
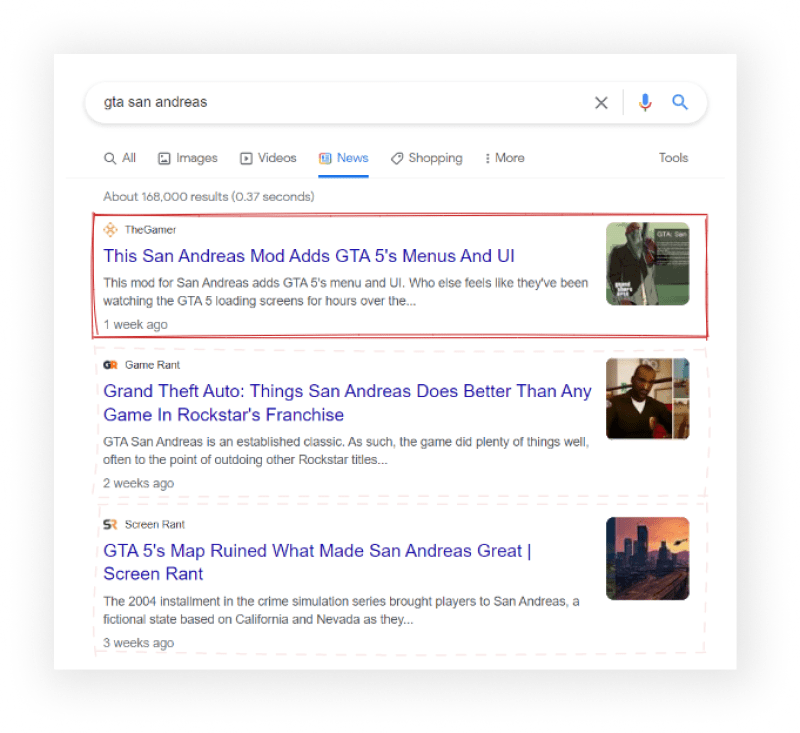
What will be scraped
Prerequisites (could be skipped)
Install libraries:
pip install requests bs4 google-search-results
google-search-results is a SerpApi API package.
Basic knowledge scraping with CSS selectors
CSS selectors declare which part of the markup a style applies to thus allowing to extract data from matching tags and attributes.
If you haven't scraped with CSS selectors, there's a dedicated blog post of mine
about how to use CSS selectors when web-scraping that covers what it is, its pros and cons, and why they matter from a web-scraping perspective.
Separate virtual environment
In short, it's a thing that creates an independent set of installed libraries including different Python versions that can coexist with each other in the same system thus preventing libraries or Python version conflicts.
If you didn't work with a virtual environment before, have a look at the
dedicated Python virtual environments tutorial using Virtualenv and Poetry blog post of mine to get a little bit more familiar.
📌Note: this is not a strict requirement for this blog post.
Reduce the chance of being blocked
There's a chance that a request might be blocked. Have a look
at how to reduce the chance of being blocked while web-scraping, there are eleven methods to bypass blocks from most websites.
Make sure to pass User-Agent, because Google might block your requests eventually and you'll receive a different HTML thus empty output.
User-Agent identifies the browser, its version number, and its host operating system that represents a person (browser) in a Web context that lets servers and network peers identify if it's a bot or not. And we're faking "real" user visit. Check what is your user-agent.
