When developing code that sends email to your customers, it’s smart to try things out on a test list first. Using our sink-domain service helps you avoid negative impact to your reputation during tests. Next you’ll want to check that your code is working at scale on a realistic sized recipient list and flush out any code performance issues… but how?
You could use Microsoft Excel to put together .csv recipient-list files for you, but there are practical limitations, and it’s slow. You’ll be using fields like “substitution_data that require JSON encoding, and Excel doesn’t help you with those. Performance-wise, anything more than a few hundred rows in Excel is going to get cumbersome.
What we need is a tool that will generate realistic looking test lists; preferably of any size, up to hundreds of thousands of recipients, with safe sink-domain addresses. Excel would be really slow at doing that – we can do much better with some gentle programming.
The second requirement, perhaps less obvious, is testing your uploads to SparkPost’s built-in suppression-list functionality. It’s good practice to upload the suppressed addresses from your previous provider before mailing – see, for example our Migration Guides. You might need to rehearse a migration without using your real suppression addresses. Perhaps you don’t have easy access to them right now, because your old provider is playing awkward and doesn’t have a nice API. Luckily, with very little extra code, we can also make this tool generate “practice suppression lists.
You’re on my list
CSV files have a “header in line 1 of the file, giving the names of each field. Handy hint: you can get an example file, including the header line, directly from SparkPost, using the “Download a Recipient List CSV template button right here:
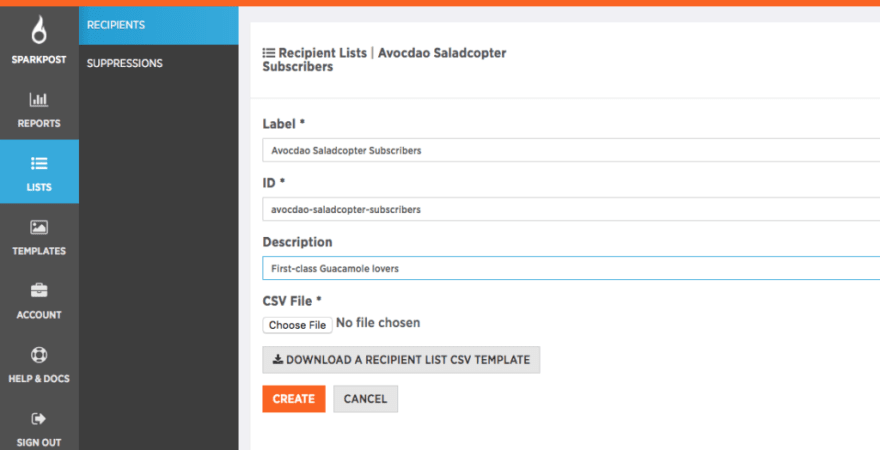
The SparkPost recipient-list .csv format looks like this:
email,name,return_path,metadata,substitution_data,tags
recipient@example.com,Example Recipient,reply@example.com,"{""foo"": ""bar""}","{""member"": ""Platinum"", ""region"": ""US""}","[""test"", ""example""]"
recipient2@example.com,Jake,reply@example.com,"{""foo"": ""bar""}","{""member"": ""Platinum"", ""region"": ""US""}","[""test"", ""example""]"
The metadata, substitution_data, and tags fields can carry pretty much anything you want.
SparkPost's suppression list .csv format is equally fun, and looks like this:
recipient,transactional,non_transactional,description,subaccount_id
anon11779856@demo.sink.sparkpostmail.com,true,true,Example data import,0
Let’s have an argument
Some command-line arguments would be nice, so we can change the lists we’re generating. Here’s the arguments we’ll accept, which translate nicely into design goals for this project:
- A flag to say whether we’re generating a recipient list or a suppression list
- How many records we want (make it optional – say 10 as a default)
- A recipient domain to generate records for (optional – default as something safe, such as demo.sink.sparkpostmail.com).
Downloading and using the tool
Firstly, you’ll need python, pip, and git installed. If you don’t already have them, there are some simple instructions to in my previous blogpost. Then we use git clone to download the project. The external package names is needed, we can install that using pip3.
