MetaSpre:https://github.com/meta-soul/MetaSpore
AlphaIDE:https://registry-alphaide.dmetasoul.com/login
After decades of development, the traditional credit evaluation model for risk management is relatively mature and stable. Represented by the FICO score in the United States, it builds a rule engine and promotes the rapid development of the financial loan business in the United States. In recent years, with the leapfrog development of big data and artificial intelligence technologies, financial institutions can draw diversified user portraits and build more accurate risk control models under the support of new technologies.
This paper will take the Tianchi loan default data set as an example, train and evaluate the default prediction model in MetaSpore on the AlphaIDE development environment launched by DMetaSoul , and give intelligent credit score according to the estimated probability. In the following chapters, I will focus on environmental use, problem modeling, feature derivation, modeling, score cards, and so on.
2.MetaSpore On AlphaIDE
2.1 IDE environment configuration and startup
Register or log in AlphaIDE account: https://registry-alphaide.dmetasoul.com/. Enter the AlphaIDE service, click application service on the left, click Kubeflow drop-down menu, and enter the Jupyter page.

Click on the upper right to create the Notebook and select the desired resource under CPU/RAM. It is recommended to use 2Core CPU X 8GB or more of RAM:

Check Kubeflow, AWS, and Spark, and then Launch to create the Notebook.

After creating the Juyper Notebook, click Connect to open a Terminal and run:
git clone git@github.com:meta-soul/MetaSpore.git
Run the algorithm Demo and develop it after the completion of the clone code base
2.2 Training machine learning models
See the algorithms project in MetaSpore's Demo directory for recommendations, search, NLP, and risk control-related applications. Here take the risk control project (Demo/RiskModels/Loan_default /) as an example:
1. Star the Spark Session: If using Spark in the Alpha IDE distributed cluster training, you need to increase the Spark. Kubernetes. Namespace configuration parameters, such as:
def init_spark(app_name, cluster_namespace, ..., **kwargs):
spark = pyspark.sql.SparkSession.builder\
.appName(app_name) \
.config("spark.kubernetes.namespace", cluster_namespace)
...
.getOrCreate()
sc = spark.sparkContext
print(sc.version)
print(sc.applicationId)
print(sc.uiWebUrl)
return spark
Of course, you can also run in local mode by changing the fourth line above to master("local"). When the number of samples is small, the local mode is better.
2. Start the model training script: follow the steps in the readme.md document to prepare the training data, initialize the model configuration file we need and then execute the training script.
3. Save the model training results: Save the trained model and estimated results to S3 cloud storage as we did in default_ESTIMation_spark_lgbm.py.
It may take some time to download the dependent libraries during the first execution.
3.Intelligent risk control algorithm
3.1 Background
Before diving into the actual code implementation, let's take a quick look at the data set. The data set given by the Tianchi community is used in this article. The data set is to predict whether the user defaults on loans. The data comes from the loan records of A credit platform, with A total of over 1.2 million data, including 47 columns of variable information, 15 unknown variables, 200,000 pieces as the test set A, and 200,000 pieces as test set B. "isDefault" in the dataset can be used as the training label. Other columns can be used as the model's features, including ID, category, and numerical features. The complete introduction of feature columns can refer to the description of the dataset provided by the government, and the following figure shows the sample data:

The so-called default rate prediction is to use the machine learning model to establish the learner of binary classification, that is, through the model to estimate:
![]()
When the risk control algorithm is implemented, the model's accuracy and interpretability should be considered simultaneously. The linear model and tree model are generally used. The following examples are also based on the LightGBM model.
Based on the default rate prediction model, we can establish a user's credit score, similar to the sesame credit score of Ant Group. Generally speaking, the lower the default probability is, the higher our score should be, which is convenient for loan personnel to evaluate customers.
3.2 Feature Engineering
The evaluation problems related to financial loans are mainly based on tabular data, so the importance of feature engineering is self-evident. The common features in the dataset include ID type, Categorical type, and continuous number type, which require common data handling such as EDA, missing value completion, outlier processing, normalization, feature binning, and importance assessment.
The process can reference the GitHub codebase: https://github.com/meta-soul/MetaSpore/blob/main/demo/dataset, which part about tianchi_loan instructions.
WoE Weight of Evidence coding is required for feature derivation for risk control models, especially for standard risk control scorecards. WoE represents the difference in the proportion of good and bad customers in the current feature binning, smoothed by the log function and calculated by the following formula:
![]()
Among them,
py, pn respectively represent the percentage of good or bad customers in the total good or bad customers in this binning;
Badi, Badt respectively represent the number of bad customers in the current binning and the number of bad customers in all customers;
Goodi, Goodt respectively represent the number of good customers in the current binning and the number of good users in all customers;
If the larger the absolute value of WoE is, the more significant the difference is, the feature binning is a perfect predictor. On the other hand, If WoE is 0, then the ratio of good and bad customers is equal to the percentage of random bad and good customers. In this case, WoE has no predictive power.
The calculation process: https://github.com/meta-soul/MetaSpore/tree/main/demo/dataset/tianchi_loan/woe.ipynb
In actual business scenarios, a lot of work will focus on feature binning and filtering. The commonly used methods in the process of feature binning include isofrequency, isometric, Best-KS, ChiMerge, and other methods. In the process of feature screening, the chi-square test, wrapper based on tree-model, and IV, Information Value, based on WoE are the common methods. However, these tasks require a lot of data analysis and iteration for specific businesses.
3.3 Model training
Once the samples and features are ready, we can train the model. Here we use the Spark version of the LightGBM model, which is both model performance and interpretable, and compatible with AlphaIDE and MetaSpore Serving. Model training code:

