Intro
This blog post is created to show you how SerpApi was integrated into this small app with an explanation of how the app functionates and SerpApi's role in it.
The main idea comes from a tool called Zik Analytics, which used by dropshippers.
This demo shows a comparison between Walmart and eBay products to determine profit. The user selects a product and a place of sale, and the program finds the same product in another place and calculates the profit.
App Demo
📌Note: Use the dark Streamlit theme to view the table normally.
Virtual Environment and Libraries Installation
If you want to use your own API key, follow these steps:
- Clone repository:
$ git clone https://github.com/chukhraiartur/dropshipping-tool-demo.git
- Install dependencies:
$ cd dropshipping-tool-demo && pip install -r requriements.txt
- Add SerpApi api key for current shell and all processes started from current shell:
# used to parse Walmart and eBay results, has a plan of 100 free searches
$ export SERPAPI_API_KEY=<your-api-key>
- Run the app:
$ streamlit run main.py
Full Code
from serpapi import EbaySearch, WalmartSearch
import streamlit as st
import streamlit.components.v1 as components
import pandas as pd
import time, os, Levenshtein
def get_walmart_results(query: str):
params = {
'api_key': os.getenv('SERPAPI_API_KEY'), # https://serpapi.com/manage-api-key
'engine': 'walmart', # search engine
'query': query, # search query
}
search = WalmartSearch(params) # data extraction on the SerpApi backend
results = search.get_dict() # JSON -> Python dict
return results.get('organic_results', [])
def get_ebay_results(query: str):
params = {
'api_key': os.getenv('SERPAPI_API_KEY'), # https://serpapi.com/manage-api-key
'engine': 'ebay', # search engine
'_nkw': query, # search query
'ebay_domain': 'ebay.com', # ebay domain
}
search = EbaySearch(params) # data extraction on the SerpApi backend
results = search.get_dict() # JSON -> Python dict
return results.get('organic_results', [])
def compare_walmart_with_ebay(query: str, number_of_products: int, percentage_of_uniqueness: float):
data = []
walmart_results = get_walmart_results(query)
for walmart_result in walmart_results[:number_of_products]:
ebay_results = get_ebay_results(walmart_result['title'])
for ebay_result in ebay_results:
if Levenshtein.ratio(walmart_result['title'], ebay_result['title']) < percentage_of_uniqueness:
continue
walmart_price = walmart_result.get('primary_offer', {}).get('offer_price')
ebay_price = ebay_result.get('price', {}).get('extracted')
if not ebay_price:
ebay_price = ebay_result.get('price', {}).get('from', {}).get('extracted')
profit = 0
if walmart_price and ebay_price:
profit = round(walmart_price - ebay_price, 2)
data.append({
'Walmart': {
'thumbnail': walmart_result['thumbnail'],
'title': walmart_result['title'],
'link': walmart_result['product_page_url'],
'price': walmart_price
},
'eBay': {
'thumbnail': ebay_result['thumbnail'],
'title': ebay_result['title'],
'link': ebay_result['link'],
'price': ebay_price
},
'Profit': profit
})
return data
def compare_ebay_with_walmart(query: str, number_of_products: int, percentage_of_uniqueness: float):
data = []
ebay_results = get_ebay_results(query)
for ebay_result in ebay_results[:number_of_products]:
walmart_results = get_walmart_results(ebay_result['title'])
for walmart_result in walmart_results:
if Levenshtein.ratio(ebay_result['title'], walmart_result['title']) < percentage_of_uniqueness:
continue
ebay_price = ebay_result.get('price', {}).get('extracted')
walmart_price = walmart_result.get('primary_offer', {}).get('offer_price')
if not ebay_price:
ebay_price = ebay_result.get('price', {}).get('from', {}).get('extracted')
profit = 0
if ebay_price and walmart_price:
profit = round(ebay_price - walmart_price, 2)
data.append({
'eBay': {
'thumbnail': ebay_result['thumbnail'],