$ git clone https://github.com/tuck1s/gen-SparkPost-Lists-python.git
Initialized empty Git repository in /home/stuck/gen-SparkPost-Lists-python/.git/
remote: Counting objects: 32, done.
remote: Total 32 (delta 0), reused 0 (delta 0), pack-reused 32
Unpacking objects: 100% (32/32), done.
$ sudo pip3 install names
Collecting names
Installing collected packages: names
Successfully installed names-0.3.0
$ cd gen-SparkPost-Lists-python/
$ ./gen-sparkpost-lists.py recip 10
After that final command, you should see the list output to the screen. If you want to direct it into a file, you just use >, like this:
$ ./gen-sparkpost-lists.py recip 10 > mylist.csv
That’s all there is to it! If you run the tool with no arguments, it gives some guidance on usage:
$ ./gen-sparkpost-lists.py
NAME
./gen-sparkpost-lists.py
Generate a random, SparkPost-compatible Recipient- or Suppression-List for .CSV import.
SYNOPSIS
./gen-sparkpost-lists.py recip|supp|help [count [domain]]
OPTIONAL PARAMETERS
count = number of records to generate (default 10)
domain = recipient domain to generate records for (default demo.sink.sparkpostmail.com)
[stuck@ip-172-31-20-126 gen-SparkPost-Lists-python]$
Inside the code – special snowflakes
Here’s the kind of data we want to generate for our test recipient-lists.
email,name,return_path,metadata,substitution_data,tags
anon13061346@demo.sink.sparkpostmail.com,Teddy Lanier,bounce@demo.sink.sparkpostmail.com,"{""custID"": 3156295}","{""memberType"": ""bronze"", ""state"": ""KY""}","[""gwen"", ""bacon"", ""hass"", ""fuerte""]"
anon94133309@demo.sink.sparkpostmail.com,Heriberto Pennell,bounce@demo.sink.sparkpostmail.com,"{""custID"": 78804336}","{""memberType"": ""platinum"", ""state"": ""MT""}","[""bacon""]"
anon14982287@demo.sink.sparkpostmail.com,Terry Smialek,bounce@demo.sink.sparkpostmail.com,"{""custID"": 16745544}","{""memberType"": ""platinum"", ""state"": ""WA""}","[""bacon""]"
The metadata, substitution data and tags are from our example company, Avocado Industries. Let’s pick a line of that apart, and hide the double-quotes ”” so we can see it more clearly:
Metadata:
{
"custID": 3156295
}
Substitution_data:
{
"memberType": "bronze",
"state": "KY"
}
Tags (these are types of avocado, by the way!)
[
"gwen",
"bacon",
"hass",
"fuerte"
]
We want each recipient email address to be unique, so that when imported into SparkPost, the list is exactly the asked-for length. Sounds easy – we can just use a random number generator to produce an ID like the ones shown above. The catch is that random functions can give the same ID during a run, and on a long run that is quite likely to happen. We need to prevent that, eliminating duplicate addresses as we go.
Python provides a nice set() datatype we can use that’s relatively efficient:
uniqFlags = set()
:
:
:
dataRow.append(randomRecip(domain, numDigits, uniqFlags))
We’ve created a global set object, uniqFlags which will acts as a scratchpad for random numbers we’ve already used – and pass it into the function randomRecip in the usual way.
# Need to treat ensureUnique only with mutating list methods such as 'add', so the updated value is returned to the calling function
def randomRecip(domain, digits, ensureUnique):
taken = True
while taken:
localpartnum = random.randrange(0, 10**digits)
taken = localpartnum in ensureUnique # If already had this number, then pick another one
ensureUnique.add(localpartnum)
return 'anon'+str(localpartnum).zfill(digits)+'@'+domain # Pad the number out to a fixed length of digits
Python allows changes made to ensureUnique inside the function using the .add() method to show up in the global data – in other words, the parameter is called by reference.
