It is common for a system to have multiple processes. For example, you can list all processes in the system by running the ps aux command.
$ ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND ...(1)
...
sat 19261 0.0 0.0 13840 5360 ? S 18:24 0:00 sshd: sat@pts/0
sat 19262 0.0 0.0 12120 5232 pts/0 Ss 18:24 0:00 -bash
...
sat 19280 0.0 0.0 12752 3692 pts/0 R+ 18:25 0:00 ps aux
$
The line (1) is the header line that indicates the meaning of the output in the following lines, and after that, one process is displayed per line. Among them, the COMMAND field represents the command name. We won't go into detail here, but you can see that the sshd ssh server (PID=19261) started bash (PID=19262), which then executed ps aux.
You can remove the header line of the ps command output by using the --no-header option. Now let's check the number of processes in my environment.
$ ps aux --no-header | wc -l
216
$
There were 216 processes. What are each of these processes doing? How are they managed? In this chapter, we will explain the process management system that Linux uses to manage these processes.
Process Creation
There are two main purposes for creating new processes:
- a. Divide the processing of the same program into multiple processes (e.g., handling multiple requests by a web server).
- b. Generate a different program (e.g., creating various programs from
bash).
To achieve these, Linux uses the fork() function and the execve() function1. Internally, they call the clone() and execve() system calls, respectively. For the case a, only the fork() function is used, while for the case b, both the fork() function and the execve() function are used.
The fork() function that splits the same process into two
When the fork() function is issued, a copy of the process that issued it is made, and both the original and the copy return from the fork() function. The original process is called the parent process, and the generated process is called the child process. The flow at this time is as follows:
- The parent process calls the
fork()function. - Allocate memory space for the child process and copy the parent process's memory into it.
- Both the parent and child processes return from the
fork()function. Since the return values of thefork()function differ for the parent.

However, in reality, the memory copy from the parent process to the child process is done at a very low cost thanks to a feature called Copy-on-Write, which will be explained in the following chapter. As a result, the overhead of dividing the processing of the same program into multiple processes in Linux is small.
Let's take a look at how the fork() function generates processes by creating the following python.py program with the following specifications:
#!/usr/bin/python3
import os, sys
ret = os.fork()
if ret == 0:
print("child process: pid={}, parent process's pid={}".format(os.getpid(), os.getppid()))
exit()
elif ret > 0:
print("parent process: pid={}, child process's pid={}".format(os.getpid(), ret))
exit()
sys.exit(1)
- Call the
fork()function to branch the process flow. - The parent process outputs its own process ID and the child process's process ID and then exits. The child process outputs its own process ID and then exits.
In the fork.py program, when returning from the fork() function, the parent process gets the child process's process ID, while the child process gets 0. Since the pid is always 1 or more, this can be used to branch the processing after the fork() function call in the parent and child processes.
Now, let's try running it.
./fork.py
parent process: pid=132767, child process's pid=132768
child process: pid=132768, parent peocess's pid=132767
You can see that a process with process ID 132767 has branched and created a new process with process ID 132768, and that after issuing the fork() function, the processing branches according to the return value of fork().
The fork() function can be quite difficult to understand at first, but please try to master it by repeatedly reading the content and sample code in this section.
The execve() function for launching a different program
After creating a copy of the process with the fork() function, the execve() function is called on the child process. As a result, the child process is replaced with another program. The flow of processing is as follows:
- Call the
execve()function. - Read the program specified in the arguments of the
execve()function, and read the information required to place the program in memory (called "memory mapping"). - Overwrite the current process's memory with the new process's data.
- Start executing the process from the first instruction to be executed in the new process (the entry point).
In other words, while the fork() function increases the number of processes, when creating an entirely different program, the number of processes does not increase; instead, one process is replaced with another.

To express this in a program, it would look like following fork-and-exec.py program. Here, after the fork() function call, the child process is replaced with the echo <pid> Hello from <pid> command by the execve() function.
#!/usr/bin/python3
import os, sys
ret = os.fork()
if ret == 0:
print("child process: pid={}, parent process's pid={}".format(os.getpid(), os.getppid()))
os.execve("/bin/echo", ["echo", "hello from pid={} ".format(os.getpid())], {})
exit()
elif ret > 0:
print("parent process: pid={}, child process's pid={}".format(os.getpid(), ret))
exit()
sys.exit(1)
The result of the execution looks like this:
```console
$ ./fork-and-exec.py
parent process: pid=5843, child process's pid=5844
child process: pid=5844, parent process's pid=5843
hello from pid=5844
If we illustrate this result, it would look like the following figure. For simplicity, we omit the loading of the program by the kernel and copying the program to memory.
