Mongodb Clustered Collection is a relatively new feature released in MongoDB 5.3 that could improve query performance!
What you will read in this article
- How does MongoDB fetch documents in a collection
- How does Mongodb fetch documents in a clustered collection
- Limitation
- Playing with Clustered and Normal Collection
- When to use Clustered Collection
How does MongoDB fetch documents in a normal collection?
Here we want to discuss how MongoDB fetches documents using indexes. If there is no index MongoDB has to fetch all documents in a process called COLLSCAN if you look at the query explainer. COLLSCAN fetches all documents of a collection from the disk and then starts doing your desired operation. Here we focus on what happens when you are using an index.
Imagine you are using _id which is indexed(by default) and you want to fetch one document. Here is what happens:
Find the _id in the MongoDB BPlus Tree
Indexes in MongoDB are stored in a BPlus Tree. If you do not know what is a BPlus Tree it is similar to a BTree with two major differences:
1- Values are at leaves.
2- Leaves have pointer to the next one(which makes it fast for range queries)
This is a simple BTree consisting of these numbers: (1,2,3,4,5,6,9,10)
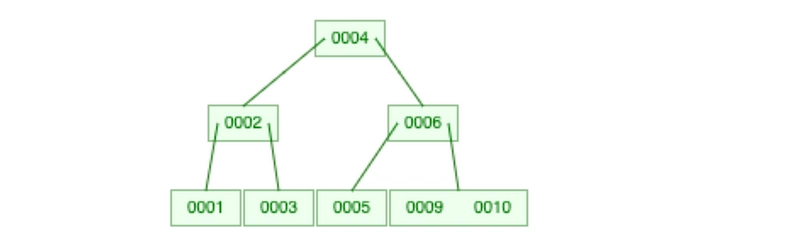
BTree consisting 1,2,3,4,5,6,9,10
This is on the other hand a B+Tree consisting of the same numbers
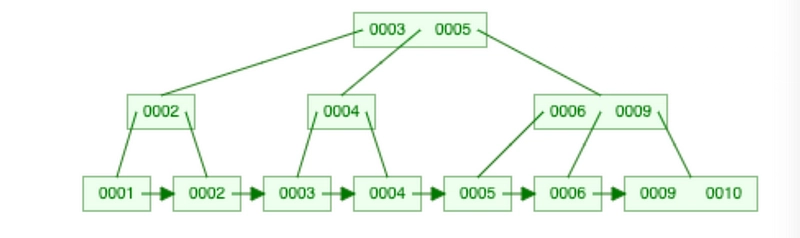
B+Tree consisting 1,2,3,4,5,6,9,10
MongoDB stores indexes in B+ Tree so when we are running this query:
db.users.findOne({ _id: ObjectID("...") });
The first thing MongoDB does is it goes to this B+ Tree and finds the _id.
Now it got the Leaf. But the important thing is that your document is not the value of this Leaf.
the value is another thing called RecordID. MongoDB has a hidden clustered index which is another B+ Tree that you can find the document by using RecordID. You have to traverse the tree once again and you have your document.
So the summary of what happens with this simple search query:
1- Traverse the B+ Tree and find the Leaf regarding _id or any indexed field you have
2- Get RecordID from the Leaf.
3- Traverse the hidden clustered index for RecordID
4- Get the document from Value of RecordID
How does Mongodb fetch documents in a clustered collection?
In a clustered collection you do not have a RecordID anymore!
You need to traverse the B+ Tree only once and you have the document!
As simple as that. We should be careful with this since we know everything comes at a cost.
Cost of using Clustered Documents
In a normal collection you only had RecordID, as a result when we added more indexes we do not see that many changes in the size of the collection. But now if we add more indexes we see big changes. If you do not add more indexes the size of the clustered collection is smaller than the normal collection because we do not have this RecordID.
Limitations
By default, if a secondary index exists on
a clustered collection and the secondary index is usable by your
query, the secondary index is selected instead of the clustered
index.
You can use clustered index only on _id field!
You cannot convert a normal collection to a clustered collection or vice versa.
