I published an article about LakeSoul, the data lakehouse, a few months ago. https://dev.to/qazmkop/design-concept-of-a-best-opensource-project-about-big-data-and-data-lakehouse-24o2
Recently, LakeSoul has been updated and iterated with more perfect functions, which can adapt to various scenarios and coordinate with business landings.
The DMetaSoul team released LakeSoul 2.0 in early July, which has been upgraded and optimized in many ways to improve the flexibility of its architectural design and better adapt to customers' needs for future rapid business development.
Main objectives of LakeSoul 2.0 development upgrade:
- Support multiple computing engines (Flink, Presto, etc.), refactoring Catalog, and decouple Spark;
- Use Postgres SQL protocol to support more demanding transactional mechanism and replace Cassandra SQL, reducing the cost of Cassandra cluster management for enterprises;
- Supports more functions in service production, such as version snapshot, rollback, and Hive interconnection.
- Strengthen ecosystem construction and improve upstream and downstream link design; DMetaSoul achieved the design goal through Catalog reconstruction, Spark and Catalog docking transformation, development of new user features, and support for the Flink computing engine. Following are the features of LakeSoul 2.0.
1.Catalog refactoring
1.1 Supports Postgres SQL protocol
In LakeSoul 2.0, metadata and database interaction are fully implemented using the Postgres SQL (PG) protocol for reasons mentioned at https://github.com/meta-soul/LakeSoul/issues/23. On the one hand, Cassandra does not support single-table multi-partition transactions. On the other hand, Cassandra cluster management has higher maintenance costs, while the Postgres SQL protocol is widely used in enterprises and has lower maintenance costs. You need to configure PG parameters. For details, click https://github.com/meta-soul/LakeSoul/wiki/02.-QuickStart
1.2 Independent Catalog framework
In LakeSoul 2.0, the Catalog is decoupled from Spark to realize an independent metadata storage structure and interface. Spark, Flink, Presto, and other computing engines can interconnect with LakeSoul to provide multi-engine streaming and batch integration capability.
1.3 The mechanism for detecting data submission conflicts
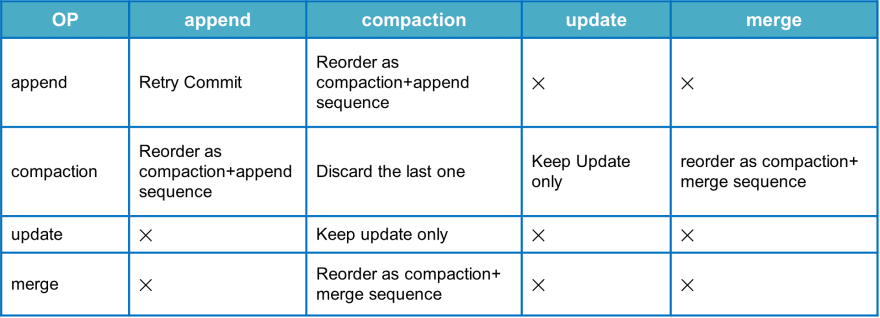
Multiple tasks simultaneously writing data to the same table may cause data consistency problems in the same partition. To solve this problem, LakeSoul categorizes data commit types by defining four types: Append, Compaction, Update, and Merge, so that when committing two commit types together, the collision detection determines whether the commit succeeds or fails (X) and what happens when the commit succeeds. For example, if users must commit append data simultaneously to perform two tasks, repeat the submission of the conflicting task when a conflict is detected.
2.Connect Spark to Catalog and transform it
After refactoring, decouple from Spark. Since most of the original Spark functions are affected by decoupling, it is necessary to transform the three parts based on the Catalog design framework.
2.1 Spark DDL
DDL (such as CREATE and drop table) and DataSet-related functions (such as save) in Spark SQL interact closely with the Catalog. The information about the created table is stored in the Catalog. LakeSoul retuned the Spark Scala interface to align it with Catalog.
