I recently undertook Forrest Brazeal's second cloud challenge, after being one of the participants in his first "Cloud Resume" challenge.
The Challenge
The challenge can be found here. The main steps are as follows;
- Create a once-daily event to run a compute task
- Create a compute job that will extract data from NYTimes' public COVID repo
- Create a compute job that can convert the date in the previous step to a Date object, and join that data with the recovered data from John Hopkins repo
- Package the above compute jobs into a Python module
- Create a Python compute job that loads the above data into a database of my choice
- Create a notification system to report success/failure of the compute jobs
- Integrate error handling for common loading/updating data issues
- Integrate a Python unit testing system to test changes to the code
- Package the entire challenge into a IaC template, using a platform of my choice
- Integrate source control for my project
- Create a dashboard to visualize my transformed data
My Approach
I decided to tackle all of the compute-job-steps together, as one. I essentially created the ETL Python module first, testing that my code could, in fact, extract and transform public data. Once my Python was working as intended, I could easily set up a Lambda job to run and test this module. I also integrated source control at the beginning; I had to go through several re-writes of my scripts, and GitHub helped me keep track of those changes. Speaking of which, my final code and IaC template can be found here.
As seen in the provided GitHub repo, I chose to use SAM as my IaC platform. I initially was going to use SAM's parent, CloudFormation, but I had more familiarity with SAM resources from Forrest's previous challenge, and I had chosen to use DynamoDB as my database solution. I chose to use SAM to maintain flexibility with my IaC, as well as keep up the serverless theme of my project. Using SAM (and technically CloudFormation), I was able to fully automate deployment of my Lambda, DynamoDB, SNS (for the notification system), and all the respective permissions needed between these resources (following the principle of allowing least-privilege, of course).
The dashboard proved to be much more complex than I initially thought. I chose to use AWS QuickSight to visualize my data, which does not explicitly support reading from DynamoDB. Instead, I had to find a way to export data to a QuickSight-compatible format, and load it from there. I ended up just using the AWS CLI to download and write my DynamoDB table to a local .csv file, and manually upload it into QuickSight. In the future, I plan to utilize AWS Data Pipeline to automate exporting my DynamoDB table to an S3 bucket, which QuickSight will then pull and visualize data from. I chose Data Pipeline for this concept because it is an AWS resource (meaning I can add it into my SAM template), and it can be added to the once-daily CloudWatch rule I have extracting the data, maintaining full automation.
Conclusion and Results
Visualizing data has been a lot more fun than I was expecting, to be perfectly honest. Conceptually, it did not sound like it would be the most enjoyable experience, but building a full solution to extracting and analyzing data proved to be quite fulfilling.
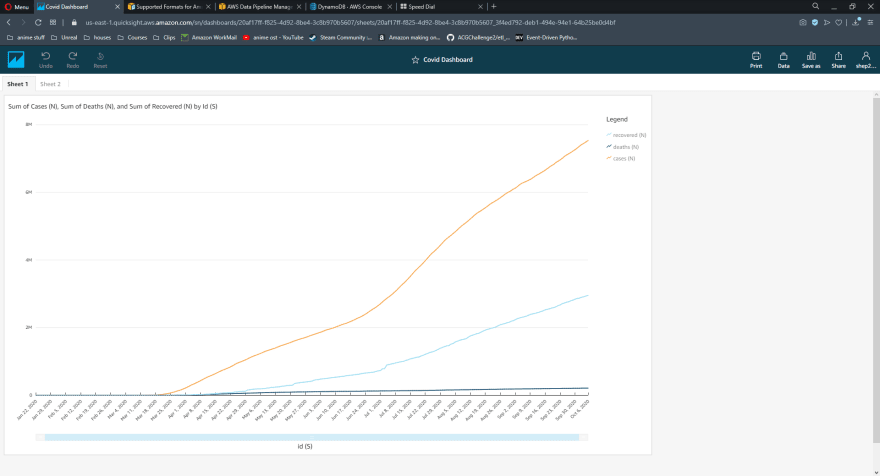

I really enjoyed this challenge from ACloudGuru's Forrest Brazeal! I was actually learning skills that are directly relevant to a role in the cloud/data industry, and I can't thank ACG and Forrest enough for providing these challenges.. I will definitely continue to complete ACG's monthly challenges to further my abilities in the cloud industry!
-Orrin Sheppard





Top comments (0)