Another advantage of using the Spark version of the machine learning model is that it can fully use cluster computing resources during hyperparameter optimization. To demonstrate, use Hyperopt to optimize the combination of learningRate and numIterations as two super parameters. Define the optimization space of the hyperparameters as follows:

After the train_with_HYPERopt function is defined, optimize the parameter combination. The optimization process is slow. When finish the execution, best_params can be output to view the best parameter combination:

In practical business, hyperparameter optimization will have more space and consume more computing time. After the hyperparameter optimization is completed, the model can be trained again on the full sample set. After the training, we can export the model to ONNX format. For details, please refer to the introduction in [2,3] or the export code given in our GitHub code repository: https://github.com/meta-soul/MetaSpore/blob/main/demo/riskmodels/loan_default/default_estimation_spark_lgbm.py
3.4 Model evaluation
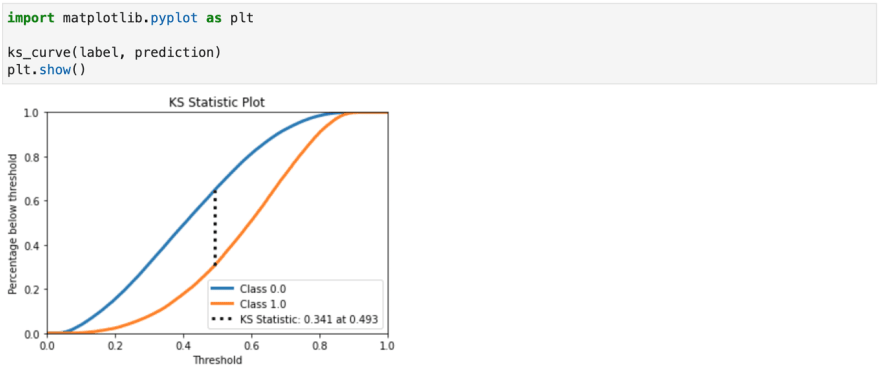
In addition to the commonly used AUC index to evaluate the performance of the risk control algorithm model, the Kolmogorov-Smirnov index is another measure. The higher the KS index is, the stronger the risk differentiation ability of the model is. The business significance of the KS curve is that we allow the model to make a small number of errors in exchange for maximizing the identification of bad samples. In general:
KS<0.2, the differentiation ability of the model is not high, and the application value is not high;
0.2<=KS<0.4, general models are concentrated in this interval, so it is necessary to continue to observe the tuning model;
0.4<=KS<0.7. The model has good differentiation ability and strong application value;
KS<=0.7, there may be a fitting phenomenon that needs to be checked.
We provide a KS value calculation and KS drawing toolbox in MetaSpore. After we write the test results into S3 cloud storage, we can call the functions in the toolbox to evaluate the model:

3.5 Credit Score
Assuming that we have reasonably estimated the loan default rate through the machine learning model, we can give the following score:
![]()
If the following two assumptions are satisfied, then we can derive the calculation formula of constants A and B:
**A. Initial value hypothesis: **The score is assumed at S0, i.e.
![]()
B. Point of Double assumption: Assume that odds0=2×oddso, a fixed PDO score reduces the credit score:
![]()
The formula for calculating A and B:

Here is the result of the scorecard operation. The results showed that the lower the probability of default, the higher the credit score.

Refer to the GitHub repository for code implementation: https://github.com/meta-soul/MetaSpore/tree/main/demo/riskmodels/loan_default/notebooks/credit_scorecard.ipynb
The results of the score can also be evaluated using the KS indicator. In addition, it should be noted that to implement a standard scorecard is to be implemented, a linear model, usually Logistic Regression, is required. Besides a credit score for each user, the linear model's intercept and the binning of each one-dimensional feature need to be scored.
Conclusion
DMetaSoul uses MetaSpore on AlphaIDE to quickly implement a loan default rate prediction model on an open-source dataset and build a scorecard based on this model. Based on the Demo system of this version, the methods of feature derivation, binning, and screening can be more delicate, which often determines the upper limit of the performance of the risk control system. Finally, give the address of the code base and the AlphaIDE trial link (AlphaIDE tutorial):
Default rate forecast: https://github.com/meta-soul/MetaSpore/tree/main/demo/riskmodels/loan_default
MetaSpore's one-stop machine learning development platform: https://github.com/meta-soul/MetaSpore
AlphaIDE trial link: https://registry-alphaide.dmetasoul.com

Top comments (0)