name
])
name = each.value
location = var.location
storage_class = "STANDARD"
force_destroy = true
uniform_bucket_level_access = true
}
Costs
Storage:
$0.026 per gigabyte per month
Speech-to-Text API v2:
Depends on the amount of audio you plan to process:
- $0.016 per minute processed per month for 0 to 500,000 minutes of audio
- $0.01 per minute processed per month for 500,000 to 1,000,000 minutes of audio
- $0.008 per minute processed per month for 1,000,000 to 2,000,000 minutes of audio
- $0.004 per minute processed per month for over 2,000,000 minutes of audio
Gemini API:
Under the following limits, the service is free of charge:
- 15 requests per minute
- 1 million tokens per minute
- 1,500 requests per day If you want to exceed these limits, a pay-as-you-go policy is applied. Pricing details
Cloud Functions:
The pricing depends on how long the function runs, how many times it is triggered, and the resources that are provisioned. The following link explains the pricing policy for event-driven cloud functions.
Estimate the costs of your solution with Google Cloud’s pricing calculator.
Example:
A state institution wants to automate transcript generation for meetings. The average duration of these meetings is 4 hours. The records are uploaded to GCP using this solution. Let’s simulate the costs of one transcription for this specific use case using the simulator:
The final cost per month, with one transcription per month, is estimated to be $5.14. More than half the costs are due to Speech-to-Text API use.
| Service Display Name | Name | Quantity | Region | Total Price (USD) |
|---|---|---|---|---|
| Speech-to-Text V2 | Cloud Speech-to-Text Recognition | 240.0 | global | 3.84 |
| Cloud Functions 1 | CPU Allocation Time (2nd Gen) | 40080000 | us-central1 | 0.96192 |
| Cloud Functions 1 | Memory Allocation Time (2nd Gen) | 25600000000 | us-central1 | 0.0625 |
| Cloud Functions 1 | Invocations (2nd Gen) | 1000.0 | global | 0 |
| Cloud Functions 2 | CPU Allocation Time (2nd Gen) | 4008000.0 | europe-west1 | 0.09619 |
| Cloud Functions 2 | Memory Allocation Time (2nd Gen) | 2560000000 | europe-west1 | 0.00625 |
| Cloud Functions 2 | Invocations (2nd Gen) | 1000.0 | global | 0 |
| Cloud Functions 3 | CPU Allocation Time (2nd Gen) | 4008000.0 | europe-west1 | 0.09619 |
| Cloud Functions 3 | Memory Allocation Time (2nd Gen) | 2560000000 | europe-west1 | 0.00625 |
| Cloud Functions 3 | Invocations (2nd Gen) | 1000.0 | global | 0 |
| Cloud Storage 1 | Standard Storage Belgium | 3.0 | europe-west1 | 0.06 |
| Cloud Storage 2 | Standard Storage Belgium | 0.5 | europe-west1 | 0.01 |
| Cloud Storage 3 | Standard Storage Belgium | 0.01 | europe-west1 | 0.0002 |
| Cloud Storage 4 | Standard Storage Belgium | 0.01 | europe-west1 | 0.0002 |
| Total Price: | 5.1397 | |||
| Prices are in US dollars, effective date is 2024-07-01T08:32:56.935Z | ||||
| The estimated fees provided by Google Cloud Pricing Calculator are for discussion purposes only and are not binding on either you or Google. Your actual fees may be higher or lower than the estimate. | ||||
| Url to the estimate: | Link to estimate |
Conclusion
Leveraging AI to enhance video-to-text transcription on Google Cloud Platform offers significant benefits in scalability, flexibility, and efficiency. By integrating Chirp for speech-to-text conversion and Gemini Pro for transcription curation, and managing the deployment with Terraform, this solution provides a robust, easily deployable framework for high-quality transcriptions across various applications.
Thanks for reading! I’m Maximilien, data engineer at Stack Labs.
If you want to discover the Stack Labs Data Platform or join an enthousiast Data Engineering team, please contact us.

Top comments (0)