Full Code
import requests, json, re
from parsel import Selector
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.114 Safari/537.36"
}
params = {
"q": "gta san andreas", # search query
"hl": "en", # language of the search
"gl": "us", # country of the search
"num": "100", # number of search results per page
"tbm": "nws" # news results
}
html = requests.get("https://www.google.com/search", headers=headers, params=params, timeout=30)
selector = Selector(text=html.text)
news_results = []
# extract thumbnails
all_script_tags = selector.css("script::text").getall()
for result, thumbnail_id in zip(selector.css(".xuvV6b"), selector.css(".FAkayc img::attr(id)")):
thumbnails = re.findall(r"s=\'([^']+)\'\;var\s?ii\=\['{_id}'\];".format(_id=thumbnail_id.get()), str(all_script_tags))
decoded_thumbnail = "".join([
bytes(bytes(img, "ascii").decode("unicode-escape"), "ascii").decode("unicode-escape") for img in thumbnails
])
news_results.append(
{
"title": result.css(".MBeuO::text").get(),
"link": result.css("a.WlydOe::attr(href)").get(),
"source": result.css(".NUnG9d span::text").get(),
"snippet": result.css(".GI74Re::text").get(),
"date_published": result.css(".ZE0LJd span::text").get(),
"thumbnail": None if decoded_thumbnail == "" else decoded_thumbnail
}
)
print(json.dumps(news_results, indent=2, ensure_ascii=False))
Code Explanation
Import libraries:
import requests, json, re
from parsel import Selector
| Library | Purpose |
|---|---|
requests |
to make a request to the website. |
json |
to convert extracted data to a JSON object. |
re |
to extract parts of the data via regular expression. |
parsel |
to parse data from HTML/XML documents. Similar to BeautifulSoup but supports XPath. |
Create request headers and URL parameters:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.114 Safari/537.36"
}
params = {
"q": "gta san andreas", # search query
"hl": "en", # language of the search
"gl": "us", # country of the search
"num": "100", # number of search results per page
"tbm": "nws" # news results
}
| Code | Explanation |
|---|---|
params |
a prettier way of passing URL parameters to a request. |
user-agent |
to act as a "real" user request from the browser by passing it to request headers. Default requests user-agent is a python-reqeusts so websites might understand that it's a bot or a script and block the request to the website. Check what's your user-agent. |
Make a request, pass created request parameters and headers. Pass returned HTML to parsel:
html = requests.get("https://www.google.com/search", headers=headers, params=params, timeout=30)
selector = Selector(text=html.text)
| Code | Explanation |
|---|---|
timeout=30 |
to stop waiting for response after 30 seconds. |
Selector(text=html.text) |
where passed HTML from the response will be processed by parsel. |
Create an empty list to store extracted news results:
news_results = []
Create a variable that will hold store <script> tags from the page:
all_script_tags = selector.css("script::text").getall()
| Code | Explanation |
|---|---|
css() |
is a parsel method that extracts nodes based on a given CSS selector(s). |
::text |
is a parsel own pseudo-element support that extracts textual data, which will translate every CSS query to XPath. In this case ::text would become /text() if using XPath directly. |
getall() |
returns a list of matched nodes. |
Iterate over news results and extract thumbnails data (skip to the next step if you don't want thumbnails):
for result, thumbnail_id in zip(selector.css(".xuvV6b"), selector.css(".FAkayc img::attr(id)")):
thumbnails = re.findall(r"s=\'([^']+)\'\;var\s?ii\=\['{_id}'\];".format(_id=thumbnail_id.get()), str(all_script_tags))
decoded_thumbnail = "".join([
bytes(bytes(img, "ascii").decode("unicode-escape"), "ascii").decode("unicode-escape") for img in thumbnails
])
| Code | Explanation |
|---|---|
zip() |
iterate over several iterables in parallel. In this case zip is used to also extract thumbnails that are located in the <script> tags. |
::attr(id) |
parsel own pseudo-element support that will extract given attribute from an HTML node. |
re.findall() |
match parts of the data from HTML using regular expression pattern. In this case, we want to match thumbnails. If you parse thumbnails directly from the HTML, you'll get a 1x1 image placeholder, not thumbnail. findall returns a list of matches. |
format(_id=thumbnail_id.get()) |
format is a Python string format that insert passed values inside the string's placeholder, which is _id in this case: \['{_id}'\];
|
str(all_script_tags) |
used to type cast returned value to a string type. |
"".join() |
join all items into a single string. Since this example uses list comprehension, the returned output would be a list of each processed element: [thumbnail_1] [thumbnail_2] [thumbnail_3] or [] if empty. join will list to str
|
bytes(img, "ascii").decode("unicode-escape") |
to decode parsed image data. |
Append extracted results to a temporary list as a dict:
news_results.append(
{
"title": result.css(".MBeuO::text").get(),
"link": result.css("a.WlydOe::attr(href)").get(),
"source": result.css(".NUnG9d span::text").get(),
"snippet": result.css(".GI74Re::text").get(),
"date_published": result.css(".ZE0LJd span::text").get(),
"thumbnail": None if decoded_thumbnail == "" else decoded_thumbnail
}
)
Print extracted data:
print(json.dumps(news_results, indent=2, ensure_ascii=False))
Full Pagination Code
The only difference is that we adding:
- `while` loop to iterate over all pages.
- `if` statement to check for the `"Next"` presense.
