Hello all, this blog will provide you with an insight into handling Null values using Python programming language.
Download the pre-processed and final Datasets, python code (.ipynb file) from the following links:-
https://www.kaggle.com/datasets/ruthvikrajamv/home-insurance-dataset
https://github.com/ruthvikraja/Python-Code-on-Home-Insurance-Dataset.git
This project uses the home insurance dataset from Stable Home Insurance company, and data were collected from 2007 to 2012 for residential house sales. This dataset contains 66 data measurements containing various information from each of 256,136 insurance clients. To properly extract information from the dataset, some transformations need to be made to clean the data for analysis. An important step in this process is checking the data for null values. These values occur when a particular measurement does not apply to a client and can cause issues when building computer models to analyse the data. For example, a client who does not provide their personal information would contain null values for these information columns in the dataset. To ensure the data models run smoothly, I need to either remove data points with null values or replace these Null values with a valid proxy.
It is not sufficient to simply drop all the rows that consist of Null values, so I implemented different techniques to remove the Null values without losing information. In the stable home insurance data set, there are a few features which contain little information, as they are missing more than 98% of the data. These columns – CAMPAIGN DESC, P1 PT EMP STATUS and CLERICAL were all removed from the data set. After these columns were removed, I performed some further cleaning by removing all the rows which contain information about less than half of the features. These data points represent clients that the company has very little information about and thus will not be useful for analysis.
Additionally, further data processing was performed on the columns like QUOTE DATE, RISK RATED AREA B, RISK RATED AREA C, PAYMENT FREQUENCY, MTA FAP, MTA FAP & MTA DATE as these columns contain many Null values of different proportions. Features like MTA FAP, MTA APRP and MTA DATE were removed for having above 70% Null values. Features containing this high proportion of null values can be removed without losing important information. The PAYMENT FREQUENCY feature consisted of 57% Null values and contained only one unique value for the entire column so I dropped the column since it doesn’t contribute to the response variables of the analysis. QUOTE DATE was also dropped for having 58% Null values. The remaining columns with Null values were RISK RATED AREA C and RISK RATED AREA B. For these columns, there was enough information present to impute the Null values. Imputation is the process whereby Null values are replaced with a value based on the information present in the dataset. Mean Imputation is the process of replacing Null values with the mean of the remaining data points. This technique is appropriate in situations where there are few missing data points and thus was used for RISK RATED AREA C.
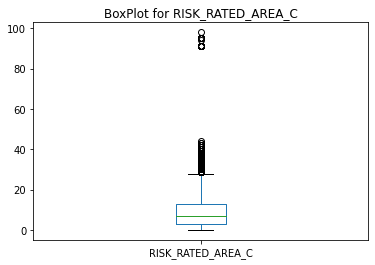
The above Figure illustrates the Box plot for the feature RISK RATED AREA C and it is clear that this feature contains many outliers. Initially, I treated it using different methodologies and finally imputed the Null values with the mean value. For the feature RISK RATED AREA B, more of the data was missing, so I implemented the K Nearest Neighbors (KNN) Imputer, which is a more appropriate technique for this amount of missing data. This process involves using the value of the most similar point as determined by the nearest neighbour (k). The input values were initially scaled using MinMax Scaler and then the data was sent to the algorithm to make unbiased predictions. The final dataset consists of 189021 rows & 57 features.



Latest comments (0)