
What do you think is the output of the following Python code?
>>> flag = "🇺🇸"
>>> reversed_flag = flag[::-1]
>>> print(reversed_flag)
Questions like this make me want to immediately open a Python REPL and try the code out because I think I know what the answer is, but I'm not very confident in that answer.
Here's my line of thinking when I first saw this question:
- The
flagstring contains a single character. - The
[::-1]slice reverses theflagstring. - The reversal of a string with a single character is the same as the original string.
- Therefore,
reversed_flagmust be"🇺🇸".
That's a perfectly valid argument. But is the conclusion true? Take a look:
>>> flag = "🇺🇸"
>>> reversed_flag = flag[::-1]
>>> print(reversed_flag)
🇸🇺
What in the world is going on here?
Does "🇺🇸" Really Contain a Single Character?
When the conclusion of a valid argument is false, one of its premises must be false, too. Let's start from the top:
The flag string contains a single character.
Is that so? How can you tell how many characters a string has?
In Python, you can use the built-in len() function to get the total number of characters in a string:
>>> len("🇺🇸")
2
Oh.
That's weird. You can only see a single thing in the string "🇺🇸" — namely the US flag — but a length of 2 jives with the result of flag[::-1]. Since the reverse of "🇺🇸" is "🇸🇺", this seems to imply that somehow "🇺🇸" == "🇺 🇸".
How Can You Tell What Characters Are In a String?
There are a few different ways that you can see all of the true characters in a string using Python:
>>> # Convert a string to a list
>>> list("🇺🇸")
['🇺', '🇸']
>>> # Loop over each character and print
>>> for character in "🇺🇸":
... print(character)
...
🇺
🇸
The US flag emoji isn’t the only flag emoji with two characters:
>>> list("🇿🇼") # Zimbabwe
['🇿', '🇼']
>>> list("🇳🇴") # Norway
['🇳', '🇴']
>>> list("🇨🇺") # Cuba
['🇨', '🇺']
>>> # What do you notice?
And then there’s the Scottish flag:
>>> list("🏴")
['🏴', '\U000e0067', '\U000e0062', '\U000e0073', '\U000e0063',
'\U000e0074', '\U000e007f']
OK, what is that all about?
💪🏻 Challenge: Can you find any non-emoji strings that look like a single character but actually contain two or more characters?
The unnerving thing about these examples is that they imply that you can't tell what characters are in a string just by looking at your screen.
Or, perhaps more deeply, it makes you question your understanding of the term character.
What Is a Character, Anyway?
The term character in computer science can be confusing. It tends to get conflated with the word symbol , which, to be fair, is a synonym for the word character as it's used in English vernacular.
In fact, when I googled character computer science, the very first result I got was a link to a Technopedia article that defines a character as:
“[A] display unit of information equivalent to one alphabetic letter or symbol."
— Technopedia, “Character (Char)”
That definition seems off, especially in light of the US flag example that indicates that a single symbol may be comprised of at least two characters.
The second Google result I get is Wikipedia. In that article, the definition of a character is a bit more liberal:
”[A] character is a unit of information that roughly corresponds to a grapheme, grapheme-like unit, or symbol, such as in an alphabet or syllabary in the written form of a natural language.
— Wikipedia, "Character (computing)”
Hmm... using the word "roughly" in a definition makes the definition feel, shall I say, non-definitive.
But the Wikipedia article goes on to explain that the term character has been used historically to "denote a specific number of contiguous bits.”
Then, a significant clue to the question about how a string with one symbol can contain two or more characters:
“A character is most commonly assumed to refer to 8 bits (one byte) today... All [symbols] can be represented with one or more 8-bit code units with UTF-8.”
— Wikipedia, "Character (computing)”
OK! Maybe things are starting to make a little bit more sense. A character is one byte of information representing a unit of text. The symbols that we see in a string can be made up of multiple 8-bit (1 byte) UTF-8 code units.