- increments `params["start"]` parameter by `10` to paginate to the next page.
```python
import requests, json, re
from parsel import Selector
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.114 Safari/537.36"
}
params = {
"q": "gta san andreas", # search query
"hl": "en", # language of the search
"gl": "us", # country of the search
"num": "100", # number of search results per page
"tbm": "nws", # news results
"start": 0 # page nubmer
}
news_results = []
page_num = 0
while True:
page_num += 1
print(page_num)
html = requests.get("https://www.google.com/search", headers=headers, params=params, timeout=30)
selector = Selector(text=html.text)
# extract thumbnails
all_script_tags = selector.css("script::text").getall()
for result, thumbnail_id in zip(selector.css(".xuvV6b"), selector.css(".FAkayc img::attr(id)")):
thumbnails = re.findall(r"s=\'([^']+)\'\;var\s?ii\=\['{_id}'\];".format(_id=thumbnail_id.get()), str(all_script_tags))
decoded_thumbnail = "".join([
bytes(bytes(img, "ascii").decode("unicode-escape"), "ascii").decode("unicode-escape") for img in thumbnails
])
news_results.append(
{
"title": result.css(".MBeuO::text").get(),
"link": result.css("a.WlydOe::attr(href)").get(),
"source": result.css(".NUnG9d span::text").get(),
"snippet": result.css(".GI74Re::text").get(),
"date_published": result.css(".ZE0LJd span::text").get(),
"thumbnail": None if decoded_thumbnail == "" else decoded_thumbnail
}
)
if selector.css(".d6cvqb a[id=pnnext]").get():
params["start"] += 10
else:
break
print(json.dumps(news_results, indent=2, ensure_ascii=False))
```
### Using [Google News Result API](https://serpapi.com/news-results)
The main difference is that it's a quicker approach if you don't want to create the parser from scratch and maintain it over time or figure out how to scale the number of requests without being blocked.
Basic Hello World example:
```python
from serpapi import GoogleSearch
import json
params = {
"api_key": "YOUR_API_KEY", # your serpapi api key
"engine": "google", # serpapi parsing engine
"q": "gta san andreas", # search query
"gl": "us", # country from where search comes from
"tbm": "nws" # news results
# other parameters such as language `hl` and number of news results `num`, etc.
}
search = GoogleSearch(params) # where data extraction happens on the backend
results = search.get_dict() # JSON - > Python dictionary
for result in results["news_results"]:
print(json.dumps(results, indent=2))
```
Outputs:
```json
{
"position":1,
"link":"https://www.sportskeeda.com/gta/5-strange-gta-san-andreas-glitches",
"title":"5 strange GTA San Andreas glitches",
"source":"Sportskeeda",
"date":"9 hours ago",
"snippet": "GTA San Andreas has a wide assortment of interesting and strange glitches.",
"thumbnail":"https://serpapi.com/searches/60e71e1f8b7ed2dfbde7629b/images/1394ee64917c752bdbe711e1e56e90b20906b4761045c01a2cefb327f91d40bb.jpeg"
}
```
### Google News Results API with Pagination
If there's a need to extract all results from all pages, SerpApi has a great Python [`pagination()`](https://github.com/serpapi/google-search-results-python#pagination-using-iterator) method that iterates over all pages under the hood and returns an iterator:
```python
# https://github.com/serpapi/google-search-results-python
from serpapi import GoogleSearch
import json
params = {
"api_key": "YOUR_API_KEY", # your serpapi api key
"engine": "google", # serpapi parsing engine
"q": "coca cola", # search query
"tbm": "nws" # news results
}
search = GoogleSearch(params) # where data extraction happens
pages = search.pagination() # returns an iterator of all pages
for page in pages:
print(f"Current page: {page['serpapi_pagination']['current']}")
for result in page["news_results"]:
print(f"Title: {result['title']}\nLink: {result['link']}\n")
```
Outputs:
```lang-none
Current page: 1
Title: PepsiCo's Many Troubles Now Have Me Focused on Coca-Cola
Link: https://realmoney.thestreet.com/investing/pepsico-s-many-troubles-now-have-me-focused-on-coca-cola-16050336
...
Current page: 26
Title: What You Can Learn About NFTs From Coca-Cola, Acura, and ...
Link: https://www.entrepreneur.com/article/425166
```
Links
Add a Feature Request💫 or a Bug🐞

Top comments (0)