2.2 Spark DataSink
The DataSink (insert into, upsert, etc.) involves not only metadata information (such as tables) but also data file record and partition data conflict detection when the stream batch task writes data. DMetaSoul also adjusted the data operation interface after the Spark Job was completed. Partitioning data commit conflict detection is also moved down to the Catalog.
2.3 Spark DataSource
Merge On Read (MOR) iS optimized On the DataSource. In version 1.0, data reads are sorted according to the write version number of data files. When merging, the latest version overwrites data of the old version by default. In LakeSoul 2.0, the Write Version attribute for data files was removed instead of using an ordered list of files, with the latest build file at the end of the list.
In LakeSoul 1.0, users using other MergeOperators provided by LakeSoul, such as MergeOpLong, needed to register and specify the associated column names when reading.
LakeSoulTable.registerMergeOperator(spark, "org.apache.spark.sql.lakesoul.MergeOpLong", "longMOp")
LakeSoulTable.forPath("tablepath").toDF.withColumn("value", expr("longMOp(value)")) .select("hash", "value")
If the table needs to use a large number of column fields or even all the fields, it is inconvenient to specify one by one, and if the user does not specify, LakeSoul uses DefaultMergeOp for all the fields by default.
For example, https://github.com/meta-soul/LakeSoul/issues/30, the user expected MergeNonNullOp to be used for all fields by default, which was not met in version 1.0. In LakeSoul 2.0, LakeSoul implemented modifications to the default MergeOprator operation.
spark-shell --conf defaultMergeOpInfo="org.apache.spark.sql.execution.datasources.v2.merge.parquet.batch.merge_operator.DefaultMergeOp"
3.New service features
In LakeSoul 2.0, three new features address the business requirements in the real world.
3.1 the snapshot
Snapshots provide users with the ability to view historical data. In LakeSoul, when the user performs upsert, Update, insert, and other operations, the corresponding partition will generate a data version. As the data continues to be updated, the historical version will increase, and the user hopes to check the historical data to facilitate data comparison, etc. https://github.com/meta-soul/LakeSoul/issues/41. LakeSoul 2.0 allows users to view a version number by partition snapshot.
LakeSoulTable.forPath("tablepath","range=rangeval",2).toDF.show()
3.2 the rollback
Rollback allows the user to take a historical version of the data as the current data, enabling the data to go back in time. LakeSoul 2.0 also provides the ability to roll back data to a historical version by partition,
https://github.com/meta-soul/LakeSoul/issues/42.
LakeSoulTable.forPath("tablepath").rollbackPartition("range=rangeval",2)
3.3 Support Hive
Many enterprises choose Hive as an offline data warehouse in the financial and Internet sectors. In version 2.0, LakeSoul considers the uniformity of the upstream computing engine and the diversity of the downstream data output. Hive is the data warehouse tool that supports LakeSoul downstream first.
It would help if users created a hive appearance by putting a new Compaction file in the Spark conf directory. When this Compaction happens, it compacts this operation with a new Compaction file that does not support Merge On Read. Only Copy On Write is supported.
LakeSoulTable.forPath("tablepath").compaction("range=rangeval","hiveExternalTableName")
3.4 Support Flink
LakeSoul 2.0 supports Flink unified streaming and batch writing and implements Exactly-once semantics. It can ensure data accuracy for Flink CDC and other scenarios and combine Merge On Read and Schema AutoMerge capabilities provided by LakeSoul 2.0, which has high commercial value for practical business scenarios such as multi-table mergers and sub-database mergers.
Conclusion
LakeSoul2.0 (https://github.com/meta-soul/LakeSoul/releases/tag/v2.0.0-spark-3.1.2) version surrounding ecological system upgrade the further iterations, pay attention to the upstream and downstream tools seamless ecological docking, It also focuses on relevant features in enterprise business applications.




Top comments (0)