Characters are not the same as symbols. It seems reasonable now that one symbol could be made up of multiple characters, just like flag emojis.
But what is a UTF-8 code unit?
A little further down the Wikipedia article on characters, there’s a section called Encoding that explains:
“Computers and communication equipment represent characters using a character encoding that assigns each character to something – an integer quantity represented by a sequence of digits, typically – that can be stored or transmitted through a network. Two examples of usual encodings are ASCII and the UTF-8 encoding for Unicode.”
— Wikipedia, "Character (computing)”
There’s another mention of UTF-8! But now I need to know what a character encoding is.
What Exactly Is a Character Encoding?
According to Wikipedia, a character encoding assigns each character to a number. What does that mean?
Doesn’t it mean that you can pair each character with a number? So, you could do something like pair each uppercase letter in the English alphabet with an integer 0 through 25.

You can represent this pairing using tuples in Python:
>>> pairs = [(0, "A"), (1, "B"), (2, "C"), ..., (25, "Z")]
>>> # I'm omitting several pairs here -----^^^
Stop for a moment and ask yourself: “Can I create a list of tuples like the one above without explicitly writing out each pair?"
One way is to use Python’s enumerate() function. enumerate() takes an argument called iterable and returns a tuple containing a count that defaults to 0 and the values obtained from iterating over iterable.
Here’s a look at enumerate() in action:
>>> letters = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
>>> enumerated_letters = list(enumerate(letters))
>>> enumerated_letters
[(0, 'A'), (1, 'B'), (2, 'C'), (3, 'D'), (4, 'E'), (5, 'F'), (6, 'G'),
(7, 'H'), (8, 'I'), (9, 'J'), (10, 'K'), (11, 'L'), (12, 'M'), (13, 'N'),
(14, 'O'), (15, 'P'), (16, 'Q'), (17, 'R'), (18, 'S'), (19, 'T'), (20, 'U'),
(21, 'V'), (22, 'W'), (23, 'X'), (24, 'Y'), (25, 'Z')]
There’s an easier way to make all of the letters, too.
Python’s string module has a variable called ascii_uppercase that points to a string containing all of the uppercase letters in the English alphabet:
>>> import string
>>> string.ascii_uppercase
'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
>>> enumerated_letters = list(enumerate(string.ascii_uppercase))
>>> enumerated_letters
[(0, 'A'), (1, 'B'), (2, 'C'), (3, 'D'), (4, 'E'), (5, 'F'), (6, 'G'),
(7, 'H'), (8, 'I'), (9, 'J'), (10, 'K'), (11, 'L'), (12, 'M'), (13, 'N'),
(14, 'O'), (15, 'P'), (16, 'Q'), (17, 'R'), (18, 'S'), (19, 'T'),
(20, 'U'), (21, 'V'), (22, 'W'), (23, 'X'), (24, 'Y'), (25, 'Z')]
OK, so we’ve associated characters to integers. That means we’ve got a character encoding!
But, how do you use it?
To encode the string ”PYTHON” as a sequence of integers, you need a way to look up the integer associated with each character. But, looking things up in a list of tuples is hard. It’s also really inefficient. (Why?)
Dictionaries are good for looking things up. If we convert enumerated_letters to a dictionary, we can quickly look up the letter associated with an integer:
>>> int_to_char = dict(enumerated_letters)
>>> # Get the character paired with 1
>>> int_to_char[1]
'B'
>>> # Get the character paired with 15
>>> int_to_char[15]
'P'
However, to encode the string ”PYTHON” you need to be able to look up the integer associated with a character. You need the reverse of int_to_char.
How do you swap keys and values in a Python dictionary?