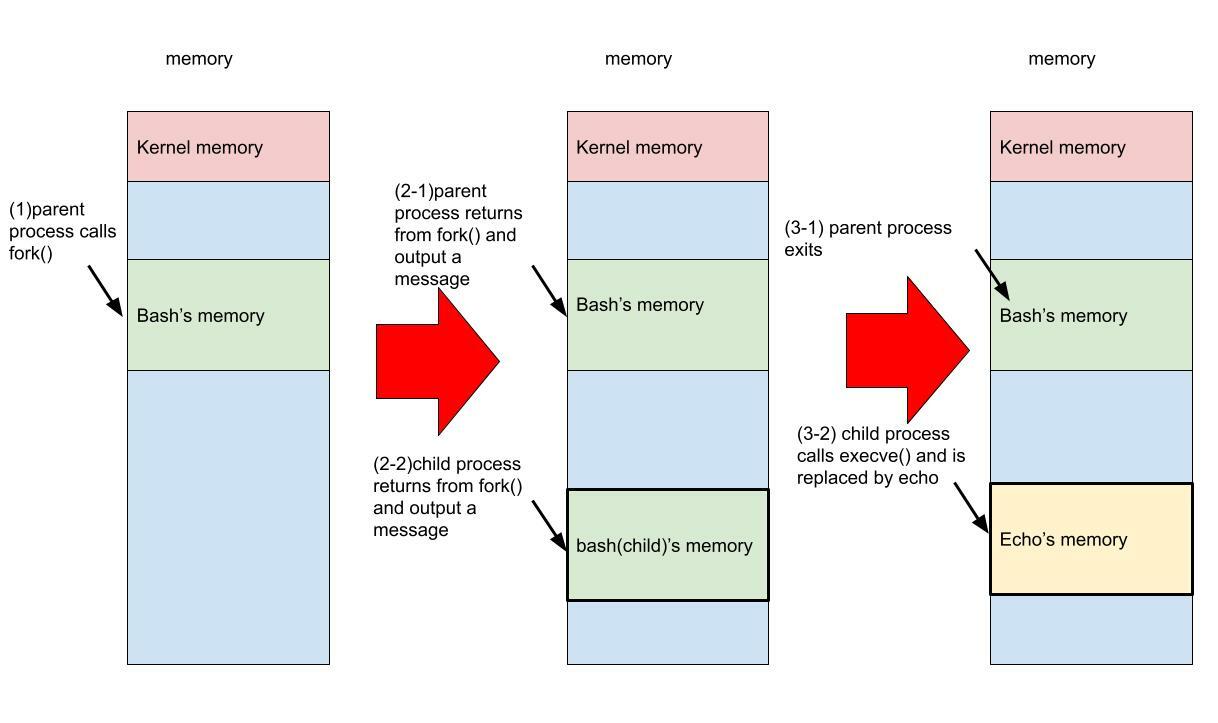
To implement the `execve()` function, the executable file holds the necessary data for starting the program in addition to the program code and data. This data includes:
- The file offset, size, and memory map starting address of the code area.
- The same information for the data area.
- The memory address of the first instruction to execute (entry point).
Now let's take a look at how Linux executable files hold this information. Linux executable files are usually in the Executable and Linking Format (ELF) format. Various information about ELF can be obtained using the `readelf` command.
We will use the `pause` program again here, which we used in the following chapter. Let's start with the build.
```c
#include <unistd.h>
int main(void) {
pause();
return 0;
}
$ cc -o pause -no-pie pause.c # build pause program with -no-pie option. See the next column to know the meaning of this option
The program's starting address can be obtained using readelf -h.
$ readelf -h pause
...
Entry point address: 0x400400
...
"0x400400" on the "Entry point address" line is the entry point of this program.
The file offset, size, and starting address of the code and data can be obtained using the readelf -S command.
$ readelf -S pause
There are 29 section headers, starting at offset 0x18e8:
Section Headers:
[Nr] Name Type Address Offset
Size EntSize Flags Link Info Align
...
[13] .text PROGBITS 0000000000400400 00000400
0000000000000172 0000000000000000 AX 0 0 16
...
[23] .data PROGBITS 0000000000601020 00001020
0000000000000010 0000000000000000 WA 0 0 8
...
Although we obtained a large amount of output, understanding the following points is sufficient:
- The executable file is divided into multiple regions, each of which is called a section.
- Information about each section is displayed as a pair of two lines.
- All values are in hexadecimal.