'title': ebay_result['title'],
'link': ebay_result['link'],
'price': ebay_price
},
'Walmart': {
'thumbnail': walmart_result['thumbnail'],
'title': walmart_result['title'],
'link': walmart_result['product_page_url'],
'price': walmart_price
},
'Profit': profit
})
return data
def create_table(data: list, where_to_sell: str):
with open('table_style.css') as file:
style = file.read()
products = ''
for product in data:
profit_color = 'lime' if product['Profit'] >= 0 else 'red'
if where_to_sell == 'Walmart':
products += f'''
<tr>
<td><div><img src="{product['Walmart']['thumbnail']}" width="50"></div></td>
<td><div><a href="{product['Walmart']['link']}" target="_blank">{product['Walmart']['title']}</div></td>
<td><div>{str(product['Walmart']['price'])}$</div></td>
<td><div><img src="{product['eBay']['thumbnail']}" width="50"></div></td>
<td><div><a href="{product['eBay']['link']}" target="_blank">{product['eBay']['title']}</div></td>
<td><div>{str(product['eBay']['price'])}$</div></td>
<td><div style="color:{profit_color}">{str(product['Profit'])}$</div></td>
</tr>
'''
elif where_to_sell == 'eBay':
products += f'''
<tr>
<td><div><img src="{product['eBay']['thumbnail']}" width="50"></div></td>
<td><div><a href="{product['eBay']['link']}" target="_blank">{product['eBay']['title']}</div></td>
<td><div>{str(product['eBay']['price'])}$</div></td>
<td><div><img src="{product['Walmart']['thumbnail']}" width="50"></div></td>
<td><div><a href="{product['Walmart']['link']}" target="_blank">{product['Walmart']['title']}</div></td>
<td><div>{str(product['Walmart']['price'])}$</div></td>
<td><div style="color:{profit_color}">{str(product['Profit'])}$</div></td>
</tr>
'''
table = f'''
<style>
{style}
</style>
<table border="1">
<thead>
<tr>
<th colspan="3"><div>{list(data[0].keys())[0]}</div></th>
<th colspan="3"><div>{list(data[0].keys())[1]}</div></th>
<th><div>{list(data[0].keys())[2]}</div></th>
</tr>
</thead>
<tbody>{products}</tbody>
</table>
'''
return table
def save_to_json(data: list):
json_file = pd.DataFrame(data=data).to_json(index=False, orient='table')
st.download_button(
label='Download JSON',
file_name='comparison-results.json',
mime='application/json',
data=json_file,
)
def save_to_csv(data: list):
csv_file = pd.DataFrame(data=data).to_csv(index=False)
st.download_button(
label="Download CSV",
file_name='comparison-results.csv',
mime='text/csv',
data=csv_file
)
def main():
st.title('💸Product Comparison')
st.markdown(body='This demo compares products from Walmart and eBay to find a profit. SerpApi Demo Project ([repository](https://github.com/chukhraiartur/dropshipping-tool-demo)). Made with [Streamlit](https://streamlit.io/) and [SerpApi](http://serpapi.com/) 🧡')
if 'visibility' not in st.session_state:
st.session_state.visibility = 'visible'
st.session_state.disabled = False
SEARCH_QUERY: str = st.text_input(
label='Search query',
placeholder='Search',
help='Multiple search queries is not supported.'
)
WHERE_TO_SELL = st.selectbox(
label='Where to sell',
options=('Walmart', 'eBay'),
help='Select the platform where you want to sell products. The program will look for the same products on another site and calculate the profit.'
)
NUMBER_OF_PRODUCTS: int = st.slider(
label='Number of products to search',
min_value=1,
max_value=20,
value=10,
help='Limit the number of products to analyze.'
)
PERCENTAGE_OF_UNIQUENESS: int = st.slider(
label='Percentage of uniqueness',
min_value=1,
max_value=100,
value=50,
help='The percentage of uniqueness is used to compare how similar one title is to another. The higher this parameter, the more accurate the result.'
)
SAVE_OPTION = st.selectbox(
label='Choose file format to save',
options=(None, 'JSON', 'CSV'),
help='By default data won\'t be saved. Choose JSON or CSV format if you want to save the results.'