One way is use the reversed() function to reverse key-value pairs from the int_to_char dictionary:
>>> # int_to_char.items() is a "list" of key-value pairs
>>> int_to_char.items()
dict_items([(0, 'A'), (1, 'B'), (2, 'C'), (3, 'D'), (4, 'E'), (5, 'F'),
(6, 'G'), (7, 'H'), (8, 'I'), (9, 'J'), (10, 'K'), (11, 'L'), (12, 'M'),
(13, 'N'), (14, 'O'), (15, 'P'), (16, 'Q'), (17, 'R'), (18, 'S'),
(19, 'T'), (20, 'U'), (21, 'V'), (22, 'W'), (23, 'X'), (24, 'Y'),
(25, 'Z')])
>>> # The reversed() function can reverse a tuple
>>> pair = (0, "A")
>>> tuple(reversed(pair))
('A', 0)
You can write a generator expression that reverses all of the pairs in int_to_char.items() and use that generator expression to populate a dictionary:
>>> char_to_int = dict(reversed(pair) for pair in int_to_char.items())
>>> # Reverse the pair-^^^^^^^^^^^^^^
>>> # For every key-value pair--------^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
>>> # Get the integer associated with B
>>> char_to_int["B"]
1
>>> # Get the integer associated with P
>>> char_to_int["P"]
15
It’s good that you paired each letter with a unique integer. Otherwise, this dictionary reversal wouldn’t have worked. (Why?)
Now you can encode strings as list of integers using the char_to_int dictionary and a list comprehension:
>>> [char_to_int[char] for char in "PYTHON"]
[15, 24, 19, 7, 14, 13]
And you can convert a list of integers into a string of uppercase characters using int_to_char in a generator expression with Python's string .join() method:
>>> "".join(int_to_char[num] for num in [7, 4, 11, 11, 14])
'HELLO'
But, there’s a problem.
Your encoding can’t handle strings with things like punctuation, lowercase letters, and whitespace:
>>> [char_to_int[char] for char in "monty python!"]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<stdin>", line 1, in <listcomp>
KeyError: 'm'
>>> # ^^^^^^^-----char_to_int has no "m" key
One way to fix this is to create an encoding using a string containing all of the lowercase letters, punctuation marks, and whitespace characters that you need.
But, in Python, there’s almost always a better way. Python’s string module contains a variable called printable that gives you a string containing a whole bunch of printable characters:
>>> string.printable
'0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~ \t\n\r\x0b\x0c'
Would you have included all of those characters if you were making your own string from scratch?
Now you can make new dictionaries for encoding and decoding the characters in string.printable:
>>> int_to_printable = dict(enumerate(string.printable))
>>> printable_to_int = dict(reversed(item) for item in int_to_printable.items())
You can use these dictionaries to encode and decode more complicated strings:
>>> # Encode the string "monty python!"
>>> encoded_string = [printable_to_int[char] for char in "monty python!"]
>>> encoded_string
[22, 24, 23, 29, 34, 94, 25, 34, 29, 17, 24, 23, 62]
>>> # Decode the encoded string
>>> decoded_string = "".join(int_to_printable[num] for num in encoded_string)
>>> decoded_string
'monty python!'
You’ve now made two different character encodings! And they really are different. Just look at what happens when you decode the same list of integers using both encodings:
>>> encoded_string = [15, 24, 19, 7, 14, 13]
>>> # Decode using int_to_char (string.ascii_uppercase)
>>> "".join(int_to_char[num] for num in encoded_string)
'PYTHON'
>>> # Decode using int_to_printable(string.printable)
>>> "".join(int_to_printable[num] for num in encoded_string)
'foj7ed'
Not even close!
So, now we know a few things about character encodings:
- A character encoding pairs characters with unique integers.
- Some character encodings exclude characters that are included in other character encodings.
- Two different character encodings may decode the same integers into two different strings.
What does any of this have to do with UTF-8?
What Is UTF-8?
Wikipedia's article on characters mentions two different character encodings:
“Two examples of usual encodings are ASCII and the UTF-8 encoding for Unicode.”
— Wikipedia, "Character (computing)”
OK, so ASCII and UTF-8 are specific kinds of character encoding.
