
In the previous articles, I introduce you to two different tools to perform web scraping with Java. HtmlUnit in the first article, and PhantomJS in the article about handling Javascript heavy website.
This time we are going to introduce a new feature from Chrome, the headless mode. There was a rumor going around, that Google used a special version of Chrome for their crawling needs. I don't know if this is true, but Google launched the headless mode for Chrome with Chrome 59 several months ago.
PhantomJS was the leader in this space, it was (and still is) heavy used for browser automation and testing. After hearing the news about Headless Chrome, the PhantomJS maintainer said that he was stepping down as maintainer because of I quote "Google Chrome is faster and more stable than PhantomJS [...]"
It looks like Chrome headless is becoming the way to go when it comes to browser automation and dealing with Javascript-heavy websites.
HtmlUnit, PhantomJS, and the other headless browsers are very useful tools, the problem is they are not as stable as Chrome, and sometimes you will encounter Javascript errors that would not have happened with Chrome.
Prerequisites
- Google Chrome > 59
- Chromedriver
- Selenium
- In your pom.xml add a recent version of Selenium :
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-java</artifactId>
<version>3.8.1</version>
</dependency>
If you don't have Google Chrome installed, you can download it here
To install Chromedriver you can use brew on MacOS :
brew install chromedriver
Or download it using the link below.
There are a lot of versions, I suggest you to use the last version of Chrome and chromedriver.
Let's log into Hacker News
In this part, we are going to log into Hacker News, and take a screenshot once logged in. We don't need Chrome headless for this task, but the goal of this article is only to show you how to run headless Chrome with Selenium.
The first thing we have to do is to create a WebDriver object, and set the chromedriver path and some arguments :
// Init chromedriver
String chromeDriverPath = "/Path/To/Chromedriver" ;
System.setProperty("webdriver.chrome.driver", chromeDriverPath);
ChromeOptions options = new ChromeOptions();
options.addArguments("--headless", "--disable-gpu", "--window-size=1920,1200","--ignore-certificate-errors");
WebDriver driver = new ChromeDriver(options);
The
option is needed on Windows systems, according to the [documentation](https://developers.google.com/web/updates/2017/04/headless-chrome)
Chromedriver should automatically find the Google Chrome executable path, if you have a special installation, or if you want to use a different version of Chrome, you can do it with :
```java
options.setBinary("/Path/to/specific/version/of/Google Chrome");
If you want to learn more about the different options, here is the Chromedriver documentation
The next step is to perform a GET request to the Hacker News login form, select the username and password field, fill it with our credentials and click on the login button. Then we have to check for a credential error, and if we are logged in, we can take a screenshot.
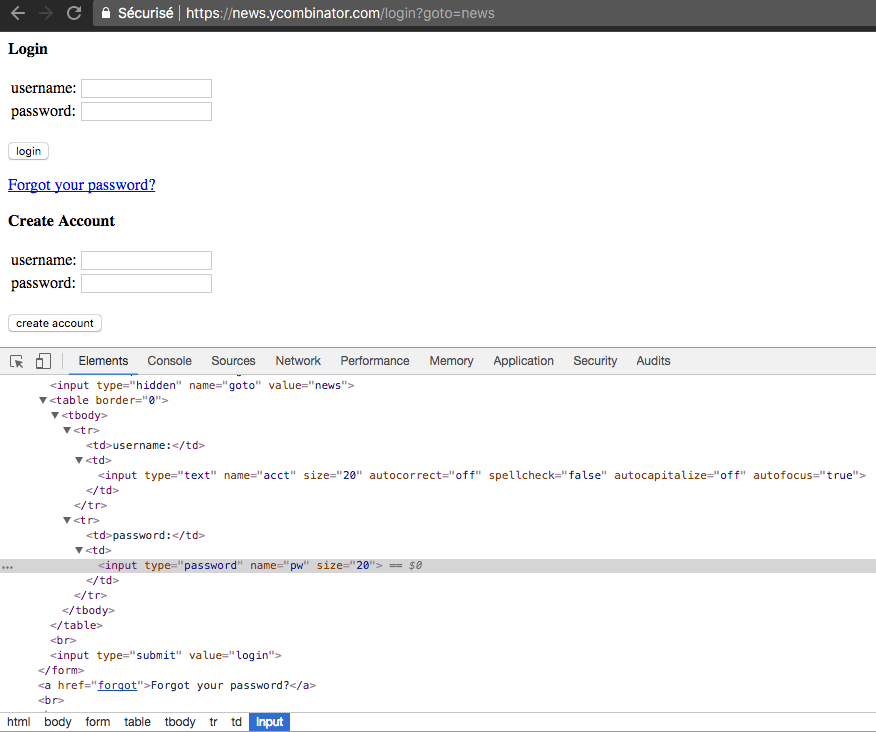
We have done this in a previous article, here is the full code :
public class ChromeHeadlessTest {
private static String userName = "" ;
private static String password = "" ;
public static void main(String[] args) throws IOException{
String chromeDriverPath = "/your/chromedriver/path" ;
System.setProperty("webdriver.chrome.driver", chromeDriverPath);
ChromeOptions options = new ChromeOptions();
options.addArguments("--headless", "--disable-gpu", "--window-size=1920,1200","--ignore-certificate-errors", "--silent");
WebDriver driver = new ChromeDriver(options);
// Get the login page
driver.get("https://news.ycombinator.com/login?goto=news");
// Search for username / password input and fill the inputs
driver.findElement(By.xpath("//input[@name='acct']")).sendKeys(userName);
driver.findElement(By.xpath("//input[@type='password']")).sendKeys(password);
// Locate the login button and click on it
driver.findElement(By.xpath("//input[@value='login']")).click();
if(driver.getCurrentUrl().equals("https://news.ycombinator.com/login")){
System.out.println("Incorrect credentials");
driver.quit();
System.exit(1);
}else{
System.out.println("Successfuly logged in");
}
// Take a screenshot of the current page
File screenshot = ((TakesScreenshot) driver).getScreenshotAs(OutputType.FILE);
FileUtils.copyFile(screenshot, new File("screenshot.png"));
// Logout
driver.findElement(By.id("logout")).click();
driver.quit();
}
}
You should now have a nice screenshot of the Hacker News homepage while being authenticated. As you can see Chrome headless is really easy to use, it is not that different from PhantomJS since we are using Selenium to run it.
If you enjoyed this do not hesitate to subscribe to our newsletter!
If you like web scraping and are tired taking care of proxies, JS rendering and captchas, you can check our new web scraping API, the first 1000 API calls are on us.
As usual, the code is available in this Github repository

Top comments (0)