)
col1, col2, col3, col4, col5 = st.columns(5)
with col3:
submit_button_holder = st.empty()
submit_search = submit_button_holder.button(label='Compare products')
if submit_search and not SEARCH_QUERY:
st.error(body='Looks like you click a button without a search query. Please enter a search query 👆')
st.stop()
if submit_search and SEARCH_QUERY and WHERE_TO_SELL:
with st.spinner(text='Parsing Product Data...'):
comparison_results = []
if WHERE_TO_SELL == 'Walmart':
comparison_results = compare_walmart_with_ebay(SEARCH_QUERY, NUMBER_OF_PRODUCTS, PERCENTAGE_OF_UNIQUENESS/100)
elif WHERE_TO_SELL == 'eBay':
comparison_results = compare_ebay_with_walmart(SEARCH_QUERY, NUMBER_OF_PRODUCTS, PERCENTAGE_OF_UNIQUENESS/100)
parsing_is_success = st.success('Done parsing 🎉')
time.sleep(1)
parsing_is_success.empty()
submit_button_holder.empty()
comparison_results_header = st.markdown(body='#### Comparison results')
if comparison_results:
table = create_table(comparison_results, WHERE_TO_SELL)
components.html(table, height=len(comparison_results)*62 + 40)
time.sleep(1)
with col3:
start_over_button_holder = st.empty()
start_over_button = st.button(label='Start over') # centered button
if SAVE_OPTION and comparison_results:
with st.spinner(text=f'Saving data to {SAVE_OPTION}...'):
if SAVE_OPTION == 'JSON':
save_to_json(comparison_results)
elif SAVE_OPTION == 'CSV':
save_to_csv(comparison_results)
saving_is_success = st.success('Done saving 🎉')
time.sleep(1)
saving_is_success.empty()
submit_button_holder.empty()
start_over_info_holder = st.empty()
start_over_info_holder.error(body='To rerun the script, click on the "Start over" button, or refresh the page.')
if start_over_button:
comparison_results_header.empty()
start_over_button_holder.empty()
start_over_info_holder.empty()
if SAVE_OPTION and not comparison_results:
comparison_results_header.empty()
no_data_holder = st.empty()
no_data_holder.error(body='No product found. Click "Start Over" button and try different search query.')
if start_over_button:
no_data_holder.empty()
start_over_button_holder.empty()
if SAVE_OPTION is None and comparison_results:
start_over_info_holder = st.empty()
start_over_info_holder.error(body='To rerun the script, click on the "Start over" button, or refresh the page.')
if start_over_button:
comparison_results_header.empty()
start_over_button_holder.empty()
start_over_info_holder.empty()
if SAVE_OPTION is None and not comparison_results:
comparison_results_header.empty()
no_data_holder = st.empty()
no_data_holder.error(body='No product found. Click "Start Over" button and try different search query.')
if start_over_button:
comparison_results_header.empty()
no_data_holder.empty()
start_over_button_holder.empty()
if __name__ == '__main__':
main()
Code Explanation
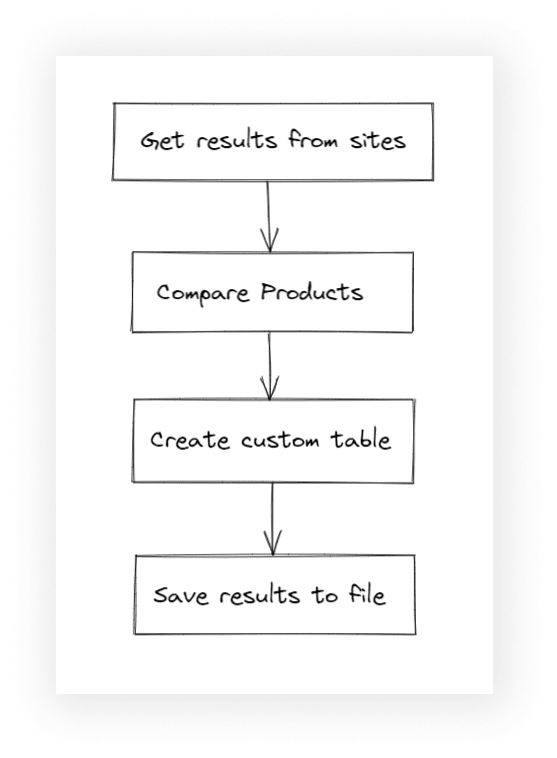
First, let's look at how the algorithm works. The items in this algorithm are functions that will be described in the respective headings:
Import libraries:
from serpapi import EbaySearch, WalmartSearch
import streamlit as st
import streamlit.components.v1 as components
import pandas as pd
import time, os, Levenshtein
| Library | Purpose |
|---|---|
serpapi |
SerpApi's Python API wrapper that parses data from 15+ search engines. |
streamlit |
to create beautiful web apps. |
streamlit.components.v1 |
to find complex or just not available components by default on streamlit. |
pandas |
to convert data to file format. |
time |
to work with time in Python. |
os |
to read secret environment variable. In this case it's SerpApi API key. |
Levenshtein |
to quickly calculate string similarity. |
After a bunch of imports, we define a main function where everything happens. At the beginning of this function, the title and description of the application were added:
def main():
st.title('💸Product Comparison')
st.markdown(body='This demo compares products from Walmart and eBay to find a profit. SerpApi Demo Project ([repository](https://github.com/chukhraiartur/dropshipping-tool-demo)). Made with [Streamlit](https://streamlit.io/) and [SerpApi](http://serpapi.com/) 🧡')
Next is to define streamlit session state. I've used this to hide or unhide certain widgets:
if 'visibility' not in st.session_state:
st.session_state.visibility = 'visible'
st.session_state.disabled = False
After that, I defined an input field, two sliders and two select boxes:
SEARCH_QUERY: str = st.text_input(
label='Search query',
placeholder='Search',
help='Multiple search queries is not supported.'
