Overview
In the last article in my Extract Transform and Load (ETL) series, Submission Information Packages and High-level Validation, I covered the most important part of this process: the data. The data format will drive 80 percent of the design decisions for the ETL pipeline. In this article, I introduce the concept of Canonical Transformation in this context as a way to create a reusable and easy to maintain pipeline.
The term canonical may be new to most readers, so what is it?
"Authoritative or standard; conforming to an accepted rule or procedure. When referring to programming, canonical means conforming to well-established patterns or rules."
—Webopedia
In essence, it is a set of common objects that can be manipulated, submitted, and used by various components. In the context of an ETL pipeline, the canonical allows multiple data types and endpoints to converge into a set of objects that allows a common set of downstream processing logic to be applied. The consistency of downstream processing allows an enterprise to create, maintain, and monitor a single set of business rules, identification criteria, and persistence logic. The benefits of implementing the Canonical Transformation are
- Reduction in maintenance
- Easy business logic changes
- Data monitoring
- Quality control
- Decoupling the database from the data formats and endpoints
- Decoupling pipeline components
The main factors when designing the Canonical Transformation step are the canonical objects and mapping routines.
Canonical Objects
Most canonical objects are unremarkable. They are data holders. However, determining the canonical design can be difficult, particularly if there are multiple data formats. The key is to start with some good questions to guide the design.
- What are the system’s submission input formats? (See the last article)
- What is the database design?
- Will the system need to disseminate data? If so what format and how?
- How will data be indexed for search?
- What are the systems business rules?
Most likely the first question will drive the canonical design and will be the only question covered in this article. As is often the case, the most complex or detailed input format will influence most of the canonical design. Often, these formats have been designed by a consortium of experts and data partners. These are people with domain knowledge and a good understanding of the data, so typically they know how to represent it. In other words, it is the industry-standard format. Also, it is typically easy to map simple data to a more complex format than it is to map complex data to a simpler format.
Often times when working with an industry-standard format, the schemas are complex enough to handle edge cases that most consumers will not use or need. This is why some companies design simpler formats in CSV or use a UI to service smaller data partners (See submission Input). When a simpler format is created, data structures are reduced or an array will be simplified to a single item or limited to a certain number of items. When going from simple to complex, the decision to keep data is simple. However, when going from complex to simple, a decision to truncate data needs to be made. In the case where there is no data structure, the decision may be to not map it, but if many objects (array) are converted to a single field, the question of which item should be kept needs to be answered.
Pruning the Canonical Bush

Simply creating the canonical based on the industry-standard may work, but this approach may leave the system with a messy canonical and could require pruning. The first thing to ask in such a case is: “Do I have a business case for the data being truncated?” If the business owners/domain experts agree that the data is not needed for the system's purpose, then it is okay to remove the fields from the canonical. It is important to make it clear to business owners that re-ingesting the data may be difficult, time-consuming, or in some case impossible at a later date.
Another case for pruning the canonical is unused structures. In more verbose standards, metadata envelopes or communication sequence histories are specified. These data structures typical hold data about the transaction and that data is often transient. These are good candidates for pruning. It is important to note that if the system requires a high level of data provenance and auditing, then this data may need to to be kept.
Poorly designed standards
In some cases, the industry-standard may be poorly designed. An example of this is when a data structure is overly abstracted. This typically happens when there are various types of the same data structure. For example, a digital media standard may represent video, music, podcast, and e-books. The standard may abstract all these digital media types into a structured called work. However, a video may contain fields that an e-book wouldn’t have and vice versa. If the structure was design correctly with correct sub-type inheritance this may not be an issue. However, if the design tries to collect all the different types into the abstract work object, there could be confusing on the standard. In these scenarios, there are two approaches.
- Leave the abstract data structure as is and write business rules to validate each type. This would be done if the system is designed to inform submitters of any violations in their data.
- Boil down the data structures into concrete types. In this case, the system is deliberately truncating data that does not make sense for the type. The one issue with this approach is that data partners may not completely understand the data standard or may conflate the meaning of two different data fields. Using the above example, a book may have an author and music may have a composer. These words have very similar meanings and a data partner may populate the composer field for a book’s author.
Once the canonical is drafted, ask “does the design accurately represent the domain?” Repeatedly asking this question throughout the design process will help ensure that the canonical stays true the system’s intention.
Mapping Routines
Mapping routines is all about how the raw data gets unmarshalled into the canonical. Often there will be at least one mapping routine per data format.
In some cases there may be multiple routines per data type. This is often seen with industry standards, particularly with more complex standards. When a standard has been around for a while, data partners will have their own way to fill them out, using some data fields, not populating others, and using nodes in different ways. In these cases, most of the data can be mapped by the parser/mapper, but will require different sub-routines to map the differences.
Another multiple-routines-for-the-same-format scenario occurs when there are multiple versions of the same industry format. In both these scenarios a factory pattern can be used to determine the routine via submitter and version. Then simple inheritance can handle submitter specific mappings.
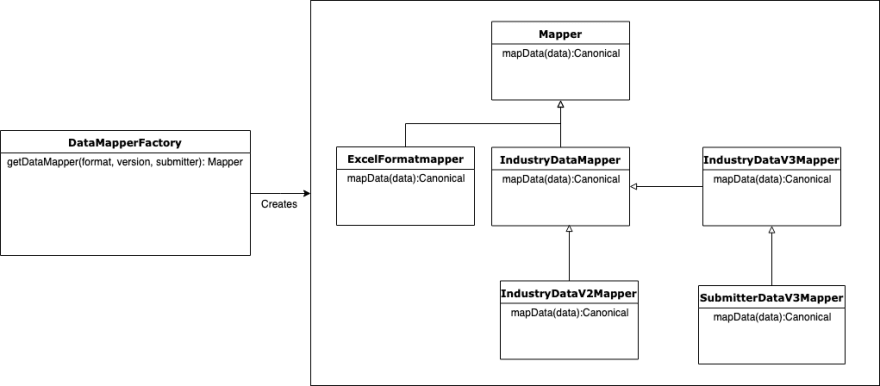
Breaking out the mapping routines per format, version, and data partner decouples the logic for easy blackbox testing. Raw data goes in and the expected canonical comes out.
Summary
The most important step for making an ETL pipeline reusable and easy to maintain is the canonical step. A well designed canonical will decouple the raw data from the system’s business logic and internal working, allowing the code to be reused and reduce duplication. The next article in the Extract Transform and Load Series will address business rules.
Ten Mile Square has expert consultants and engineers that have a proven track record to learn new domains, analyze requirements, and design the perfect canonical to mean your business’s needs. Reach out to us if you have any questions. We love to help.

Top comments (0)