According to the Wikipedia article on ASCII:
ASCII was the most common character encoding on the World Wide Web until December 2007, when UTF-8 encoding surpassed it; UTF-8 is backward compatible with ASCII.
— Wikipedia, "ASCII”
UTF-8 isn’t just the dominant character encoding for the web. It’s also the primary character encoding for Linux and macOS operating systems and is even the default for Python code.
In fact, you can see how UTF-8 encodes characters as integers using the .encode() method on Python string objects. But .encode() doesn't return a list of integers. Instead, encode() returns a bytes object:
>>> encoded_string = "PYTHON".encode()
>>> # The encoded string *looks* like a string still,
>>> # but notice the b in front of the first quote
>>> encoded_string
b'PYTHON'
>>> # b stands for bytes, which is the type of
>>> # object returned by .encode()
>>> type(encoded_string)
<class 'bytes'>
The Python docs describe a bytes object as “an immutable sequence of integers in the range 0 <= x < 256.” That seems a little weird considering that the encoded_string object displays the characters in the string “PYTHON” and not a bunch of integers.
But let’s accept this and see if we can tease out the integers somehow.
The Python docs say that bytes is a "sequence," and Python's glossary defines a sequence as “[a]n iterable which supports efficient element access using integer indices.”
So, it sounds like you can index a bytes object the same way that you can index a Python list object. Let's try it out:
>>> encoded_string[0]
80
Aha!
What happens when you convert encoded_string to a list?
>>> list(encoded_string)
[80, 89, 84, 72, 79, 78]
Bingo. It looks like UTF-8 assigns the letter ”P” to the integer 80, ”Y” to the integer 89, ”T” to the integer 84, and so on.
Let’s see what happens when we encode the string ”🇺🇸” using UTF-8:
>>> list("🇺🇸".encode())
[240, 159, 135, 186, 240, 159, 135, 184]
Huh. Did you expect ”🇺🇸” to get encoded as eight integers?
”🇺🇸” is made up of two characters, namely “🇺” and ”🇸". Let's see how those get encoded:
>>> list("🇺".encode())
[240, 159, 135, 186]
>>> list("🇸".encode())
[240, 159, 135, 184]
OK, things are making more sense now. Both “🇺” and ”🇸" get encoded as four integers, and the four integers corresponding to “🇺” appear first in the list of integers corresponding to ”🇺🇸”, while the four integers corresponding to ”🇸" appear second.
This raises a question, though.
Why Does UTF-8 Encode Some Characters As Four Integers and Others as One Integer?
The character “🇺” is encoded as a sequence of four integers in UTF-8, while the character ”P” gets encoded as a single integer. Why is that?
There’s a hint at the top of Wikipedia’s UTF-8 article:
UTF-8 is capable of encoding all 1,112,064 valid character code points in Unicode using one to four one-byte (8-bit) code units. Code points with lower numerical values, which tend to occur more frequently, are encoded using fewer bytes.
— Wikipedia, “UTF-8”
OK, so that makes it sound like UTF-8 isn’t encoding characters to integers, but instead to something called a Unicode code point. And each code unit can apparently be one to four bytes.
There are a couple of questions we need to answer now:
- What is a byte?
- What is a Unicode code point?
The word byte has been floating around a lot, so let’s go ahead and give it a proper definition.
A bit is the smallest unit of information. A bit has two states, on or off, that are usually represented by the integers 0 and 1, respectively. A byte is a sequence of eight bits.
You can interpret bytes as integers by viewing their component bits as expressing a number in binary notation.
Binary notation can look pretty exotic the first time you see it. It's a lot like the usual decimal representation you use to write numbers, though. The difference is that each digit can only be a 0 or a 1, and the value of each place in the number is a power of 2, not a power of 10:

Since a byte contains eight bits, the largest number you can represent with a single byte is 11111111 in binary or 255 in decimal notation.