Playing with Clustered and Normal Collection
I want to create two collections on MongoDB Atlas and run some queries on them:
For creating a clustered collection we can use the UI and easily choose the clustered collection:
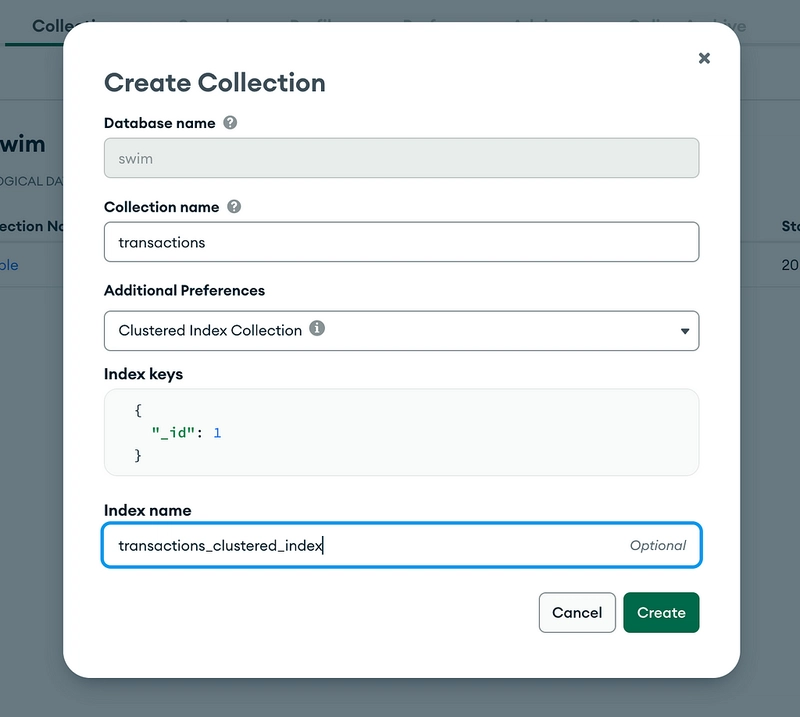
Create a Clustered Collection
Also, let’s create a normal collection:
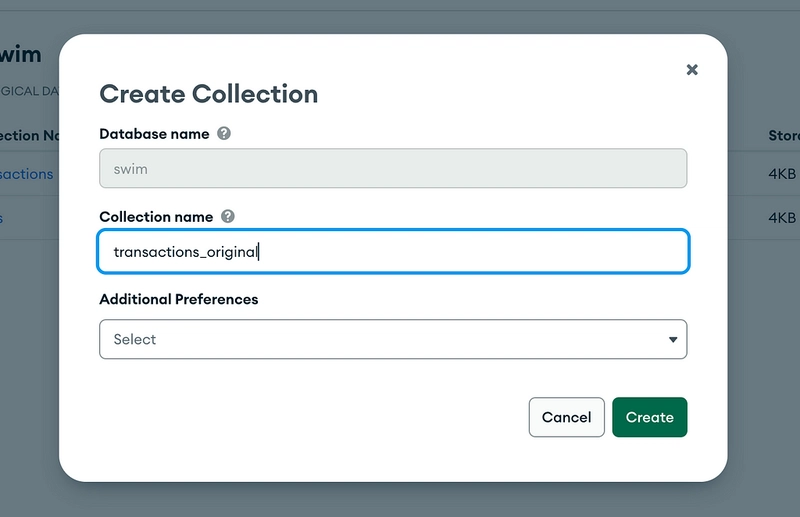
Normal Collection
Now if we run a findOne({ _id: “”}) we can see the difference in explain query.
The first one is for transactions_original which uses the _id index and chooses IDHACK(the name of the plan when we use _id to find a document)
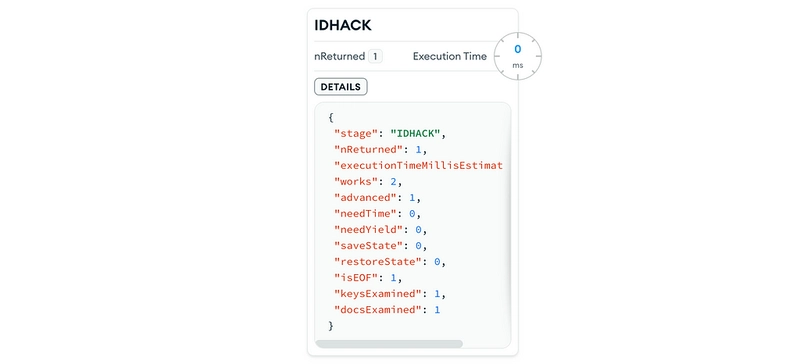
IDHACK
For the clustered collection we can see that the query plan selected was CLUSTERED_IXSCAN

CLUSTERED_IXSCAN
Let’s also see the difference in the size of the index for 100k documents:

Clustered Index Size

Normal Index Size
Let’s perform some queries on a new collection called products. Our usage is that we fetch products that have better ratings(mostly range queries).