)
WHERE_TO_SELL = st.selectbox(
label='Where to sell',
options=('Walmart', 'eBay'),
help='Select the platform where you want to sell products. The program will look for the same products on another site and calculate the profit.'
)
NUMBER_OF_PRODUCTS: int = st.slider(
label='Number of products to search',
min_value=1,
max_value=20,
value=10,
help='Limit the number of products to analyze.'
)
PERCENTAGE_OF_UNIQUENESS: int = st.slider(
label='Percentage of uniqueness',
min_value=1,
max_value=100,
value=50,
help='The percentage of uniqueness is used to compare how similar one title is to another. The higher this parameter, the more accurate the result.'
)
SAVE_OPTION = st.selectbox(
label='Choose file format to save',
options=(None, 'JSON', 'CSV'),
help='By default data won\'t be saved. Choose JSON or CSV format if you want to save the results.'
)
Here I was creating a centered button:
col1, col2, col3, col4, col5 = st.columns(5)
with col3:
submit_button_holder = st.empty()
submit_search = submit_button_holder.button(label='Compare products')
if submit_search and not SEARCH_QUERY:
st.error(body='Looks like you click a button without a search query. Please enter a search query 👆')
st.stop()
-
submit_button_holderis used to hide or unhide widget. -
st.stopis used to stop the script if user didn't provide any search query.
If the user enters a search query, a place to sell and clicks the "Compare Products" button, then the function for comparing products is launched. Depending on the place to sale, different functions are triggered, but they are similar:
if submit_search and SEARCH_QUERY and WHERE_TO_SELL:
with st.spinner(text='Parsing Product Data...'):
comparison_results = []
if WHERE_TO_SELL == 'Walmart':
comparison_results = compare_walmart_with_ebay(SEARCH_QUERY, NUMBER_OF_PRODUCTS, PERCENTAGE_OF_UNIQUENESS/100)
elif WHERE_TO_SELL == 'eBay':
comparison_results = compare_ebay_with_walmart(SEARCH_QUERY, NUMBER_OF_PRODUCTS, PERCENTAGE_OF_UNIQUENESS/100)
parsing_is_success = st.success('Done parsing 🎉')
time.sleep(1)
parsing_is_success.empty()
submit_button_holder.empty()
If matches were found, then the results must be shown. The standard streamlit table is not suitable for my purposes, so I am creating a custom table:
comparison_results_header = st.markdown(body='#### Comparison results')
if comparison_results:
table = create_table(comparison_results, WHERE_TO_SELL)
To display the table, I used the components.html() method. In addition to the passed table, this method accepts the height of the rendered content. The table height value depends on the number of matches found multiplied by the height of each table row len(comparison_results)*62 plus the table header height value 40. Thus, the entire table is successfully displayed:
components.html(table, height=len(comparison_results)*62 + 40)
After the data has been displayed, the "Compare Products" button changes to the "Start over" button:
with col3:
start_over_button_holder = st.empty()
start_over_button = st.button(label='Start over')
Then I check the save option and comparison results for their presence:
if SAVE_OPTION and comparison_results:
with st.spinner(text=f'Saving data to {SAVE_OPTION}...'):
if SAVE_OPTION == 'JSON':
save_to_json(comparison_results)
elif SAVE_OPTION == 'CSV':
save_to_csv(comparison_results)
saving_is_success = st.success('Done saving 🎉')
time.sleep(1)
saving_is_success.empty()
submit_button_holder.empty()
start_over_info_holder = st.empty()
start_over_info_holder.error(body='To rerun the script, click on the "Start over" button, or refresh the page.')