For the other fields, picking random values from a small set of options is easy. For example:
def randomMemberType():
tiers = ['bronze', 'silver', 'gold', 'platinum']
return random.choice(tiers)
We can pick randomized US postal states in exactly the same way. The custID field is just a naive random number (so it might repeat). I’ve left that as an exercise for the reader to change, if you wish (hint: use another set).
For the tags field – we would like to assign somewhere between none and all of the possible Avocado varieties to each person; and for good measure we’ll randomize the order of those tags too. Here’s how we do that:
# Compose a random number of tags, in random shuffled order, from a preset short list.
# List of varieties is taken from: http://www.californiaavocado.com/how-tos/avocado-varieties.aspx
def randomTags():
avocadoVarieties = ['bacon', 'fuerte', 'gwen', 'hass', 'lamb hass', 'pinkerton', 'reed', 'zutano']
k = random.randrange(0, len(avocadoVarieties))
t = avocadoVarieties[0:k]
random.shuffle(t)
return json.dumps(t)
What’s in a name?
SparkPost recipient-list format supports a text name field, as well as an email address. It would be nice to have realistic-looking data for that. Fortunately, someone’s already built a package that uses the 1990 US Census data, that turns out to be easy to leverage. You’ll recall we installed the names package earlier.
# Prepare a cache of actual, random names - this enables long lists to be built faster
nameList = []
for i in range(100):
nameList.append( { 'first': names.get_first_name(), 'last': names.get_last_name() } )
The names library calls take a little while to run, which could really slow down our list creation. Rather than calling the function for every row, the above code builds a nameList of first and last names, that we can choose from later. For our purposes, it’s OK to have text names that might repeat (i.e. more than one Jane Doe) – only the email addresses need be strictly unique.
The choice of 100 in the above code is fairly arbitrary – it will give us “enough randomness when picking a random first-name and separately picking a random last-name.
Full speed ahead
A quick local test shows the tool can create a 100,000 entry recipient list – about 20MB – in seven seconds, so you shouldn’t have to wait long even for large outputs.
The output of the tool is just a text stream, so you can redirect it into a file using >, like this:
$ ./gen-sparkpost-lists.py recip 100000 >mylist.csv
You can also pipe it into other tools. CSVkit is great for this – you can choose which columns to filter on (with csvcut), display (with csvlook) etc. For example, you could easily create a file with just email, name, and substitution_data, and view it:
$ ./gen-sparkpost-lists.py recip 10 | csvcut -c1,2,5 | csvlook
|-----------------------------------------------------------------------------------------------------------|
| email | name | substitution_data |
|-----------------------------------------------------------------------------------------------------------|
| anon78856278@demo.sink.sparkpostmail.com | Linda Erdmann | {"memberType": "gold", "state": "MN"} |
| anon27569456@demo.sink.sparkpostmail.com | James Glenn | {"memberType": "platinum", "state": "PA"} |
| anon82026154@demo.sink.sparkpostmail.com | Mark Morris | {"memberType": "bronze", "state": "NC"} |
| anon99410317@demo.sink.sparkpostmail.com | Daniel Baldwin | {"memberType": "platinum", "state": "TX"} |
| anon40941199@demo.sink.sparkpostmail.com | Cammie Cornell | {"memberType": "platinum", "state": "TX"} |
| anon81569289@demo.sink.sparkpostmail.com | Mary Pearce | {"memberType": "bronze", "state": "NC"} |
| anon87708262@demo.sink.sparkpostmail.com | Angella Souphom | {"memberType": "bronze", "state": "NV"} |
| anon74282988@demo.sink.sparkpostmail.com | Antonio Erdmann | {"memberType": "platinum", "state": "MD"} |
| anon48883171@demo.sink.sparkpostmail.com | Randolph Maranto | {"memberType": "bronze", "state": "MA"} |
| anon17719693@demo.sink.sparkpostmail.com | Jack Hudson | {"memberType": "silver", "state": "CA"} |
|-----------------------------------------------------------------------------------------------------------|
And finally …
Download the code and make your own test recipient and suppression lists. Leave a comment below to let me know how you’ve used it and what other hacks you’d like to see.
This post was originally posted on SparkPost.





Top comments (0)