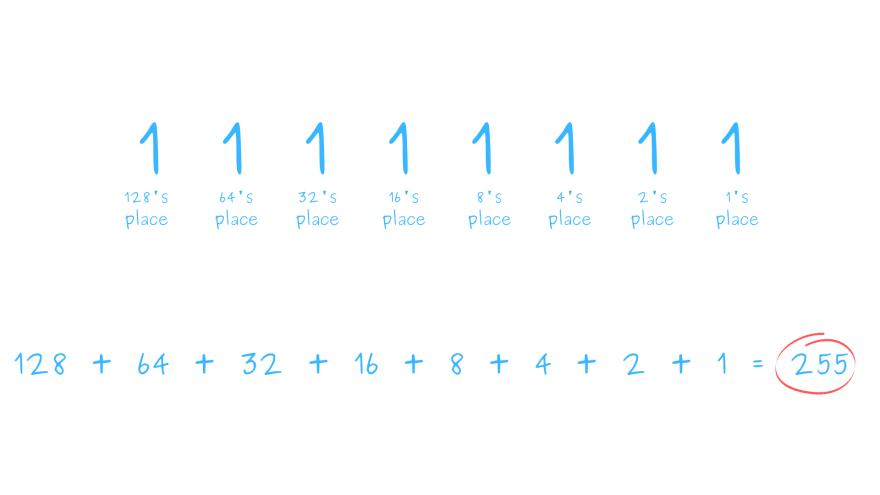
A character encoding that uses one byte for each character can encode a maximum of 255 characters since the maximum 8-bit integer is 255.
255 characters might be enough to encode everything in the English language. Still, there’s no way that it can handle all of the characters and symbols used in written and electronic communication worldwide.
So what do you do? Allowing characters to be encoded as multiple bytes seems like a reasonable solution, and that’s exactly what UTF-8 does.
UTF-8 is an acronym for Unicode Transformation Format — 8-bit. There's that word Unicode again.
According to the Unicode website:
“Unicode provides a unique number for every character, no matter what the platform, no matter what the program, no matter what the language.”
— Unicode website, “What is Unicode?”
Unicode is massive. The goal of Unicode is to provide a universal representation for all written language. Every character gets assigned to a code point — a fancy word for “integer" with some additional organization — and there are a total of 1,112,064 possible code points.
How Unicode code points actually get encoded depends, though. UTF-8 is just one character encoding implementing the Unicode standard. It divides code points into groups of one to four 8-bit integers.
There are other encodings for Unicode. UTF-16 divides Unicode code points into one or two 16-bit numbers and is the default encoding used by Microsoft Windows. UTF-32 can encode every Unicode code point as a single 21-bit integer.
But wait, UTF-8 encodes symbols as code points using one to four bytes. OK, so… why does the 🇺🇸 symbol get encoded with eight bytes?
>>> list("🇺🇸".encode())
[240, 159, 135, 186, 240, 159, 135, 184]
>>> # There are eight integers in the list, a total of eight bytes!
Remember, two characters make up the US flag emoji: 🇺 and 🇸. These characters are called regional indicator symbols. There are twenty-six regional indicators in the Unicode standard representing A–Z English letters. They’re used to encode ISO 3166-1 two-letter country codes.
Here’s what Wikipedia has to say about regional indicator symbols:
These were defined in October 2010 as part of the Unicode 6.0 support for emoji, as an alternative to encoding separate characters for each country flag. Although they can be displayed as Roman letters, it is intended that implementations may choose to display them in other ways, such as by using national flags. The Unicode FAQ indicates that this mechanism should be used and that symbols for national flags will not be directly encoded.
— Wikipedia, “Regional indicator symbol”
In other words, the 🇺🇸 symbol — indeed, the symbol for any country's flag — is not directly supported by Unicode. Operating systems, web browsers, and other places where digital text is used, may choose to render pairs of regional indicators as flags.