Then we put 1 million products. For comparison, we create also products_original . In order to use clustered index we put rating of product into _id of products .
For products_original this is the schema and the query we want to perform:
// products_original
{
_id: ObjectID("..."),
rating: number => index(-1),
name: string
}
Query = db.collection.find({ rating: { $gte: 0.9 } })
// products_clustered
{
_id: clusteredIndex(we put rating into this field),
productId: uuidv4(),
name: string,
}
Query = db.collection.find({ _id: { $gte: 0.9 } })
Then I created 1M products and for making the comparison fair I used the same ratings for these 1M products. The data in both collections is the same. This is not a benchmark that you can rely on but the result and query explain data might give you some idea that when it is worth using.
Result of the range query in the Clustered Collection
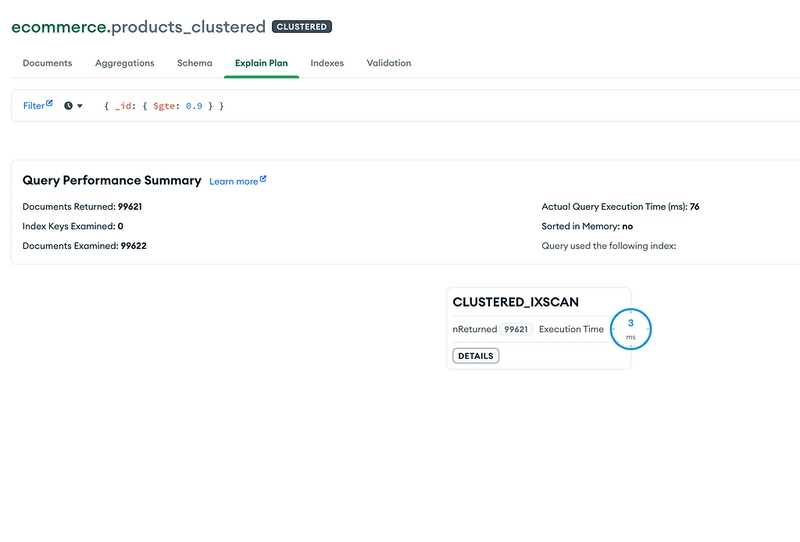
Range Query Using Clustered Index
Result of the range query in the Normal Collection
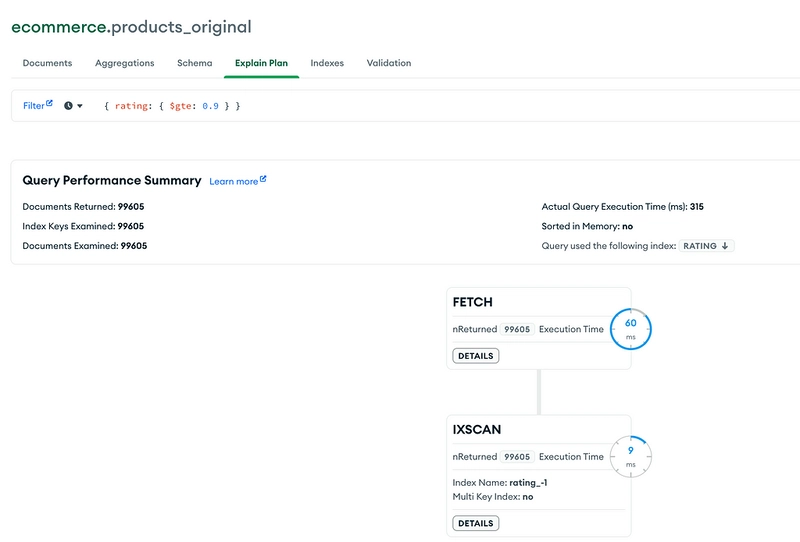
Range Query Result in Normal Collection
In normal collection one apparently expensive step was Fetch! Because for each _id we have to look up the RecordID and then get the documents.
When to use Clustered Collection
There is not a special description for this in the documentation but based on the list of benefits we can summarize that like this:
- Queries with range scans and equality comparisons on the clustered index key
- Faster bulk insert
https://www.youtube.com/watch?v=OhJ3xcjtpis&ab_channel=HusseinNasser
Level Up Coding
Thanks for being a part of our community! Before you go:
- 👏 Clap for the story and follow the author 👉
- 📰 View more content in the Level Up Coding publication
- 💰 Free coding interview course ⇒ View Course
- 🔔 Follow us: Twitter | LinkedIn | Newsletter
🚀👉 Join the Level Up talent collective and find an amazing job

Top comments (0)