if start_over_button:
comparison_results_header.empty()
start_over_button_holder.empty()
start_over_info_holder.empty()
if SAVE_OPTION and not comparison_results:
comparison_results_header.empty()
no_data_holder = st.empty()
no_data_holder.error(body='No product found. Click "Start Over" button and try different search query.')
if start_over_button:
no_data_holder.empty()
start_over_button_holder.empty()
if SAVE_OPTION is None and comparison_results:
start_over_info_holder = st.empty()
start_over_info_holder.error(body='To rerun the script, click on the "Start over" button, or refresh the page.')
if start_over_button:
comparison_results_header.empty()
start_over_button_holder.empty()
start_over_info_holder.empty()
if SAVE_OPTION is None and not comparison_results:
comparison_results_header.empty()
no_data_holder = st.empty()
no_data_holder.error(body='No product found. Click "Start Over" button and try different search query.')
if start_over_button:
comparison_results_header.empty()
no_data_holder.empty()
start_over_button_holder.empty()
You may have noticed that in each of the checks there is an additional check for the "Start Over" button. This is necessary to remove unnecessary information for a new comparison.
In the end I've added a if __name__ == '__main__' idiom which protects users from accidentally invoking the script when they didn't intend to, and call the main function which will run the whole script:
if __name__ == '__main__':
main()
Get results from sites
In this application, data is retrieved from Walmart and eBay. I will analyze how the function for extracting data from Walmart works. The function for extracting data from eBay works in a similar way.
The parameters are defined for generating the URL:
def get_walmart_results(query: str):
params = {
'api_key': os.getenv('SERPAPI_API_KEY'), # https://serpapi.com/manage-api-key
'engine': 'walmart', # search engine
'query': query, # search query
}
| Parameters | Explanation |
|---|---|
api_key |
Parameter defines the SerpApi private key to use. You can find it under your account -> API key |
engine |
Set parameter to walmart to use the Walmart API engine. |
query |
Parameter defines the search query. You can use anything that you would use in a regular Walmart search. |
Then, we create a search object where the data is retrieved from the SerpApi backend. In the results dictionary we get data from JSON:
search = WalmartSearch(params) # data extraction on the SerpApi backend
results = search.get_dict() # JSON -> Python dict
At the end of the function, you need to return information about the products. If no such products were found, then an empty list is returned:
return results.get('organic_results', [])
Compare products
If the user has chosen Walmart as a place to sell, then the function of comparing Walmart with eBay is launched. Also works in reverse.
At the beginning of the function, a list is declared to which data will be added:
def compare_walmart_with_ebay(query: str, number_of_products: int, percentage_of_uniqueness: float):
data = []
For a search query, we get results from Walmart. After that, for each product name from Walmart, we get results from eBay:
walmart_results = get_walmart_results(query)
for walmart_result in walmart_results[:number_of_products]:
ebay_results = get_ebay_results(walmart_result['title'])
Every item from Walmart is compared to every match found on eBay. Comparison of goods is implemented through the title. To get how much one string is similar to another string, I used the Levenshtein.ratio() method. If the percentage of text matching in titles is less than the percentage of uniqueness, then go to the next product:
for ebay_result in ebay_results:
if Levenshtein.ratio(walmart_result['title'], ebay_result['title']) < percentage_of_uniqueness:
continue
If a match is found, the Walmart and eBay price of that item is retrieved. Then profit is calculated:
walmart_price = walmart_result.get('primary_offer', {}).get('offer_price')
ebay_price = ebay_result.get('price', {}).get('extracted')
if not ebay_price:
ebay_price = ebay_result.get('price', {}).get('from', {}).get('extracted')
profit = 0
if walmart_price and ebay_price:
profit = round(walmart_price - ebay_price, 2)
The data about the found match is added to the list:
data.append({
'Walmart': {
'thumbnail': walmart_result['thumbnail'],
'title': walmart_result['title'],
'link': walmart_result['product_page_url'],
'price': walmart_price
},
'eBay': {
'thumbnail': ebay_result['thumbnail'],
'title': ebay_result['title'],
'link': ebay_result['link'],
'price': ebay_price
},
'Profit': profit
})
At the end of the function, a list of all matches is returned:
return data
Create custom table
This function generates a table based on the passed data.