Let’s take stock of what we know so far:
- Strings of symbols get converted to sequences of integers by a character encoding, usually UTF-8.
- Some characters are encoded as a single 8-bit integer by UTF-8, and others require two, three, or four 8-bit integers.
- Some symbols, such as flag emojis, are not directly encoded by Unicode. Instead, they are renders of sequences of Unicode characters and may or may not be supported by every platform.
So, when you reverse a string, what gets reversed? Do you reverse the entire sequence of integers in the encoding, or do you reverse the order of the code points, or something different?
How Do You Actually Reverse A String?
Can you think of a way to answer this question with a code experiment rather than trying to look up the answer?
You saw earlier that UTF-8 encodes the string ”PYTHON” as a sequence of six integers:
>>> list("PYTHON".encode())
[80, 89, 84, 72, 79, 78]
What happens if you encode the reversal of the string ”PYTHON”?
>>> list("PYTHON"[::-1].encode())
[78, 79, 72, 84, 89, 80]
In this case, the order of the integers in the list was reversed. But what about other symbols?
Earlier, you saw that the “🇺" symbol is encoded as a sequence of four integers. What happens when you encode its reversal?
>>> list("🇺".encode())
[240, 159, 135, 186]
>>> list("🇺"[::-1].encode())
[240, 159, 135, 186]
Huh. The order of the integers in both lists is the same!
Let’s try reversing the string with the US flag:
>>> list("🇺🇸".encode())
[240, 159, 135, 186, 240, 159, 135, 184]
>>> # ^^^^^^^^^^^^^^---Code point for 🇺
>>> # ^^^^^^^^^^^^^^^^^^---Code point for 🇸
>>> # The code points get swapped!
>>> list("🇺🇸"[::-1].encode())
[240, 159, 135, 184, 240, 159, 135, 186]
>>> # ^^^^^^^^^^^^^^---Code point for 🇸
>>> # ^^^^^^^^^^^^^^^^^^---Code point for 🇺
The order of the integers isn’t reversed! Instead, the groups of four integers representing the Unicode code points for 🇺and 🇸get swapped. The orders of the integers in each code point stay the same.
What Does All Of This Mean?
The title of this article is a lie! You can reverse a string with a flag emoji. But the reversing symbols composed of multiple code points can have surprising results. Especially if you've never heard of things like character encodings and code points before.
Why Is Any Of This Important?
There are a couple of important lessons to take away from this investigation.
First, if you don't know which character encoding was used to encode some text, you can't guarantee that the decoded text accurately represents the original text.
Second, although UTF-8 is widely adopted, there are still many systems that use different character encodings. Keep this in mind when reading text from a file, especially when shared from a different operating system or across international borders. Be explicit and always indicate which encoding is being used to encode or decode text.
For example, Python’s open() function has an encoding parameter that specifies the character encoding to use when reading or writing text to a file. Make use of it.
Where Do You Go From Here?
We’ve covered a lot of ground, but there are still a lot of questions left unanswered. So write down some of the questions you still have and use the investigative techniques you saw in this article to try and answer them.
💡 This article was inspired by a question posed by Will McGugan on Twitter. Check out Will's thread for a whole bunch of characacter encoding craziness.
Here are some questions you might want to explore:
- When you convert
”🏴”to a list, you end up with a bunch of strings that start with”\U”. What are those strings, and what do they represent? - The UTF-8 encoding for
”🏴”contains a whopping 28 bytes of information. What makes 🏴 different from 🇺🇸? What other flags get encoded as 28 bytes? - Are there any flag emojis that get encoded as a single code point?
- Many platforms support colored emojis, such as a thumbs-up emoji that can be rendered with different skin tones. How does the same symbol with different colors get encoded?
- How can you check if a string containing emojis is a palindrome?
Thanks for reading! Stay curious out there!
Join my free weekly newsletter "Curious About Code" to get curiosity-inducing content in your inbox every Friday.

Top comments (0)