- The main information about each section is as follows:
- Section name: the second field "Name" in the first line
- Memory map starting address: the fourth field "Address" in the first line
- File offset: the fifth field "Offset" in the first line
- Size: the first field "Size" in the second line
- Sections with the name ".text" are code sections, and those with the name ".data" are data sections.
Summarizing this information, see the following table.
| Name | Value |
|---|---|
| File offset of the code | 0x400 |
| Size of the code | 0x172 |
| Memory map starting address of the code | 0x400400 |
| File offset of the data | 0x1020 |
| Size of the data | 0x10 |
| Memory map starting address of the data | 0x601020 |
| Entry point | 0x400400 |
The memory map of the process created from the program can be obtained using the /proc/<pid>/maps file. Now let's take a look at the memory map of the pause command.
$ ./pause &
[3] 12492
$ cat /proc/12492/maps
00400000-00401000 r-xp 00000000 08:02 788371 .../pause ... (1)
00600000-00601000 r--p 00000000 08:02 788371 .../pause
00601000-00602000 rw-p 00001000 08:02 788371 .../pause ... (2)
...
(1) is the code region, and (2) is the data region. We can see that they fit within the memory map ranges shown in the above-mentioned table.
Once you have finished with this, let's exit the pause process.
$ kill 12492
Security enhancement with Address Space Layout Randomization feature
In this section, we explain the meaning of the -no-pie option attached during the build of the pause program in the previous section. This option is related to a security feature called Address Space Layout Randomization (ASLR) that the Linux kernel has. ASLR is a feature that maps each section of a program to a different address every time it is executed. Thanks to this, attacks that assume the target code or data exists at a specific address become difficult.
The conditions for using this feature are as follows:
- The ASLR function of the kernel is enabled. It is enabled by default in Ubuntu 20.042.
- The program supports ASLR. Such programs are called Position Independent Executable (PIE).
gcc (in this book's example, the cc command) in Ubuntu 20.04 builds all programs as PIE by default, but PIE can be disabled with the -no-pie option. In the previous section, we set it up intentionally because if the PIE of the pause command is not disabled, it causes confusion due to reasons such as the values in /proc/<pid>/maps not being the same as those written in the executable file and being different every time it is executed.
Whether a program is PIE or not can be checked with the file command. If it is supported, the following output is obtained:
$ file pause
pause: ELF 64-bit LSB shared object, ...
$
If it is not PIE, the following output is obtained:
$ file pause
pause: ELF 64-bit LSB executable, ...
$
For reference, let's run the pause program built without the -no-pie option twice and check where the code section is mapped to memory each time.
$ cc -o pause pause.c
$ ./pause &
[5] 15406
$ cat /proc/15406/maps
559c5778f000-559c57790000 r-xp 00000000 08:02 788372 .../pause
...
$ ./pause &
[6] 15536
$ cat /proc/15536/maps
5568d2506000-5568d2507000 r-xp 00000000 08:02 788372 .../pause
...
$ kill 15406 15536
As you can see, it is mapped to different locations on the first and second runs.
Actually, programs distributed as part of Ubuntu 20.04 are PIE as much as possible. It's wonderful that security is enhanced automatically without users or programmers being particularly aware of it. However, there are also security attacks to bypass ASLR, so the history of security technology is a game of cat and mouse.
Column: Process Generation Methods Other Than fork() and execve()
Using fork() and execve() functions in sequence to create a program from within a process may seem redundant. In such cases, the posix_spawn() function defined in the C language interface specification for UNIX-based operating systems, POSIX, can simplify the process.
Below is a program named spawn.py that generates an echo command as a child process using the posix_spawn() function:
#!/usr/bin/python3
import os
os.posix_spawn("/bin/echo", ["echo", "echo", "created by posix_spawn()"], {})
print("created echo command")
$ ./spawn.py
created echo command
created by posix_spawn()
This is achieved using fork() and execve() functions in spawn-by-fork-and-exec.py program , as shown below:
#!/usr/bin/python3
import os
ret = os.fork()
if ret == 0:
os.execve("/bin/echo", ["echo", "created by fork() and execve()"], {})
elif ret > 0:
print("created echo")
$ ./spawn-by-fork-and-exec.py
created echo
created by fork() and execve()
As you can see, the spawn program has better source code readability.
Although process generation using posix_spawn() is intuitive, it may become unnecessarily complex if more sophisticated operations such as shell implementations are desired, compared to using the fork() and execve() functions. For reference, I uses the posix_spawn() function only when calling the execve() function immediately after the fork() function without performing any other operations. Otherwise, I uses fork() and execve() functions for all cases.
NOTE
This article is based on my book written in Japanese. Please contact me via satoru.takeuchi@gmail.com if you're interested in publishing this book's English version.

Top comments (0)