
Let's understand how Reinforcement Learning works through a simple example. Let's play a game called The Frozen Lake. Suppose you were playing frisbee with your friends in a park during winter. One of you threw the frisbee so far that it has dropped in a frozen lake. Your mission is to walk over the frozen lake to get the frisbee back, but taking caution to not fall in a hole of freezing water.

We could easily create a bot that always wins this game by writing a simple algorithm giving the right directions to reach the frisbee. But that's not challenging or fun at all. Instead, we want to create an agent that can learn the path to the frisbee while playing the game multiples times.
In the reinforcement learning paradigm, the learning process is a loop in which the agent reads the state of the environment and then executes an action. Then the environment returns its new state and a reward signal, indicating if the action was correct or not. The process continues until the environment reaches a terminal state or if a maximum number of iterations is executed.
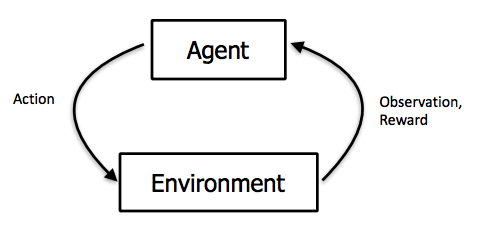
Therefore, the first step to train our agent to play the Frozen Lake game is to model each aspect of the game as components of a reinforcement learning problem.
The Environment
The environment is a representation of the context that our agent will interact with. It can represent an aspect of the real world, like the stock market, or a street for example, or it can be a completely virtual environment, like a game. In either case, the environment defines the states and rewards the agent can receive as well as the possible actions that the agent can execute for each state. In our case, the environment is the Frozen Lake game, which consists of a grid of squares that can be of two types:
- Grey squares, representing a safe thick layer of ice that you can walk over.
- Blue squares, representing holes in the ice.
The hero can move in four directions (up, down, right, left) inside the grid. If you reach the frisbee you win the game, but you lose if you fall into a hole.
State
States are observations that the agent receives from the environment. It's the way the agent receives all available information about the environment. In our example, the state of the game is simply the position of the character in the grid, which will be represented by a pair of coordinates (i, j).
Actions
Actions are performed by the agent and may change the state of the environment. All the rules of how an action changes the state of the environment are internal to the environment. For a given state, the agent can choose which will be its next action, but it does not have any control over how this action will affect the environment. For the Frozen Lake example, the available actions to the agent are the four directions to which our hero can move: up, right, down and left.
Rewards
Rewards signal to the agent if an action was correct or not. In our example, the environment returns +1 when the hero reaches the frisbee or -1 if the hero falls into a hole. Every other cases are considered neutral, so the environment returns 0 (zero).
The Gameplay
The game starts with the hero at the position (0, 0). From this state, there are two possible actions, moving right or moving down. If the agent chooses to move to the right, then the new state will be (0, 1) and the agent will receive a reward of 0 (zero) because it's a neutral play. From the position (0, 1) there are three possible moves: left, right and down. Supposing the agent chooses to move down, then the new state will be the position (1, 1). However, this position is a hole in the ice, which means the agent lost the game. So the agent receives an -1 penalty and the game is over. This sequence is shown at the table below:
| **Current state** | **Action** | **Next State** | **Reward** | **Game over?** |
| (0, 0) | ➡️ | (0, 1) | 0 | No |
| (0, 1) | ⬇️ | (1, 1) | -1 | Yes |
Another possible sequence from the state (0, 1) is the hero moves to the right and reaches the state (0, 2). From there, the hero keeps moving until it reaches the position (3, 2) and finally it moves to the left, reaching the frisbee at the position (3, 3) and receiving a +1 reward.
| **Current state** | **Action** | **Next State** | **Reward** | **Game over?** |
| (0, 0) | ➡️ | (0, 1) | 0 | No |
| (0, 1) | ➡️ | (0, 2) | 0 | No |
| (0, 2) | ⬇️ | (1, 2) | 0 | No |
| (1, 2) | ⬇️ | (2, 2) | 0 | No |
| (2, 2) | ⬇️ | (3, 2) | 0 | No |
| (3, 2) | ➡️ | (3, 3) | +1 | Yes |
Conclusion
Using a simple example, we learned the fundamental concepts of the reinforcement learning paradigm. Every time we want to apply the reinforcement learning approach to solve a problem, we always have to delimit the environment, identify states, possible actions and set the appropriate rewards.





Top comments (2)
Good article, thanks.
Thank you