At the beginning of the function, the style sheet for the table is included:
def create_table(data: list, where_to_sell: str):
with open('table_style.css') as file:
style = file.read()
Next, each row of the table is formed. The first column will contain data about the place of sale selected by the user. Also, the color of the text in the profit will change depending on the value:
products = ''
for product in data:
profit_color = 'lime' if product['Profit'] >= 0 else 'red'
if where_to_sell == 'Walmart':
products += f'''
<tr>
<td><div><img src="{product['Walmart']['thumbnail']}" width="50"></div></td>
<td><div><a href="{product['Walmart']['link']}" target="_blank">{product['Walmart']['title']}</div></td>
<td><div>{str(product['Walmart']['price'])}$</div></td>
<td><div><img src="{product['eBay']['thumbnail']}" width="50"></div></td>
<td><div><a href="{product['eBay']['link']}" target="_blank">{product['eBay']['title']}</div></td>
<td><div>{str(product['eBay']['price'])}$</div></td>
<td><div style="color:{profit_color}">{str(product['Profit'])}$</div></td>
</tr>
'''
elif where_to_sell == 'eBay':
products += f'''
<tr>
<td><div><img src="{product['eBay']['thumbnail']}" width="50"></div></td>
<td><div><a href="{product['eBay']['link']}" target="_blank">{product['eBay']['title']}</div></td>
<td><div>{str(product['eBay']['price'])}$</div></td>
<td><div><img src="{product['Walmart']['thumbnail']}" width="50"></div></td>
<td><div><a href="{product['Walmart']['link']}" target="_blank">{product['Walmart']['title']}</div></td>
<td><div>{str(product['Walmart']['price'])}$</div></td>
<td><div style="color:{profit_color}">{str(product['Profit'])}$</div></td>
</tr>
'''
Now the table structure is formed, after which it is returned by this function:
table = f'''
<style>
{style}
</style>
<table border="1">
<thead>
<tr>
<th colspan="3"><div>{list(data[0].keys())[0]}</div></th>
<th colspan="3"><div>{list(data[0].keys())[1]}</div></th>
<th><div>{list(data[0].keys())[2]}</div></th>
</tr>
</thead>
<tbody>{products}</tbody>
</table>
'''
return table
Save results to file
This function converts a list of matches into data corresponding to a JSON or CSV format.
To convert data to JSON format, you need to create a DataFrame object based on the passed data, and then call the to_json() method. The st.download_button() method is used to create a download button:
def save_to_json(data: list):
json_file = pd.DataFrame(data=data).to_json(index=False, orient='table')
st.download_button(
label='Download JSON',
file_name='comparison-results.json',
mime='application/json',
data=json_file,
)
The process of converting data to CSV format is different in that you need to use the to_csv() method.
def save_to_csv(data: list):
csv_file = pd.DataFrame(data=data).to_csv(index=False)
st.download_button(
label="Download CSV",
file_name='comparison-results.csv',
mime='text/csv',
data=csv_file
)

Top comments (6)
Can we also find suppliers with that program? Because niche research is not an issue for me. But finding best clothing suppliers for dropshipping is difficult part. And all suppliers scam people.
At the moment there is no such possibility. But you got me interested. If it's not difficult for you, you can make an issue and I'll get to work soon.
Hey 👋, I hope am not getting you pssed off.
Actually Am Jementis from NewYork city
I wanted to ask, How's your online dropshipping store doing currently, Any Progree with massive sale on your store ?
I also had same issue while I was getting started also, instead of making use of various suppliers which seem to be scam instead partner with a supplier well know company CJ Suppliers company
That was the company the expert who helped me in getting started which my dropshipping store partnered with and I have been working with them couple of months now
PROBABLY DO YOU KNOW ABOUT CJ suppliers company?
Some comments may only be visible to logged-in visitors. Sign in to view all comments.